
配置和管理网络在 Red Hat Enterprise Linux 8 中配置和管理网络的指南使开源包含更多对红帽文档提供反馈第 1 章 一般 RHEL 网络主题1.1. IP 网络和非 IP 网络之间的区别1.2. 静态和动态 IP 地址之间的区别1.3. DHCP 事务阶段Discovery(发现)Offer(提供)Request(请求)Acknowledgment(承认)1.4. InfiniBand 和 RDMA 网络1.5. RHEL 中旧版网络脚本支持1.6. 选择网络配置方法第 2 章 一致的网络接口设备命名2.1. 网络接口设备命名等级2.2. 网络设备重命名如何工作2.3. x86_64 平台上的可预测的网络接口名称解释2.4. System z 平台中可预测的网络接口设备名称解释2.5. 在安装过程中禁用一致的接口设备命名2.6. 在安装的系统中禁用一致的接口设备命名2.7. 使用 prefixdevname 命名以太网网络接口2.7.1. prefixdevname 简介2.7.2. prefixdevname 的限制2.7.3. 设置 prefixdevname2.8. 相关信息第 3 章 使用 netconsole 通过网络记录内核信息3.1. 配置 netconsole 服务为将内核信息记录到远程主机第 4 章 systemd 网络目标和服务4.1. network 和 network-online systemd target 的不同4.2. NetworkManager-wait-online 概述4.3. 将 systemd 服务配置为在网络已启动后再启动第 5 章 NetworkManager 入门5.1. 使用 NetworkManager 的好处5.2. 您可以用来管理 NetworkManager 连接的工具和应用程序概述5.3. 使用 NetworkManager 分配程序脚本5.4. 将手动创建的 ifcfg 文件加载到 NetworkManager 中第 6 章 配置 NetworkManager 以忽略某些设备6.1. 永久将设备配置为网络管理器(NetworkManager)中非受管设备6.2. 将设备临时配置为在 NetworkManager 中不被管理第 7 章 Linux 流量控制7.1. 排队规则概述classful qdiscs无类别 qdiscs7.2. RHEL 中可用的 qdiscs7.3. 检查 qdisc 计数器7.4. 更新默认的 qdisc7.5. 更新当前的 qdisc第 8 章 nmtui 入门8.1. 启动 nmtui 工具8.2. 使用 nmtui 添加连接配置集8.3. 使用 nmtui 对修改的连接应用更改第 9 章 nmcli 入门9.1. nmcli 输出格式的不同9.2. 在 nmcli 中使用 tab 自动完成9.3. 频繁使用的 nmcli 命令第 10 章 使用 GNOME GUI 配置网络入门10.1. 使用 GNOME Shell 网络连接图标进行网络连接第 11 章 配置以太网连接11.1. 使用 nmcli 配置静态以太网连接11.2. 使用 nmcli 互动编辑器配置静态以太网连接11.3. 使用 RHEL 系统角色配置静态以太网连接11.4. 使用 nmcli 配置动态以太网连接11.5. 使用 nmcli 互动编辑器配置动态以太网连接11.6. 使用 RHEL 系统角色配置动态以太网连接11.7. 使用 control-center 配置以太网连接11.8. 使用 nm-connection-editor 配置以太网连接11.9. 配置网络管理器连接的 DHCP 行为第 12 章 管理 Wi-Fi 连接12.1. 设置无线规范域12.2. 使用 nmcli 配置 Wi-Fi 连接12.3. 使用 control-center 配置 Wi-Fi 连接12.4. 使用 nmcli 连接到 Wi-Fi 网络12.5. 使用 nmcli 连接到隐藏的 Wi-Fi 网络12.6. 使用 GNOME GUI 连接至 Wi-Fi 网络第 13 章 使用 802.1X 标准向网络验证 RHEL 客户端13.1. 使用 nmcli 在现有以太网连接中配置 802.1X 网络身份验证13.2. 使用 RHEL 系统角色通过 802.1X 网络身份验证配置静态以太网连接13.3. 使用 nmcli 在现有 Wi-Fi 连接中配置 802.1X 网络身份验证第 14 章 设置现有连接的默认网关14.1. 使用 nmcli 在现有连接上设置默认网关14.2. 使用 nmcli 互动模式在现有连接上设置默认网关14.3. 使用 nm-connection-editor 在现有连接上设置默认网关14.4. 使用 control-center 在现有连接上设置默认网关14.5. 使用旧的网络脚本在现有连接中设置默认网关第 15 章 配置静态路由15.1. 如何使用 nmcli 命令配置静态路由15.2. 使用 nmcli 命令配置静态路由15.3. 使用 control-center 配置静态路由15.4. 使用 nm-connection-editor 配置静态路由15.5. 使用 nmcli 互动模式配置静态路由15.6. 使用旧的网络脚本以 key-value-format 创建静态路由配置文件15.7. 在使用旧的网络脚本时,使用 ip-command-format 创建静态路由配置文件第 16 章 配置基于策略的路由以定义其他路由16.1. 使用 NetworkManager 将特定子网的流量路由到不同的默认网关16.2. 使用旧网络脚本时,涉及基于策略的路由的配置文件概述16.3. 使用旧网络脚本将特定子网的流量路由到不同的默认网关第 17 章 配置 VLAN 标记17.1. 使用 nmcli 命令配置 VLAN 标记17.2. 使用 nm-connection-editor 配置 VLAN 标记第 18 章 配置网络桥接18.1. 使用 nmcli 命令配置网络桥接18.2. 使用 nm-connection-editor 配置网络桥接第 19 章 配置网络团队(team)19.1. 了解网络团队19.2. 了解主和从接口的默认行为19.3. 网络团队和绑定功能的比较19.4. 了解 teamd 服务、运行程序和 link-watchers19.5. 安装 teamd 服务19.6. 使用 nmcli 命令配置网络团队19.7. 使用 nm-connection-editor 配置网络团队第 20 章 配置网络绑定20.1. 了解网络绑定20.2. 了解主和从接口的默认行为20.3. 网络团队和绑定功能的比较20.4. 上游交换配置取决于绑定模式20.5. 使用 nmcli 命令配置网络绑定20.6. 使用 nm-connection-editor 配置网络绑定20.7. 创建网络绑定以便在不中断 VPN 的情况下在以太网和无线连接间进行切换第 21 章 使用以太网配置光纤21.1. 在 RHEL 中使用硬件 FCoE HBA21.2. 设置软件 FCoE 设备21.3. 其它资源第 22 章 配置 VPN 连接22.1. 使用 control-center 配置 VPN 连接22.2. 使用 nm-connection-editor 配置 VPN 连接22.3. 相关信息第 23 章 创建 dummy 接口23.1. 使用 nmcli 使用 IPv4 和 IPv6 地址创建 dummy 接口第 24 章 配置 IP 隧道24.1. 使用 nmcli 配置 IPIP 隧道来封装 IPv4 数据包中的 IPv4 流量24.2. 使用 nmcli 配置 GRE 隧道来封装 IPv4 数据包中的层 3 流量24.3. 配置 GRETAP 隧道来通过 IPv4 传输以太网帧24.4. 其它资源第 25 章 多路径 TCP 入门25.1. 准备 RHEL 启用 MPTCP 支持25.2. 使用 iproute2 通知应用程序有关多个可用路径25.3. 在内核中禁用多路径 TCP第 26 章 配置 DNS 服务器顺序26.1. NetworkManager 如何在 /etc/resolv.conf 中对 DNS 服务器进行排序DNS 优先级参数的默认值有效的 DNS 优先级值:26.2. 设置 NetworkManager 范围默认 DNS 服务器优先级值26.3. 设置网络管理器连接的 DNS 优先级第 27 章 使用 ifcfg 文件配置 ip 网络27.1. 使用 ifcfg 文件配置带有静态网络设置的接口27.2. 使用 ifcfg 文件配置带有动态网络设置的接口27.3. 使用 ifcfg 文件管理系统范围以及专用连接配置集第 28 章 使用 NetworkManager 为特定连接禁用 IPv628.1. 使用 nmcli 在连接上禁用 IPv6第 29 章 手动配置 /etc/resolv.conf 文件29.1. 在 NetworkManager 配置中禁用 DNS 处理29.2. 使用符号链接替换 /etc/resolv.conf 来手动配置 DNS 设置第 30 章 配置 802.3 链路设置30.1. 使用 nmcli 工具配置 802.3 链路设置第 31 章 配置 ethtool offload 功能31.1. NetworkManager 支持的卸载功能31.2. 使用 NetworkManager 配置 ethtool offload 功能第 32 章 配置 MACsec32.1. MACsec 简介32.2. 在 nmcli 工具中使用 MACsec32.3. 使用带有 wpa_supplicant 的 MACsec32.4. 相关信息第 33 章 在不同域中使用不同的 DNS 服务器33.1. 将特定域的 DNS 请求发送到所选 DNS 服务器第 34 章 开始使用 IPVLAN34.1. IPVLAN 概述34.2. IPVLAN 模式34.3. MACVLAN 概述34.4. IPVLAN 和 MACVLAN 的比较34.5. 使用 iproute2 创建和配置 IPVLAN 设备第 35 章 配置虚拟路由和转发(VRF)35.1. 在不同接口上永久重复使用相同的 IP 地址35.2. 在不同接口中临时重复使用相同的 IP 地址35.3. 相关信息第 36 章 为您的系统设置路由协议36.1. FRRouting 介绍36.2. 设置 FRRouting36.3. 修改 FRR 的配置启用附加守护进程禁用守护进程36.4. 修改特定守护进程的配置第 37 章 监控并调整 RX 环缓冲37.1. 显示丢弃的数据包数量37.2. 增加 RX 环缓冲以降低数据包丢弃的比率第 38 章 测试基本网络设置38.1. 使用 ping 程序验证 IP 到其他主机的连接38.2. 使用 host 实用程序验证名称解析第 39 章 网络管理器调试介绍39.1. 调试级别和域39.2. 设置 NetworkManager 日志级别39.3. 在运行时使用 nmcli 临时设置日志级别39.4. 查看 NetworkManager 日志第 40 章 捕获网络数据包40.1. 使用 xdpdump 捕获包括 XDP 程序丢弃的数据包在内的网络数据包40.2. 其它资源第 41 章 在 RHEL 中使用特定内核版本41.1. 使用以前的内核版本启动 RHEL第 42 章 提供 DHCP 服务42.1. 对 DHCPv4 和 DHCPv6 使用 dhcpd 时的不同42.2. dhcpd 服务的租期数据库42.3. DHCPv6 和 radvd 的比较42.4. 为 IPv6 路由器配置 radvd 服务42.5. 为 DHCP 服务器设置网络接口42.6. 为直接连接到 DHCP 服务器的子网设置 DHCP 服务42.7. 为没有直接连接到 DHCP 服务器的子网设置 DHCP 服务42.8. 使用 DHCP 为主机分配静态地址42.9. 使用 group 声明同时将参数应用到多个主机、子网和共享网络42.10. 恢复损坏的租期数据库42.11. 设置 DHCP 转发代理第 43 章 使用和配置 firewalld43.1. 使用 firewalld、nftables 或者 iptables 时43.2. 开始使用 firewalld43.2.1. firewalld43.2.2. Zones43.2.3. 预定义的服务43.3. 安装 firewall-config GUI 配置工具43.4. 查看当前状态和设置 firewalld43.4.1. 查看当前状态 firewalld43.4.2. 查看当前的 firewalld 设置43.4.2.1. 使用 GUI 查看允许的服务43.4.2.2. 使用 CLI 查看 firewalld 设置43.5. 启动 firewalld43.6. 停止 firewalld43.7. 运行时和持久设置43.8. 验证永久 firewalld 配置43.9. 使用 firewalld43.9.1. 使用 CLI 禁用紧急事件的所有流量43.9.2. 使用 CLI 控制预定义服务的流量43.9.3. 使用 GUI 使用预定义服务控制流量43.9.4. 添加新服务43.9.5. 使用 CLI 控制端口43.9.5.1. 打开端口43.9.5.2. 关闭端口43.9.6. 使用 GUI 打开端口43.9.7. 使用 GUI 控制协议的流量43.9.8. 使用 GUI 打开源端口43.10. 使用 firewalld 区43.10.1. 列出区域43.10.2. 更改特定区的 firewalld 设置43.10.3. 更改默认区43.10.4. 将网络接口分配给区43.10.5. 使用 nmcli 为连接分配区域43.10.6. 在 ifcfg 文件中手动将区分配给网络连接43.10.7. 创建一个新区43.10.8. 区配置文件43.10.9. 使用区目标设定传入流量的默认行为43.11. 根据源使用区管理传入流量43.11.1. 根据源使用区管理传入流量43.11.2. 添加源43.11.3. 删除源43.11.4. 添加源端口43.11.5. 删除源端口43.11.6. 使用区和源来允许一个服务只适用于一个特定的域43.11.7. 根据协议配置区接受的流量43.11.7.1. 在区中添加协议43.11.7.2. 从区中删除协议43.12. 配置 IP 地址伪装43.13. 端口转发43.13.1. 添加一个端口来重定向43.13.2. 将 TCP 端口 80 重定向到同一台机器中的 88 端口43.13.3. 删除重定向的端口43.13.4. 在同一台机器上将 TCP 端口 80 转发到端口 8843.14. 管理 ICMP 请求43.14.1. 列出和阻塞 ICMP 请求43.14.2. 使用 GUI 配置 ICMP 过滤器43.15. 使用 firewalld43.15.1. 使用 CLI 配置 IP 设置选项43.16. 丰富规则的优先级43.16.1. priority 参数如何将规则组织为不同的链43.16.2. 设置丰富的规则的优先级43.17. 配置防火墙锁定43.17.1. 使用 CLI 配置锁定43.17.2. 使用 CLI 配置锁定白名单选项43.17.3. 使用配置文件配置锁定白名单选项43.18. 记录已拒绝数据包的日志43.19. 相关信息安装的文档在线文档第 44 章 nftables 入门44.1. 从 iptables 迁移到 nftables44.1.1. 使用 firewalld、nftables 或者 iptables 时44.1.2. 将 iptables 规则转换为 nftables 规则44.2. 编写和执行 nftables 脚本44.2.1. nftables 脚本中所需的脚本标头44.2.2. 支持的 nftables 脚本格式44.2.3. 运行 nftables 脚本44.2.4. 使用 nftables 脚本中的注释44.2.5. 使用 nftables 脚本中的变量只有一个值的变量包含匿名集合的变量44.2.6. 在 nftables 脚本中包含文件44.2.7. 系统引导时自动载入 nftables 规则44.3. 创建和管理 nftables 表、链和规则44.3.1. 标准链优先级值和文本名称44.3.2. 显示 nftables 规则集44.3.3. 创建 nftables 表44.3.4. 创建 nftables 链44.3.5. 在 nftables 链中添加规则44.3.6. 在 nftables 链中插入规则44.4. 使用 nftables 配置 NAT44.4.1. 不同的 NAT 类型: masquerading、source NAT 和 destination NAT44.4.2. 使用 nftables 配置伪装44.4.3. 使用 nftables 配置源 NAT44.4.4. 使用 nftables 配置目标 NAT44.5. 使用 nftables 命令中的设置44.5.1. 在 nftables 中使用匿名集合44.5.2. 在 nftables 中使用命名集44.5.3. 相关信息44.6. 在 nftables 命令中使用 verdict 映射44.6.1. 在 nftables 中使用字面映射44.6.2. 在 nftables 中使用 mutable verdiction 映射44.6.3. 相关信息44.7. 使用 nftables 配置端口转发44.7.1. 将传入的数据包转发到不同的本地端口44.7.2. 将特定本地端口上传入的数据包转发到不同主机44.8. 使用 nftables 来限制连接数量44.8.1. 使用 nftables 限制连接数量44.8.2. 在一分钟内阻止尝试十个新进入 TCP 连接的 IP 地址44.9. 调试 nftables 规则44.9.1. 创建带有计数器的规则44.9.2. 在现有规则中添加计数器44.9.3. 监控与现有规则匹配的数据包44.10. 备份和恢复 nftables 规则集44.10.1. 将 nftables 规则设置为一个文件44.10.2. 从文件恢复 nftables 规则集44.11. 相关信息第 45 章 使用 xdp-filter 进行高性能流量过滤以防止 DDoS 攻击45.1. 释放与 xdp-filter 规则匹配的网络数据包45.2. 丢弃所有与 xdp-filter 规则匹配的网络数据包第 46 章 DPDK 入门46.1. 安装 dpdk 软件包46.2. 相关信息第 47 章 了解 RHEL 中的 eBPF 网络功能47.1. RHEL 中网络 eBPF 功能概述XDPAF_XDP流量控制套接字过滤器控制组群流解析器(Stream Parser)SO_REUSEPORT 套接字选择dissector 流程TCP 阻塞控制带有封装的路由第 48 章 使用 BPF 编译器集合进行网络追踪48.1. BCC 介绍48.2. 安装 bcc-tools 软件包48.3. 显示添加到内核的接受队列中的 TCP 连接48.4. 追踪传出 TCP 连接尝试48.5. 测量出站 TCP 连接的延迟48.6. 显示被内核丢弃的 TCP 数据包和片段详情48.7. 追踪 TCP 会话48.8. 追踪 TCP 重新传输48.9. 显示 TCP 状态更改信息48.10. 聚合发送到特定子网的 TCP 流量48.11. 通过 IP 地址和端口显示网络吞吐量48.12. 追踪已建立的 TCP 连接48.13. 追踪 IPv4 和 IPv6 侦听尝试48.14. 软中断的服务时间概述48.15. 其它资源第 49 章 TIPC 入门49.1. TIPC 的构架49.2. 系统引导时载入 tipc 模块49.3. 创建 TIPC 网络49.4. 其它资源法律通告
配置和管理网络
RED HAT ENTERPRISE LINUX8
在 Red Hat Enterprise Linux 8 中配置和管理网络的指南
Red Hat Customer Content Services
摘要
本文档论述了如何在 Red Hat Enterprise Linux 8 中管理联网。
使开源包含更多
红帽承诺替换我们的代码、文档和网页属性中存在问题的语言。我们从这四个术语开始: master、slave、blacklist 和 whitelist。这些更改将在即将发行的几个发行本中逐渐实施。如需了解更多详细信息,请参阅 CTO Chris Wright 信息。
对红帽文档提供反馈
我们感谢您对文档提供反馈信息。请让我们了解如何改进文档。要做到这一点:
关于特定内容的简单评论:
- 请确定您使用 Multi-page HTML 格式查看文档。另外,确定 Feedback 按钮出现在文档页的右上方。
- 用鼠标指针高亮显示您想评论的文本部分。
- 点在高亮文本上弹出的 Add Feedback。
- 按照显示的步骤操作。
要提交更复杂的反馈,请创建一个 Bugzilla ticket:
- 进入 Bugzilla 网站。
- 在 Component 中选择 Documentation。
- 在 Description 中输入您要提供的信息。包括文档相关部分的链接。
- 点 Submit Bug。
第 1 章 一般 RHEL 网络主题
本节详细介绍了一般网络主题。
1.1. IP 网络和非 IP 网络之间的区别
网络是可沟通共享信息和资源的设备系统,比如文件、打印机、应用程序以及互联网连接。每个设备都有唯一的 IP 地址,可使用一组叫协议的规则在两个或者多个设备间发送和接收信息。
网络通信的类型:
IP 网络
通过 IP 地址通信的网络。IP 网络是在互联网和大多数内部网络中实现的。以太网、无线网络和 VPN 连接是典型的示例。
非 IP 网络
用于通过较低层而不是传输层进行沟通的网络。请注意这些网络很少被使用。例如,Infiniband 是一个非 IP 网络。
1.2. 静态和动态 IP 地址之间的区别
静态 IP 地址
当您为某个设备分配静态 IP 地址时,该地址不会随时间变化,除非您手动更改该地址。如果您要使用静态 IP 地址:确保 DNS 等服务器的网络地址一致性以及验证服务器。使用独立于其他网络基础结构的带外管理设备。
动态 IP 地址
当您将设备配置为使用动态 IP 地址时,该地址会随时更改。因此,动态地址通常用于偶尔连接到网络的设备,因为重启主机后 IP 地址可能会不同。动态 IP 地址更为灵活,更容易设置和管理。动态主机控制协议(DHCP)是动态为主机分配网络配置的传统方法。
注意
没有严格的规则来定义何时使用静态或动态 IP 地址。它取决于用户的需求、喜好和网络环境。
其它资源
有关设置 DHCP 服务器的详情,请参考 第 42 章 提供 DHCP 服务。
1.3. DHCP 事务阶段
DHCP 分为四个阶段: Discovery、Offer、Request、Afirmledgement(也称为 DORA 进程)。DHCP 使用这个过程为客户端提供 IP 地址。
Discovery(发现)
DHCP 客户端发送一条信息来发现网络中 DHCP 服务器。这个消息在网络和数据链路层广播。
Offer(提供)
DHCP 服务器从客户端接收信息,并为 DHCP 客户端提供 IP 地址。这个消息在数据链路层单播,但在网络层广播。
Request(请求)
DHCP 客户端为提供的 IP 地址请求 DHCP 服务器。这个消息在数据链路层单播,但在网络层广播。
Acknowledgment(承认)
DHCP 服务器向 DHCP 客户端发送承认信息。这个消息在数据链路层单播,但在网络层广播。它是 DHCP DORA 进程的最后一个信息。
1.4. InfiniBand 和 RDMA 网络
有关 InfiniBand 和远程直接内存访问(RDMA)网络的详情,请参考 配置 InfiniBand 和 RDMA 网络文档。
1.5. RHEL 中旧版网络脚本支持
默认情况下,RHEL 使用 NetworkManager 配置和管理网络连接,/usr/sbin/ifup 和 /usr/sbin/ifdown 脚本使用 NetworkManager 处理 /etc/sysconfig/network-scripts/ 目录中的 ifcfg 文件。
然而,如果您需要在不使用 NetworkManager 的情况下使用弃用的网络脚本处理网络配置,您可以安装它们:
# yum install network-scripts
安装旧的网络脚本后,/usr/sbin/ifup 和 /usr/sbin/ifdown 脚本链接到管理网络配置的已弃用 shell 脚本。
重要
旧脚本在 RHEL 8 中已弃用,并将在以后的 RHEL 主要版本中被删除。如果您仍然使用旧的网络脚本,例如,因为您从较早的版本升级到 RHEL 8,红帽建议将您的配置迁移至 NetworkManager。
1.6. 选择网络配置方法
要使用 NetworkManager 配置网络接口,请使用以下工具之一:
- 文本用户界面
nmtui。 - 命令行工具
nmcli。 - 图形用户界面工具
GNOME GUI。
- 文本用户界面
在不使用 NetworkManager 工具和应用程序的情况下配置网络接口:
- 手动编辑
ifcfg文件。请注意,即使您直接手动编辑文件,RHEL 仍默认使用 NetworkManager 来处理这些文件。只有在安装并启用了弃用的旧网络脚步后,这些脚本才会处理ifcfg文件。
- 手动编辑
在 root 文件系统不在本地的情况下配置网络设置:
- 使用内核命令行。
其它资源
第 2 章 一致的网络接口设备命名
Red Hat Enterprise Linux 8 提供用于网络接口的一致性和可预测的设备命名方法。这些特性有助于查找和区分网络接口。
内核通过连接固定前缀和在内核初始化网络设备时增大的数目为网络接口分配名称。例如: eth0 将代表引导时被探测的第一个设备。但是这些名称不一定与设备外壳上的标签对应。具有多个网络适配器的现代服务器平台,可能会遇到这些接口的命名不明确的情况。这会影响系统中嵌入的网络适配器和附加适配器。
在 Red Hat Enterprise Linux 8 中,udev 设备管理器支持很多不同的命名方案。默认情况下,udev 根据固件、拓扑和位置信息分配固定名称。它有以下优点:
- 设备名称完全可预测。
- 即使您添加或者删除硬件,设备名称也会继续修复,因为没有重新计算。
- 因此,有问题的硬件可以被无缝地替换。
2.1. 网络接口设备命名等级
如果启用了一致的设备命名(在 Red Hat Enterprise Linux 8 中是默认设置), udev 设备管理器会根据以下方案生成设备名称:
| 方案 | 描述 | 示例 |
|---|---|---|
| 1 | 设备名称包含固件或者 BIOS 提供的索引号,用于板上的设备。如果此信息不适用,udev 将使用方案 2。 | eno1 |
| 2 | 设备名称包含固件或者 BIOS 提供的 PCI Express(PCIe)热插槽索引号。如果此信息不适用,udev 将使用方案 3。 | ens1 |
| 3 | 设备名称包含硬件连接器的物理位置。如果此信息不适用,udev 将使用方案 5。 | enp2s0 |
| 4 | 设备名称包含 MAC 地址。Red Hat Enterprise Linux 默认不使用这个方案,但管理员可选择性地使用它。 | enx525400d5e0fb |
| 5 | 传统的无法预计的内核命名方案。如果 udev 无法应用任何其他方案,设备管理器将使用这个方案。 | eth0 |
默认情况下,Red Hat Enterprise Linux 根据 /usr/lib/systemd/network/99-default.link 文件中的 NamePolicy 设置选择设备名称。NamePolicy 中值的顺序非常重要。Red Hat Enterprise Linux 使用在该文件中指定的以及 udev 生成的第一个设备名称。
如果您手动配置 udev 规则以更改内核设备名称,则优先使用这些规则。
2.2. 网络设备重命名如何工作
默认情况下在 Red Hat Enterprise Linux 8 中启用了一致的设备命名。udev 设备管理器处理不同的规则来重命名设备。以下列表描述了 udev 处理这些规则的顺序,以及这些规则对什么操作:
/usr/lib/udev/rules.d/60-net.rules文件定义了/lib/udev/rename_device帮助程序在/etc/sysconfig/network-scripts/ifcfg-*文件中搜索HWADDR参数。如果变量中设置的值与接口的 MAC 地址匹配,帮助程序会将接口重命名为该文件DEVICE参数中设置的名称。/usr/lib/udev/rules.d/71-biosdevname.rules文件定义了biosdevname实用程序根据其命名策略重命名接口,只要在上一步中没有重命名。/usr/lib/udev/rules.d/75-net-description.rules文件定义udev检查网络接口设备,并在udev- 内部变量中设置属性,这些属性将在下一步中处理。请注意,其中一些属性可能没有定义。/usr/lib/udev/rules.d/80-net-setup-link.rules文件调用net_setup_linkudev内置,然后应用该策略。以下是存储在/usr/lib/systemd/network/99-default.link文件中的默认策略:xxxxxxxxxx[Link]NamePolicy=kernel database onboard slot pathMACAddressPolicy=persistent在这个策略中,如果内核使用持久名称,
udev不会重命名该接口。如果内核没有使用持久名称,udev会将接口重命名为由udev硬件数据库提供的名称。如果这个数据库不可用,Red Hat Enterprise Linux 会回复到上述机制中。另外,为介质访问控制(MAC)基于地址的接口名称将这个文件的
NamePolicy参数设置为mac。/usr/lib/udev/rules.d/80-net-setup-link.rules文件定义udev根据以下顺序基于udev内部参数重新命名接口:ID_NET_NAME_ONBOARDID_NET_NAME_SLOTID_NET_NAME_PATH
如果没有设置参数,
udev将使用下一个参数。如果没有设置任何参数,接口就不会被重命名。
第 3 步和第 4 步采用中描述的命名方案 1 到 4 第 2.1 节 “网络接口设备命名等级”。
其它资源
- 有关为一致性命名设置自定义前缀的详情,请参考 第 2.7 节 “使用 prefixdevname 命名以太网网络接口”。
- 有关
NamePolicy参数的详情,请查看systemd.link(5)man page。
2.3. x86_64 平台上的可预测的网络接口名称解释
当启用一致的网络设备名称功能时,udev 设备管理器会根据不同的标准创建设备名称。这部分论述了在 x86_64 平台中安装 Red Hat Enterprise Linux 8 时的命名方案。
接口名称以双字符前缀开始,该前缀基于接口类型:
en用于以太网wl用于无线 LAN(WLAN)ww用于无线 WAN(WWAN)
另外,下面的一项会附加到以上其中一个前缀中,该前缀根据 udev 设备管理器采用的 schema 附加:
o*<on-board_index_number>*s*<hot_plug_slot_index_number>*[f*<function>*][d*<device_id>*]请注意,所有多功能 PCI 设备在设备名称中有
[f*<function>*]号,其中包括功能0设备。x*<MAC_address>*[P*<domain_number>*]p*<bus>*s*<slot>*[f*<function>*][d*<device_id>*][P*<domain_number>*]部分定义 PCI 地理位置。只有在域号不是0时才会设定这部分。[P*<domain_number>*]p*<bus>*s*<slot>*[f*<function>*][u*<usb_port>*][…][c*<config>*][i*<interface>*]对于 USB 设备,hub 端口号的完整链由 hub 的端口号组成。如果名称大于最大值(15 个字符),则不会导出该名称。如果链中有多个 USB 设备,
udev会绕过 USB 配置描述符(c1)和 USB 接口描述符(i0)的默认值。
2.4. System z 平台中可预测的网络接口设备名称解释
当启用一致的网络设备名称特性时,System z 平台的 udev 设备管理器会根据总线 ID 创建设备名称。总线 ID 识别 s390 频道子系统中的一个设备。
对于 CCW(channel command word)设备,总线 ID 是设备号,并带有一个 0.n 前缀,其中 n 是子频道集的 ID。
以太网接口被命名,如 enccw0.0.1234。串行互联网协议(SLIP)通道到通道(CTC)网络设备被命名,例如: slccw0.0.1234。
使用 znetconf -c 或者 lscss -a 命令显示可用网络设备及其总线 ID。
2.5. 在安装过程中禁用一致的接口设备命名
这部分论述了如何在安装过程中禁用一致的接口设备命名。
警告
红帽建议不要禁用一致的设备命名。禁用一致的设备命名可能会导致不同类型的问题。例如:如果您在系统中添加了另一个网卡,则分配的内核设备名称(例如,eth0)不再是固定的。因此,重启后内核可以以不同的方式为该设备命名。
流程
引导 Red Hat Enterprise Linux 8 安装介质。
在引导管理器中,选择
Install Red Hat Enterprise Linux 8,然后按 Tab 键编辑该条目。在内核命令行中附加
net.ifnames=0参数:xxxxxxxxxxvmlinuz... net.ifnames=0按 Enter 键开始安装。
其它资源
2.6. 在安装的系统中禁用一致的接口设备命名
这部分论述了如何在已安装的系统中禁用一致的接口设备命名。
警告
红帽建议不要禁用一致的设备命名。禁用一致的设备命名可能会导致不同类型的问题。例如:如果您在系统中添加了另一个网卡,则分配的内核设备名称(例如,eth0)不再是固定的。因此,重启后内核可以以不同的方式为该设备命名。
先决条件
- 系统使用一致的接口设备命名,这是默认设置。
流程
编辑
/etc/default/grub文件,将net.ifnames=0参数附加到GRUB_CMDLINE_LINUX变量中:xxxxxxxxxxGRUB_CMDLINE_LINUX="... *net.ifnames=0重建
grub.cfg文件:在具有 UEFI 引导模式的系统上:
xxxxxxxxxx# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg在使用旧引导模式的系统上:
xxxxxxxxxx# grub2-mkconfig -o /boot/grub2/grub.cfg
如果在配置文件或脚本中使用接口名称,则必须手动更新它们。
重启主机:
xxxxxxxxxx# reboot
2.7. 使用 prefixdevname 命名以太网网络接口
本文档描述了如何在不希望使用这种接口的默认命名方案时为以太网网络接口的命名设置前缀。但是,红帽建议使用默认命名方案。有关此方案的详情,请查看 第 2 章 一致的网络接口设备命名。
2.7.1. prefixdevname 简介
prefixdevname 工具是 udev 帮助程序程序,可让您定义您自己用来命名以太网网络接口的前缀。
2.7.2. prefixdevname 的限制
以太网网络接口前缀有一些限制。
您选择的前缀必须满足以下要求:
- 必须是 ASCII 字符串
- 必须是字母数字字符串
- 少于 16 个字符
警告
该前缀不能与用于 Linux 上网络接口命名的任何其他已知的前缀冲突。特别是,您不能使用这些前缀: eth、eno、ens、em。
2.7.3. 设置 prefixdevname
使用 prefixdevname 的前缀设置是在系统安装过程中完成的。
要为您的以太网网络接口设置和激活所需前缀,请使用以下步骤。
流程
在内核命令行中添加以下字符串:
xxxxxxxxxxnet.ifnames.prefix=<required prefix>
警告
红帽不支持在已部署的系统中使用 prefixdevname。
设定了前缀后,操作系统重启后,前缀在每次出现新网络接口时都有效。为这个新设备分配一个名称,格式为 <PREFIX><INDEX>。例如,如果您选择的前缀是 net,系统中也有 net0 和 net1 前缀的接口,新接口名为 net2。然后 prefixdevname 工具会在 /etc/systemd/network 目录中生成新的 .link 文件,该文件将名称应用到刚刚出现的 MAC 地址的接口。配置在重启后会保留。
2.8. 相关信息
- 有关
udev设备管理器的详情,请查看udev(7)手册页。
第 3 章 使用 netconsole 通过网络记录内核信息
使用 netconsole 内核模块和同名的服务,您可以在登录到磁盘时或者无法使用串口控制台时,通过网络记录内核信息来调试内核。
3.1. 配置 netconsole 服务为将内核信息记录到远程主机
使用 netconsole 内核模块,您可以将内核信息记录到远程系统日志服务。
先决条件
- 在远程主机上安装了系统日志服务,如
rsyslog。 - 远程系统日志服务被配置为接收来自此主机的日志条目。
流程
安装
netconsole-service软件包:xxxxxxxxxx# yum install netconsole-service编辑
/etc/sysconfig/netconsole文件并将SYSLOGADDR参数设置为远程主机的 IP 地址:xxxxxxxxxx# SYSLOGADDR=192.0.2.1启用并启动
netconsole服务:xxxxxxxxxx# systemctl enable --now netconsole
验证步骤
- 在远程系统日志服务器中显示
/var/log/messages文件。
其它资源
- 有关启用远程主机接收日志信息的详情,请参考
Configuring basic system settings文档中的配置远程日志解决方案部分。
第 4 章 systemd 网络目标和服务
NetworkManager 在系统引导过程中配置网络。但是,当使用远程 root(/)引导时,如 root 目录存储在 iSCSI 设备中时,网络设置会在启动 RHEL 之前在初始 RAM 磁盘(initrd)中应用。例如:如果在内核命令行中使用 rd.neednet=1 指定网络配置,或者指定了用于挂载远程文件系统的配置,那么网络设置就会在 initrd 中应用。
本节描述了应用网络设置时使用的不同目标,如 network、network-online和 NetworkManager-wait-online 服务,以及如何配置 systemd 服务在 network-online 服务启动后启动。
4.1. network 和 network-online systemd target 的不同
Systemd 维护 network 和 network-online 目标单元。特殊单元,如 NetworkManager-wait-online.service 有 WantedBy=network-online.target 和 Before=network-online.target 参数。如果启用,这些单元以 network-online.target 开始,并延迟达到目标直到建立了某种类型的网络连接。它们会延迟 network-online 目标直到网络连接。
network-online 目标启动一个服务,这会增加更长的延迟来进一步执行。systemd 会自动将这个目标单元的 Wants 和 After 参数添加到所有 System V(SysV) init 脚本服务单元中,并使用指向 $network 工具的 Linux 标准基础(LSB)标头。LSB 标头是 init 脚本的元数据。您可以使用它指定依赖项。这与 systemd 目标类似。
network 目标不会显著延迟引导过程的执行。达到 network 目标意味着,负责设置网络的服务已启动。但并不意味着已经配置了一个网络设备。这个目标在关闭系统的过程中非常重要。例如:如果您在引导过程中有一个在 network 目标之后排序的服务,则在关闭过程中会取消这个依赖关系。在服务停止后,网络才会断开连接。远程网络文件系统的所有挂载单元都自动启动 network-online 目标单元和顺序。
注意
network-online 目标单元只在系统启动时有用。系统完成引导后,这个目标不会跟踪网络的在线状态。因此,您无法使用 network-online 来监控网络连接。这个目标提供了一个一次性系统启动概念。
4.2. NetworkManager-wait-online 概述
同步传统网络脚本会遍历所有配置文件来设置设备。它们应用所有与网络相关的配置并确保网络在线。
NetworkManager-wait-online 服务会等待一个超时时间来配置网络。这个网络配置涉及插入以太网设备、扫描 Wi-Fi 设备等。NetworkManager 会自动激活配置为自动启动的适当配置集。因 DHCP 超时或类似事件导致自动激活失败,网络管理器(NetworkManager)可能会在一定时间内处于忙碌状态。根据配置,NetworkManager 会重新尝试激活同一配置集或不同的配置集。
当启动完成后,所有配置集都处于断开连接的状态,或被成功激活。您可以配置配置集来自动连接。以下是一些参数示例,这些参数设定超时或者在连接被视为活跃时定义:
connection.wait-device-timeout- 为驱动程序设定检测设备的超时时间ipv4.may-fail和ipv6.may-fail- 使用一个 IP 地址家族或者一个特定的地址系列是否已完成配置进行激活。ipv4.gateway-ping-timeout- 延迟激活。
其它资源
nm-settings(5)man page
4.3. 将 systemd 服务配置为在网络已启动后再启动
Red Hat Enterprise Linux 在 /usr/lib/systemd/system/ 目录中安装 systemd 服务文件。此流程在 /etc/systemd/system/*service_name*.service.d/ 中为服务文件创建一个 drop-in 片断,该片断与 /usr/lib/systemd/system/ 中的服务文件一同用于在网络上线后启动特定 服务。如果在 drop-in 片断中的设置与 /usr/lib/systemd/system/ 中的服务文件中的设置重叠,则其具有更高优先级。
流程
要在编辑器中打开服务文件,请输入:
#
systemctl edit service_name输入以下内容并保存更改:
xxxxxxxxxx[Unit]After=network-online.target重新载入
systemd服务。#
systemctl daemon-reload
第 5 章 NetworkManager 入门
默认情况下,RHEL 8 使用 NetworkManager 管理网络配置和连接。
5.1. 使用 NetworkManager 的好处
使用 NetworkManager 的主要优点是:
- 通过 D-Bus 提供 API,它允许查询和控制网络配置和状态。这样,多个应用程序就可以检查和配置网络,确保同步和最新的网络状态。例如,通过 Web 浏览器监控和配置服务器的 RHEL web 控制台使用 NetworkManager D-BUS 界面配置网络,以及 Gnome GUI、nmcli 和 nm-connection-editor 工具。对这些工具所做的每个改变都会被其他所有用户检测到。
- 可以更方便的镜像网络配置:网络管理器( NetworkManager)确保网络连接正常工作。当发现在系统中没有网络配置但存在网络设备时,NetworkManager 会创建临时连接以提供连接。
- 提供到用户的简单连接设置: NetworkManager 通过不同的工具提供管理 - GUI、nmtui、nmcli。
- 支持配置灵活性。例如,配置 WiFi 接口,NetworkManager 会扫描并显示可用的 wifi 网络。您可以选择一个接口,NetworkManager 会显示在重启过程后提供自动连接所需的凭证。NetworkManager 可以配置网络别名、IP 地址、静态路由、DNS 信息和 VPN 连接以及很多具体连接的参数。您可以修改配置选项以反应您的需要。
- 重启过程后保持设备状态,并接管在重启过程中将其设定为受管模式的接口。
- 处理没有被显式设置但由用户或者其他网络设备手动控制的设备。
其它资源
- 有关安装和使用 RHEL 8 web 控制台的详情,请参阅 使用 RHEL 8 web 控制台管理系统。
5.2. 您可以用来管理 NetworkManager 连接的工具和应用程序概述
您可以使用以下工具和应用程序来管理 NetworkManager 连接:
nmcli:管理连接的命令行工具。nmtui:基于策展的文本用户界面(TUI)。要使用这个应用程序,请安装NetworkManager-tui软件包。nm-connection-editor:用于 NetworkManager 相关任务的图形用户界面(GUI)。要启动这个应用程序,在 GNOME 会话终端输入nm-connection-editor。control-center: GNOME shell 为桌面用户提供的 GUI。请注意,这个应用程序支持的功能比nm-connection-editor少。- GNOME shell 中的
network connection icon:这个图标代表网络连接状态,并可作为您使用的连接类型的直观指示。
其它资源
5.3. 使用 NetworkManager 分配程序脚本
默认情况下, /etc/NetworkManager/dispatcher.d/ 目录存在,NetworkManager 会以字母顺序运行脚本。每个脚本都必须为 root 拥有的 可执行文件,且只有文件所有者才有 write permission 权限。
注意
网络管理器(NetworkManager)以字母顺序执行 /etc/NetworkManager/dispatcher.d/ 分配程序脚本。
其它资源
- 有关分配程序脚本示例,请参考 如何编写 NetworkManager 分配程序脚本以应用 ethtool 命令 解决方案。
5.4. 将手动创建的 ifcfg 文件加载到 NetworkManager 中
在 Red Hat Enterprise Linux 8 中,如果您编辑了 ifcfg 文件,网络管理器(NetworkManager) 不会自动意识到这个变化,需要被告知才可以看到相关的更改。如果您使用其中一个工具更新 NetworkManager 配置集设置,NetworkManager 不会实现这些更改,除非您使用该配置集重新连接。例如,如果使用编辑器修改了配置文件,NetworkManager 必须再次读取配置文件。
/etc/sysconfig/ 目录是配置文件和脚本的位置。除 VPN、移动宽带和 PPPoE 配置外,大多数网络配置信息都存储在 /etc/NetworkManager/ 子目录中。例如,具体接口信息保存在 /etc/sysconfig/network-scripts/ 目录中的 ifcfg 文件中。
VPN、移动宽带和 PPPoE 连接的信息保存在 /etc/NetworkManager/system-connections/ 中。
注意
默认情况下,RHEL 使用 NetworkManager 配置和管理网络连接,/usr/sbin/ifup 和 /usr/sbin/ifdown 脚本使用 NetworkManager 处理 /etc/sysconfig/network-scripts/ 目录中的 ifcfg 文件。
如果您需要旧的网络脚本来管理网络设置,您可以手动安装它们。详情请查看 第 1.5 节 “RHEL 中旧版网络脚本支持”。但请注意,旧版网络脚本已弃用,并将在以后的 RHEL 版本中删除。
流程
要载入新的配置文件:
xxxxxxxxxx# nmcli connection load /etc/sysconfig/network-scripts/ifcfg-connection_name如果您更新了已载入到 NetworkManager 中的连接文件,请输入:
xxxxxxxxxx# nmcli connection up connection_name
其它资源
NetworkManager(8)man page - 描述网络管理守护进程。NetworkManager.conf(5)man page - 描述NetworkManager配置文件。/usr/share/doc/initscripts/sysconfig.txt- 描述ifcfg配置文件及其指令被旧网络服务理解。ifcfg(8)man page - 简单地描述ifcfg命令。
第 6 章 配置 NetworkManager 以忽略某些设备
默认情况下,NetworkManager 管理除 lo (回送)设备以外的所有设备。但是,您可以将某些设备设置为 unmanaged 来配置网络管理器(NetworkManager)忽略这些设备。使用这个设置,您可以手动管理这些设备,例如使用脚本。
6.1. 永久将设备配置为网络管理器(NetworkManager)中非受管设备
您可以根据以下条件将设备配置为 unmanaged ,比如接口名称、MAC 地址或者设备类型。此流程描述了如何在 NetworkManager 中永久将 enp1s0 接口设置为 unmanaged。
要临时将网络设备配置为 unmanaged,请查看 第 6.2 节 “将设备临时配置为在 NetworkManager 中不被管理”。
流程
可选:显示要识别您要设置为
unmanaged的设备列表:xxxxxxxxxx# nmcli device statusDEVICE TYPE STATE CONNECTIONenp1s0 ethernet disconnected --...使用以下内容创建
/etc/NetworkManager/conf.d/99-unmanaged-devices.conf文件:xxxxxxxxxx[keyfile]unmanaged-devices=interface-name:enp1s0要将多个设备设置为非受管设备,请使用分号分隔
unmanaged-devices参数中的条目:xxxxxxxxxx[keyfile]unmanaged-devices=interface-name:interface_1;interface-name:interface_2;...重新载入
NetworkManager服务:xxxxxxxxxx# systemctl reload NetworkManager
验证步骤
显示设备列表:
xxxxxxxxxx# nmcli device statusDEVICE TYPE STATE CONNECTIONenp1s0 ethernet unmanaged --...enp1s0设备旁的unmanaged状态表示网络管理器(NetworkManager)不管理该设备。
其它资源
- 有关可用来将设备配置为非受管以及对应语法的标准列表,请查看
NetworkManager.conf(5)man page 中的Device List Format部分。
6.2. 将设备临时配置为在 NetworkManager 中不被管理
您可以根据以下条件将设备配置为 unmanaged ,比如接口名称、MAC 地址或者设备类型。这个步骤描述了如何在 NetworkManager 中临时将 enp1s0 接口设置为 unmanaged。
可以使用这个方法用于特定目的,如测试。要永久将网络设备配置为 unmanaged,请查看 第 6.1 节 “永久将设备配置为网络管理器(NetworkManager)中非受管设备”。
可以使用这个方法用于特定目的,如测试。要永久将网络设备配置为 unmanaged,请参阅 Configuring and managing networking 文档中的网络 管理器(NetworkManager)部分中将设备配置 为非受管状态。
流程
可选:显示要识别您要设置为
unmanaged的设备列表:xxxxxxxxxx# nmcli device statusDEVICE TYPE STATE CONNECTIONenp1s0 ethernet disconnected --...将
enp1s0设备设置为unmanaged状态:xxxxxxxxxx# nmcli device set enp1s0 被管理的 no
验证步骤
显示设备列表:
xxxxxxxxxx# nmcli device statusDEVICE TYPE STATE CONNECTIONenp1s0 ethernet unmanaged --...enp1s0设备旁的unmanaged状态表示网络管理器(NetworkManager)不管理该设备。
其它资源
- 有关可用来将设备配置为非受管以及对应语法的标准列表,请查看
NetworkManager.conf(5)man page 中的Device List Format部分。
第 7 章 Linux 流量控制
Linux 提供管理和操作数据包传输的工具。Linux 流量控制(TC)子系统帮助进行策略、分类、控制以及调度网络流量。TC 还可以通过使用过滤器和动作在分类过程中利用数据包内容分栏。TC 子系统使用排队规则(qdisc)来达到此目的,这是 TC 构架的一个基本元素。
调度机制在进入或退出不同的队列前确定或者重新安排数据包。最常见的调度程序是先入先出(FIFO)调度程序。
本节介绍了排队规则,并描述了如何更新 RHEL 中的默认 qdiscs。
7.1. 排队规则概述
排队规则(qdiscs)可帮助查询以及稍后使用网络接口调度流量传输。qdisc 有两个操作:
- ENQUEUE 请求以便可以排队数据包以备稍后传输和
- 解队请求以便选择排队数据包之一以便立即传输。
每个 qdisc 都有一个名为 handle 的 16 位十六进制数字,带有一个附加的冒号,如 1: 或 abcd:。这个数字被称为 qdisc 主数字。如果 qdisc 有类,则标识符为一个由两个数字组成的对,主数字在次数字之前,<major>:<minor>,例如 abcd:1。次数字的编号方案根据 qdisc 类型而定。有时,编号是系统性的,第一类有 ID <major>:1、第 2 类 <major>:2等。一些 qdiscs 允许用户在创建类时随机设置类次要数字。
classful qdiscs
存在不同的 qdiscs 类型,有助于将数据包传送到网络接口或从网络接口传输。您可以使用 root、parent 和 child 类配置 qdiscs。子对象可以被附加的位置被称为 class。qdisc 中的类灵活,可以包括多个子类或一个子类 qdisc。对于包含有类 qdisc 的类,这可促进复杂的流量控制场景。类 qdiscs 不保存任何数据包。反之,它们根据 qdisc的具体条件把子队列和出队请求降到他们的子对象中。最后,这个递归数据包传递最终结束保存数据包的位置(在出现排队时从中提取)。
无类别 qdiscs
一些 qdiscs 不包含子类,它们名为无类别 qdiscs。与类 qdiscs 相比,无类别 qdiscs 需要较少的定制。通常情况下,将它们附加到接口就足够了。
其它资源
- 有关无类别和等级
qdiscs的详细信息,请参考tc(8)man page。 - 有关动作的详情请参考
actions和tc-actions.8man page。
7.2. RHEL 中可用的 qdiscs
每个 qdisc 都处理唯一的与网络相关的问题。以下是 RHEL 中可用的 qdiscs 列表。您可以使用以下 qdisc 中的任何一种来根据您的网络要求控制网络流量。
表 7.1. RHEL 中的可用调度程序
qdisc 名称 | 包含在 | 卸载支持 |
|---|---|---|
| 异步传输模式(ATM) | kernel-modules-extra | |
| 基于类的队列 | kernel-modules-extra | |
| 基于信用的共享 | kernel-modules-extra | 是 |
| 选择并 Keep 用于响应流程, CHOose 和 Kill 用于无响应流(CHOKE) | kernel-modules-extra | |
| 受控的延迟(CoDel) | kernel-core | |
| OLM 轮叫 Robin(DRR) | kernel-modules-extra | |
| Differentiated Services marker (DSMARK) | kernel-modules-extra | |
| Enhanced Transmission Selection (ETS) | kernel-modules-extra | 是 |
| Fair Queue (FQ) | kernel-core | |
| Fair Queuing Controlled Delay (FQ_CODel) | kernel-core | |
| Generalized Random Early Detection (GRED) | kernel-modules-extra | |
| Hierarchical Fair Service Curve (HSFC) | kernel-core | |
| Heavy-Hitter Filter (HHF) | kernel-core | |
| Hierarchy Token Bucket (HTB) | kernel-core | |
| INGRESS | kernel-core | 是 |
| Multi Queue Priority (MQPRIO) | kernel-modules-extra | 是 |
| Multiqueue (MULTIQ) | kernel-modules-extra | 是 |
| Network Emulator (NETEM) | kernel-modules-extra | |
| Proportional Integral-controller Enhanced (PIE) | kernel-core | |
| PLUG | kernel-core | |
| Quick Fair Queueing (QFQ) | kernel-modules-extra | |
| Random Early Detection (RED) | kernel-modules-extra | 是 |
| Stochastic Fair Blue (SFB) | kernel-modules-extra | |
| Stochastic Fairness Queueing (SFQ) | kernel-core | |
| Token Bucket Filter (TBF) | kernel-core | 是 |
| Trivial Link Equalizer (TEQL) | kernel-modules-extra |
重要
qdisc 卸载需要在 NIC 上支持硬件和驱动程序。
其它资源
- 如需了解用于配置
qdiscs的参数和过滤器的完整信息,请参阅tc(8)、cbq、cbs、choke、CoDel、drr,fq、htb、mqprio、netem、pie、sfb、pfifo、tc-red、sfq、tbf和prioman page。
7.3. 检查 qdisc 计数器
默认情况下,Red Hat Enterprise Linux 系统使用 fq_codel qdisc。这个步骤描述了如何检查 qdisc 计数器。
流程
可选:查看您当前的
qdisc。#
tc qdisc show dev *enp0s1*检查当前的
qdisc计数器。xxxxxxxxxx# tc -s qdisc show dev enp0s1qdisc fq_codel 0: root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5.0ms interval 100.0ms memory_limit 32Mb ecnSent 1008193 bytes 5559 pkt (dropped 233, overlimits 55 requeues 77)backlog 0b 0p requeues 0....
dropped- 由于所有队列已满而使数据包被丢弃的次数overlimits- 配置的链路容量已满的次数sent- 出队的数量
7.4. 更新默认的 qdisc
如果使用当前的 qdisc 观察网络数据包丢弃的事件,您可以根据您的网络需要更改 qdisc。您可以选择 qdisc来满足您的网络要求。这个步骤描述了如何更改 Red Hat Enterprise Linux 的默认 qdisc。
流程
查看当前的默认
qdisc。xxxxxxxxxx# sysctl -a | grep qdiscnet.core.default_qdisc = fq_codel查看当前以太网连接的
qdisc。xxxxxxxxxx# tc -s qdisc show dev enp0s1qdisc fq_codel 0: root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5.0ms interval 100.0ms memory_limit 32Mb ecnSent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)backlog 0b 0p requeues 0maxpacket 0 drop_overlimit 0 new_flow_count 0 ecn_mark 0new_flows_len 0 old_flows_len 0更新现有的
qdisc。#
sysctl -w net.core.default_qdisc=pfifo_fast要应用这些更改,重新载入网络驱动程序。
#
rmmod *NETWORKDRIVERNAME*#
modprobe *NETWORKDRIVERNAME*启动网络接口。
#
ip link set *enp0s1* up
验证步骤
查看以太网连接的
qdisc。xxxxxxxxxx# tc -s qdisc show dev enp0s1qdisc pfifo_fast 0: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1Sent 373186 bytes 5333 pkt (dropped 0, overlimits 0 requeues 0)backlog 0b 0p requeues 0....
其它资源
- 有关永久更改的详情,请参考如何在 Red Hat Enterprise Linux 中设置
sysctl变量。
7.5. 更新当前的 qdisc
您可以在不更改默认文件的情况下更新当前的 qdisc。这个步骤描述了如何更改 Red Hat Enterprise Linux 中当前的 qdisc。
流程
可选:查看当前的
qdisc。#
tc -s qdisc show dev *enp0s1*更新当前的
qdisc。#
tc qdisc replace dev *enp0s1* root *htb*
验证步骤
查看更新的当前
qdisc。xxxxxxxxxx# tc -s qdisc show dev enp0s1qdisc htb 8001: root refcnt 2 r2q 10 default 0 direct_packets_stat 0 direct_qlen 1000Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)backlog 0b 0p requeues 0
第 8 章 nmtui 入门
nmtui 应用程序是一个用于 NetworkManager 的文本用户界面(TUI)。下面的部分提供了如何使用 nmtui 配置网络接口。
注意
nmtui 应用程序不支持所有连接类型。特别是,您无法添加或修改需要 802.1X 验证的 VPN 连接或以太网连接。
8.1. 启动 nmtui 工具
这个步骤描述了如何启动 NetworkManager 文本用户界面 nmtui。
先决条件
- 已安装
NetworkManager-tui软件包。
流程
要启动
nmtui,输入:xxxxxxxxxx# nmtui
访问:
- 在选项中,使用光标或按 Tab 键前进,按Shift+Tab 后退。
- 使用 Enter 选择一个选项。
- 使用空格键切换复选框的状态。
8.2. 使用 nmtui 添加连接配置集
nmtui 应用程序为 NetworkManager 提供了一个文本用户界面。以下介绍了如何添加新连接配置集的步骤。
先决条件
- 已安装
NetworkManager-tui软件包。
流程
启动 NetworkManager 文本用户界面工具:
xxxxxxxxxx# nmtui选择
Edit a connection菜单条目,点 Enter。选择 Add 按钮,点 Enter。
选择
Ethernet,点 Enter。输入连接详情信息。

选择 OK 保存更改。
选择
Back返回主菜单。选择
Activate a connection,点 Enter。选择新的连接条目,点 Enter 键激活连接。
选择 Back 返回主菜单。
选择
Quit。
验证步骤
显示设备和连接的状态:
xxxxxxxxxx# nmcli device statusDEVICE TYPE STATE CONNECTIONenp1s0 ethernet connected Example-Connection显示连接配置集的所有设置:
xxxxxxxxxx# nmcli connection show Example-Connectionconnection.id: Example-Connectionconnection.uuid: b6cdfa1c-e4ad-46e5-af8b-a75f06b79f76connection.stable-id: --connection.type: 802-3-ethernetconnection.interface-name: enp1s0...
其它资源
- 有关测试连接的更多信息,请参阅 第 38 章 测试基本网络设置。
- 有关
nmtui应用程序的详情,请查看nmtui(1)man page。 - 如果磁盘中的配置与设备中的配置不匹配,则启动或重启 NetworkManager 会创建一个代表该设备的配置的内存连接。有关详情以及如何避免此问题,请参阅 NetworkManager 服务重启后复制连接。
8.3. 使用 nmtui 对修改的连接应用更改
在 nmtui 中修改了连接后,您必须重新激活连接。请注意,在 nmtui 中重新激活连接会暂时取消激活连接。
流程
在主菜单中选择
Activate a connection菜单条目:
选择修改的连接。
在右侧,选择
Deactivate按钮,然后按 Enter:
再次选择连接。
在右侧,选择
Activate按钮,然后按 Enter:
第 9 章 nmcli 入门
本节描述了有关 nmcli 工具的一般信息。
9.1. nmcli 输出格式的不同
nmcli 工具支持不同的选项来修改 nmcli 命令的输出。通过使用这些选项,您可以只显示所需的信息。这简化了处理脚本中输出的过程。
默认情况下,nmcli 工具以类似表的格式显示其输出:
xxxxxxxxxx# nmcli deviceDEVICE TYPE STATE CONNECTIONenp1s0 ethernet connected enp1s0lo loopback unmanaged --
使用 -f 选项,您可以按自定义顺序显示特定列。例如,如果只需要显示 DEVICE 和 STATE 列,输入:
xxxxxxxxxx# nmcli -f DEVICE,STATE deviceDEVICE STATEenp1s0 connectedlo unmanaged
-t 选项允许您以冒号分隔格式显示输出的每个字段:
xxxxxxxxxx# nmcli -t deviceenp1s0:ethernet:connected:enp1s0lo:loopback:unmanaged:
如果使用脚步来处理输出时,可以使用 -f 和 -t 的组合来只显示特定字段(以冒号分隔不同字段):
xxxxxxxxxx# nmcli -f DEVICE,STATE -t deviceenp1s0:connectedlo:unmanaged
9.2. 在 nmcli 中使用 tab 自动完成
如果在您的主机上安装了 bash-completion 软件包,则 nmcli 程序支持 tab 自动完成功能。这可让您自动完成选项名称,并识别可能的选项和值。
例如:如果您输入 nmcli con 并按 Tab 键,则 shell 会自动完成命令到 nmcli connection。
您所输入的选项或值必须是唯一的。如果它不是唯一的,那么 nmcli 会显示所有可能。例如:如果您输入 nmcli connection d 并按 Tab 键,则命令会显示命令 delete 和 down 作为可能的选项。
您还可以使用 tab 自动完成来显示连接配置集中可以设置的所有属性。例如,如果您输入 nmcli connection modify *connection_name* 并按 Tab 键,该命令会显示可用属性的完整列表。
9.3. 频繁使用的 nmcli 命令
下面是一个经常使用的 nmcli 命令的概述。
要显示列表连接配置集,请输入:
xxxxxxxxxx# nmcli connection showNAME UUID TYPE DEVICEenp1s0 45224a39-606f-4bf7-b3dc-d088236c15ee ethernet enp1s0要显示特定连接配置集的设置,请输入:
xxxxxxxxxx# nmcli connection show connection_nameconnection.id: enp1s0connection.uuid: 45224a39-606f-4bf7-b3dc-d088236c15eeconnection.stable-id: --connection.type: 802-3-ethernet...要修改连接的属性,请输入:
xxxxxxxxxx# nmcli connection modify connection_name 属性值如果您将多个
*property* *value*组合传递给命令,则可以使用单个命令来修改多个属性。要显示网络设备列表、其状态以及使用该设备的连接配置集,请输入:
xxxxxxxxxx# nmcli deviceDEVICE TYPE STATE CONNECTIONenp1s0 ethernet connected enp1s0enp8s0 ethernet disconnected --enp7s0 ethernet unmanaged --...要激活连接,请输入:
xxxxxxxxxx# nmcli connection up connection_name要取消激活连接,请输入:
xxxxxxxxxx# nmcli connection down connection_name
第 10 章 使用 GNOME GUI 配置网络入门
您可以在 GNOME 中使用以下方法管理和配置网络连接:
- 桌面右上角的 GNOME Shell 网络连接图标
- GNOME control-center 应用程序
- GNOME nm-connection-editor 应用程序
10.1. 使用 GNOME Shell 网络连接图标进行网络连接
如果使用 GNOME GUI,可以使用 GNOME Shell 网络连接图标进行网络连接。
先决条件
- 已安装
GNOME软件包组。 - 您已登录到 GNOME。
- 如果网络需要特定的配置,如静态 IP 地址或 802.1x 配置,则需要已创建了连接配置集。
流程
点击桌面右上角的网络连接图标。

根据连接类型,选择
Wired或Wi-Fi条目。
- 对于有线连接,选择
Connect以连接网络。 - 对于 Wi-Fi 连接,击
Select network,选择您要连接的网络,然后输入密码。
- 对于有线连接,选择
第 11 章 配置以太网连接
这部分论述了如何使用静态和动态 IP 地址配置以太网连接的不同方法。
11.1. 使用 nmcli 配置静态以太网连接
这个步骤描述了使用 nmcli 实用程序在以下设置中添加以太网连接:
- 静态 IPv4 地址 -
192.0.2.1,子网掩码为/24 - 静态 IPv6 地址 -
2001:db8:1::1,子网掩码为/64 - IPv4 默认网关 -
192.0.2.254 - IPv6 默认网关 -
2001:db8:1::fffe - IPv4 DNS 服务器 -
192.0.2.200 - IPv6 DNS 服务器 -
2001:db8:1::ffbb - DNS 搜索域 -
example.com
流程
为以太网连接添加新的 NetworkManager 连接配置集:
xxxxxxxxxx# nmcli connection add con-name Example-Connection ifname enp7s0 type ethernet额外步骤修改您创建的
Example-Connection连接配置集。设置 IPv4 地址:
xxxxxxxxxx# nmcli connection modify Example-Connection ipv4.addresses 192.0.2.1/24设置 IPv6 地址:
xxxxxxxxxx# nmcli connection modify Example-Connection ipv6.addresses 2001:db8:1::1/64将 IPv4 和 IPv6 连接方法设置为
manual:xxxxxxxxxx# nmcli connection modify Example-Connection ipv4.method manual# nmcli connection modify Example-Connection ipv6.method manual设置 IPv4 和 IPv6 默认网关:
xxxxxxxxxx# nmcli connection modify Example-Connection ipv4.gateway 192.0.2.254# nmcli connection modify Example-Connection ipv6.gateway 2001:db8:1::fffe设置 IPv4 和 IPv6 DNS 服务器地址:
xxxxxxxxxx# nmcli connection modify Example-Connection ipv4.dns "192.0.2.200"# nmcli connection modify Example-Connection ipv6.dns "2001:db8:1::ffbb"要设置多个 DNS 服务器,以空格分隔并用引号括起来。
为 IPv4 和 IPv6 连接设置 DNS 搜索域:
xxxxxxxxxx# nmcli connection modify Example-Connection ipv4.dns-search example.com# nmcli connection modify Example-Connection ipv6.dns-search example.com激活连接配置集:
xxxxxxxxxx# nmcli connection up Example-ConnectionConnection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/13)
验证步骤
显示设备和连接的状态:
xxxxxxxxxx# nmcli device statusDEVICE TYPE STATE CONNECTIONenp7s0 ethernet connected Example-Connection显示连接配置集的所有设置:
xxxxxxxxxx# nmcli connection show Example-Connectionconnection.id: Example-Connectionconnection.uuid: b6cdfa1c-e4ad-46e5-af8b-a75f06b79f76connection.stable-id: --connection.type: 802-3-ethernetconnection.interface-name: enp7s0...使用
ping实用程序验证这个主机是否可以向其他主机发送数据包。查找同一子网中的 IP 地址。
对于 IPv4:
xxxxxxxxxx# ping 192.0.2.3对于 IPv6:
xxxxxxxxxx# ping 2001:db8:2::1如果命令失败,请验证 IP 和子网的设置。
在远程子网中查找 IP 地址。
对于 IPv4:
xxxxxxxxxx# ping 198.162.3.1对于 IPv6:
xxxxxxxxxx# ping 2001:db8:2::1如果命令失败,则使用 ping 默认网关来验证设置。
对于 IPv4:
xxxxxxxxxx# ping 192.0.2.254对于 IPv6:
xxxxxxxxxx# ping 2001:db8:1::fffe
使用
host实用程序验证名称解析是否正常工作。例如:xxxxxxxxxx# host client.example.com如果命令返回任何错误,如
connection timed out或no servers could be reached,请验证您的 DNS 设置。
故障排除步骤
如果连接失败,或者网络接口在上线和关闭状态间切换:
- 确保网络电缆插入到主机和交换机。
- 检查连接失败是否只存在于这个主机上,或者其他连接到该服务器连接的同一交换机的主机中。
- 验证网络电缆和网络接口是否如预期工作。执行硬件诊断步骤并替换缺陷电缆和网络接口卡。
其它资源
- 有关连接配置集属性及其设置的详情,请查看
nm-settings(5)手册页。 - 有关
nmcli工具程序的详情,请查看nmcli(1)man page。 - 如果磁盘中的配置与设备中的配置不匹配,则启动或重启 NetworkManager 会创建一个代表该设备的配置的内存连接。有关详情以及如何避免此问题,请参阅 NetworkManager 服务重启后复制连接。
11.2. 使用 nmcli 互动编辑器配置静态以太网连接
这个步骤描述了使用 nmcli 互动模式在以下设置中添加以太网连接:
- 静态 IPv4 地址 -
192.0.2.1,子网掩码为/24 - 静态 IPv6 地址 -
2001:db8:1::1,子网掩码为/64 - IPv4 默认网关 -
192.0.2.254 - IPv6 默认网关 -
2001:db8:1::fffe - IPv4 DNS 服务器 -
192.0.2.200 - IPv6 DNS 服务器 -
2001:db8:1::ffbb - DNS 搜索域 -
example.com
流程
要为以太网连接添加新的 NetworkManager 连接配置集并启动互动模式,请输入:
xxxxxxxxxx# nmcli connection edit type ethernet con-name Example-Connection设置网络接口:
xxxxxxxxxxnmcli> set connection.interface-name enp7s0设置 IPv4 地址:
xxxxxxxxxxnmcli> set ipv4.addresses 192.0.2.1/24设置 IPv6 地址:
xxxxxxxxxxnmcli> set ipv6.addresses 2001:db8:1::1/64将 IPv4 和 IPv6 连接方法设置为
manual:xxxxxxxxxxnmcli> set ipv4.method manualnmcli> set ipv6.method manual设置 IPv4 和 IPv6 默认网关:
xxxxxxxxxxnmcli> set ipv4.gateway 192.0.2.254nmcli> set ipv6.gateway 2001:db8:1::fffe设置 IPv4 和 IPv6 DNS 服务器地址:
xxxxxxxxxxnmcli> set ipv4.dns 192.0.2.200nmcli> set ipv6.dns 2001:db8:1::ffbb要设置多个 DNS 服务器,以空格分隔并用引号括起来。
为 IPv4 和 IPv6 连接设置 DNS 搜索域:
xxxxxxxxxxnmcli> set ipv4.dns-search example.comnmcli> set ipv6.dns-search example.com保存并激活连接:
xxxxxxxxxxnmcli> save persistentSaving the connection with 'autoconnect=yes'. That might result in an immediate activation of the connection.Do you still want to save? (yes/no) [yes] yes保留为互动模式:
xxxxxxxxxxnmcli> quit
验证步骤
显示设备和连接的状态:
xxxxxxxxxx# nmcli device statusDEVICE TYPE STATE CONNECTIONenp7s0 ethernet connected Example-Connection显示连接配置集的所有设置:
xxxxxxxxxx# nmcli connection show Example-Connectionconnection.id: Example-Connectionconnection.uuid: b6cdfa1c-e4ad-46e5-af8b-a75f06b79f76connection.stable-id: --connection.type: 802-3-ethernetconnection.interface-name: enp7s0...使用
ping实用程序验证这个主机是否可以向其他主机发送数据包。查找同一子网中的 IP 地址。
对于 IPv4:
xxxxxxxxxx# ping 192.0.2.3对于 IPv6:
xxxxxxxxxx# ping 2001:db8:2::1如果命令失败,请验证 IP 和子网的设置。
在远程子网中查找 IP 地址。
对于 IPv4:
xxxxxxxxxx# ping 198.162.3.1对于 IPv6:
xxxxxxxxxx# ping 2001:db8:2::1如果命令失败,则使用 ping 默认网关来验证设置。
对于 IPv4:
xxxxxxxxxx# ping 192.0.2.254对于 IPv6:
xxxxxxxxxx# ping 2001:db8:1::fffe
使用
host实用程序验证名称解析是否正常工作。例如:xxxxxxxxxx# host client.example.com如果命令返回任何错误,如
connection timed out或no servers could be reached,请验证您的 DNS 设置。
故障排除步骤
如果连接失败,或者网络接口在上线和关闭状态间切换:
- 确保网络电缆插入到主机和交换机。
- 检查连接失败是否只存在于这个主机上,或者其他连接到该服务器连接的同一交换机的主机中。
- 验证网络电缆和网络接口是否如预期工作。执行硬件诊断步骤并替换缺陷电缆和网络接口卡。
其它资源
- 有关连接配置集属性及其设置的详情,请查看
nm-settings(5)手册页。 - 有关
nmcli工具程序的详情,请查看nmcli(1)man page。 - 如果磁盘中的配置与设备中的配置不匹配,则启动或重启 NetworkManager 会创建一个代表该设备的配置的内存连接。有关详情以及如何避免此问题,请参阅 NetworkManager 服务重启后复制连接。
11.3. 使用 RHEL 系统角色配置静态以太网连接
此流程描述了如何使用 RHEL 系统角色通过运行 Ansible playbook 为 enp7s0 接口远程添加带有以下设置的以太网连接:
- 静态 IPv4 地址 -
192.0.2.1,子网掩码为/24 - 静态 IPv6 地址 -
2001:db8:1::1,子网掩码为/64 - IPv4 默认网关 -
192.0.2.254 - IPv6 默认网关 -
2001:db8:1::fffe - IPv4 DNS 服务器 -
192.0.2.200 - IPv6 DNS 服务器 -
2001:db8:1::ffbb - DNS 搜索域 -
example.com
在 Ansible 控制节点上运行此步骤。
先决条件
- 在控制节点上安装
ansible和rhel-system-roles软件包。 - 如果您运行 playbook 时使用了与
root不同的远程用户, 则此用户在受管节点上需要具有适当的sudo权限。 - 主机使用 NetworkManager 配置网络。
流程
如果 playbook 要针对其执行的主机还没有在清单中,请将此主机的 IP 或名称添加到
/etc/ansible/hostsAnsible 清单文件中:xxxxxxxxxxnode.example.com使用以下内容创建
~/ethernet-static-IP.ymlplaybook:xxxxxxxxxx---- name: Configure an Ethernet connection with static IPhosts: node.example.combecome: truetasks:- include_role:name: linux-system-roles.networkvars:network_connections:- name: enp7s0type: ethernetautoconnect: yesip:address:- 192.0.2.1/24- 2001:db8:1::1/64gateway4: 192.0.2.254gateway6: 2001:db8:1::fffedns:- 192.0.2.200- 2001:db8:1::ffbbdns_search:- example.comstate: up运行 playbook:
以
root用户身份连接到受管主机,输入:xxxxxxxxxx# ansible-playbook -u root ~/ethernet-static-IP.yml以用户身份连接到受管主机,请输入:
xxxxxxxxxx# ansible-playbook -u user_name --ask-become-pass ~/ethernet-static-IP.yml--ask-become-pass选项定义ansible-playbook命令提示输入-u *user_name*选项中定义的用户sudo密码。
如果没有指定
-u *user_name*选项,请以当前登录到控制节点的用户ansible-playbook连接到受管主机。
其它资源
- 有关使用的参数
network_connections以及network系统角色的额外信息,请查看/usr/share/ansible/roles/rhel-system-roles.network/README.md文件。 - 有关
ansible-playbook命令的详情,请参考ansible-playbook(1)man page。
11.4. 使用 nmcli 配置动态以太网连接
这个步骤描述了使用 nmcli 工具添加动态以太网连接。使用这个设置,网络管理器(NetworkManager)从 DHCP 服务器请求这个连接的 IP 设置。
先决条件
- 网络中有 DHCP 服务器。
流程
为以太网连接添加新的 NetworkManager 连接配置集:
xxxxxxxxxx# nmcli connection add con-name Example-Connection ifname enp7s0 type ethernet另外,在使用
Example-Connection配置集时更改主机名 NetworkManager 发送到 DHCP 服务器:xxxxxxxxxx# nmcli connection modify Example-Connection ipv4.dhcp-hostname Example ipv6.dhcp-hostname 示例另外,在使用
Example-Connection配置集时,更改客户端 ID NetworkManager 发送到 IPv4 DHCP 服务器:xxxxxxxxxx# nmcli connection modify Example-Connection ipv4.dhcp-client-id client-ID请注意,没有 IPv6 的
dhcp-client-id参数。要为 IPv6 创建标识符,请配置dhclient服务。
验证步骤
显示设备和连接的状态:
xxxxxxxxxx# nmcli device statusDEVICE TYPE STATE CONNECTIONenp7s0 ethernet connected Example-Connection显示连接配置集的所有设置:
xxxxxxxxxx# nmcli connection show Example-Connectionconnection.id: Example-Connectionconnection.uuid: b6cdfa1c-e4ad-46e5-af8b-a75f06b79f76connection.stable-id: --connection.type: 802-3-ethernetconnection.interface-name: enp7s0...使用
ping实用程序验证这个主机是否可以向其他主机发送数据包。查找同一子网中的 IP 地址。
对于 IPv4:
xxxxxxxxxx# ping 192.0.2.3对于 IPv6:
xxxxxxxxxx# ping 2001:db8:2::1如果命令失败,请验证 IP 和子网的设置。
在远程子网中查找 IP 地址。
对于 IPv4:
xxxxxxxxxx# ping 198.162.3.1对于 IPv6:
xxxxxxxxxx# ping 2001:db8:2::1如果命令失败,则使用 ping 默认网关来验证设置。
对于 IPv4:
xxxxxxxxxx# ping 192.0.2.254对于 IPv6:
xxxxxxxxxx# ping 2001:db8:1::fffe
使用
host实用程序验证名称解析是否正常工作。例如:xxxxxxxxxx# host client.example.com如果命令返回任何错误,如
connection timed out或no servers could be reached,请验证您的 DNS 设置。
其它资源
- 有关为 IPv6 设置客户端标识符的详情,请查看
dhclient(8)man page。 - 有关连接配置集属性及其设置的详情,请查看
nm-settings(5)手册页。 - 有关
nmcli工具程序的详情,请查看nmcli(1)man page。 - 如果磁盘中的配置与设备中的配置不匹配,则启动或重启 NetworkManager 会创建一个代表该设备的配置的内存连接。有关详情以及如何避免此问题,请参阅 NetworkManager 服务重启后复制连接。
11.5. 使用 nmcli 互动编辑器配置动态以太网连接
这个步骤描述了使用 nmcli 工具的互动编辑器添加动态以太网连接。使用这个设置,网络管理器(NetworkManager)从 DHCP 服务器请求这个连接的 IP 设置。
先决条件
- 网络中有 DHCP 服务器。
流程
要为以太网连接添加新的 NetworkManager 连接配置集并启动互动模式,请输入:
xxxxxxxxxx# nmcli connection edit type ethernet con-name Example-Connection设置网络接口:
xxxxxxxxxxnmcli> set connection.interface-name enp7s0另外,在使用
Example-Connection配置集时更改主机名 NetworkManager 发送到 DHCP 服务器:xxxxxxxxxxnmcli> set ipv4.dhcp-hostname Examplenmcli> set ipv6.dhcp-hostname Example另外,在使用
Example-Connection配置集时,更改客户端 ID NetworkManager 发送到 IPv4 DHCP 服务器:xxxxxxxxxxnmcli> set ipv4.dhcp-client-id client-ID请注意,没有 IPv6 的
dhcp-client-id参数。要为 IPv6 创建标识符,请配置dhclient服务。保存并激活连接:
xxxxxxxxxxnmcli> save persistentSaving the connection with 'autoconnect=yes'. That might result in an immediate activation of the connection.Do you still want to save? (yes/no) [yes] yes保留为互动模式:
xxxxxxxxxxnmcli> quit
验证步骤
显示设备和连接的状态:
xxxxxxxxxx# nmcli device statusDEVICE TYPE STATE CONNECTIONenp7s0 ethernet connected Example-Connection显示连接配置集的所有设置:
xxxxxxxxxx# nmcli connection show Example-Connectionconnection.id: Example-Connectionconnection.uuid: b6cdfa1c-e4ad-46e5-af8b-a75f06b79f76connection.stable-id: --connection.type: 802-3-ethernetconnection.interface-name: enp7s0...使用
ping实用程序验证这个主机是否可以向其他主机发送数据包。查找同一子网中的 IP 地址。
对于 IPv4:
xxxxxxxxxx# ping 192.0.2.3对于 IPv6:
xxxxxxxxxx# ping 2001:db8:2::1如果命令失败,请验证 IP 和子网的设置。
在远程子网中查找 IP 地址。
对于 IPv4:
xxxxxxxxxx# ping 198.162.3.1对于 IPv6:
xxxxxxxxxx# ping 2001:db8:2::1如果命令失败,则使用 ping 默认网关来验证设置。
对于 IPv4:
xxxxxxxxxx# ping 192.0.2.254对于 IPv6:
xxxxxxxxxx# ping 2001:db8:1::fffe
使用
host实用程序验证名称解析是否正常工作。例如:xxxxxxxxxx# host client.example.com如果命令返回任何错误,如
connection timed out或no servers could be reached,请验证您的 DNS 设置。
其它资源
- 有关为 IPv6 设置客户端标识符的详情,请查看
dhclient(8)man page。 - 有关连接配置集属性及其设置的详情,请查看
nm-settings(5)手册页。 - 有关
nmcli工具程序的详情,请查看nmcli(1)man page。 - 如果磁盘中的配置与设备中的配置不匹配,则启动或重启 NetworkManager 会创建一个代表该设备的配置的内存连接。有关详情以及如何避免此问题,请参阅 NetworkManager 服务重启后复制连接。
11.6. 使用 RHEL 系统角色配置动态以太网连接
此流程描述了如何使用 RHEL 系统角色通过运行 Ansible playbook 为 enp7s0 接口远程添加动态以太网连接。在这个设置中,网络连接从 DHCP 服务器请求这个连接的 IP 设置。在 Ansible 控制节点上运行此步骤。
先决条件
- 网络中有 DHCP 服务器。
- 在控制节点上安装
ansible和rhel-system-roles软件包。 - 如果您运行 playbook 时使用了与
root不同的远程用户, 则此用户在受管节点上需要具有适当的sudo权限。 - 主机使用 NetworkManager 配置网络。
流程
如果 playbook 要针对其执行的主机还没有在清单中,请将此主机的 IP 或名称添加到
/etc/ansible/hostsAnsible 清单文件中:xxxxxxxxxxnode.example.com使用以下内容创建
~/ethernet-dynamic-IP.ymlplaybook:xxxxxxxxxx---- name: Configure an Ethernet connection with dynamic IPhosts: node.example.combecome: truetasks:- include_role:name: linux-system-roles.networkvars:network_connections:- name: enp7s0type: ethernetautoconnect: yesip:dhcp4: yesauto6: yesstate: up运行 playbook:
以
root用户身份连接到受管主机,输入:xxxxxxxxxx# ansible-playbook -u root ~/ethernet-dynamic-IP.yml以用户身份连接到受管主机,请输入:
xxxxxxxxxx# ansible-playbook -u user_name --ask-become-pass ~/ethernet-dynamic-IP.yml--ask-become-pass选项定义ansible-playbook命令提示输入-u *user_name*选项中定义的用户sudo密码。
如果没有指定
-u *user_name*选项,请以当前登录到控制节点的用户ansible-playbook连接到受管主机。
其它资源
- 有关使用的参数
network_connections以及network系统角色的额外信息,请查看/usr/share/ansible/roles/rhel-system-roles.network/README.md文件。 - 有关
ansible-playbook命令的详情,请参考ansible-playbook(1)man page。
11.7. 使用 control-center 配置以太网连接
以太网连接是在物理机或虚拟机中最常用的连接类型。本节论述了如何在 GNOME control-center 中配置此连接类型:
请注意,control-center 不支持 nm-connection-editor 应用程序或 nmcli 实用程序。
先决条件
- 服务器配置中有一个物理或者虚拟以太网设备。
- 已安装了 GNOME。
流程
按 Super 键,输入
Settings,然后按 Enter 键。在左侧导航中选择
Network。点
Wired条目旁边的 + 按钮创建新配置集。可选:在
Identity标签页上为连接设置名称。在
IPv4标签中配置 IPv4 设置。例如,选择方法Manual,设置静态 IPv4 地址、网络掩码、默认网关和 DNS 服务器:
在
IPv6标签中配置 IPv6 设置。例如,选择方法Manual,设置静态 IPv6 地址、网络掩码、默认网关和 DNS 服务器:
点击 添加 按钮保存连接。GNOME
control-center会自动激活连接。
验证步骤
显示设备和连接的状态:
xxxxxxxxxx# nmcli device statusDEVICE TYPE STATE CONNECTIONenp7s0 ethernet connected Example-Connection显示连接配置集的所有设置:
xxxxxxxxxx# nmcli connection show Example-Connectionconnection.id: Example-Connectionconnection.uuid: b6cdfa1c-e4ad-46e5-af8b-a75f06b79f76connection.stable-id: --connection.type: 802-3-ethernetconnection.interface-name: enp7s0...使用
ping实用程序验证这个主机是否可以向其他主机发送数据包。查找同一子网中的 IP 地址。
对于 IPv4:
xxxxxxxxxx# ping 192.0.2.3对于 IPv6:
xxxxxxxxxx# ping 2001:db8:2::1如果命令失败,请验证 IP 和子网的设置。
在远程子网中查找 IP 地址。
对于 IPv4:
xxxxxxxxxx# ping 198.162.3.1对于 IPv6:
xxxxxxxxxx# ping 2001:db8:2::1如果命令失败,则使用 ping 默认网关来验证设置。
对于 IPv4:
xxxxxxxxxx# ping 192.0.2.254对于 IPv6:
xxxxxxxxxx# ping 2001:db8:1::fffe
使用
host实用程序验证名称解析是否正常工作。例如:xxxxxxxxxx# host client.example.com如果命令返回任何错误,如
connection timed out或no servers could be reached,请验证您的 DNS 设置。
故障排除步骤
如果连接失败,或者网络接口在上线和关闭状态间切换:
- 确保网络电缆插入到主机和交换机。
- 检查连接失败是否只存在于这个主机上,或者其他连接到该服务器连接的同一交换机的主机中。
- 验证网络电缆和网络接口是否如预期工作。执行硬件诊断步骤并替换缺陷电缆和网络接口卡。
11.8. 使用 nm-connection-editor 配置以太网连接
以太网连接是在物理或者虚拟服务器中最常用的连接类型。本节论述了如何使用 nm-connection-editor 应用程序配置此连接类型。
先决条件
- 服务器配置中有一个物理或者虚拟以太网设备。
- 已安装了 GNOME。
流程
打开终端窗口,输入:
xxxxxxxxxx$ nm-connection-editor点 + 按钮添加新连接。
选择
Ethernet连接类型,并点击 Create。在
General标签页中:要在系统引导时或者重启
NetworkManager服务时自动启用此连接:选择
Connect automatically with priority。可选:修改
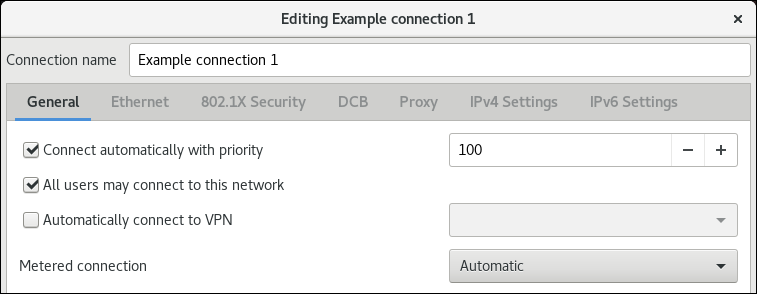
Connect automatically with priority旁边的优先级值。如果同一设备有多个连接配置集,NetworkManager 只启用一个配置集。默认情况下,NetworkManager 激活启用了自动连接的最后使用的配置集。但是,如果您在配置集中设置了优先级值,NetworkManager 会以最高优先级激活配置集。
如果配置集应该只对创建连接配置集的用户可用,请清除
All users may connect to this network复选框。

在
Ethernet标签中选择一个设备,还可以选择其它与以太网相关的设置。
在
IPv4 Settings标签中配置 IPv4 设置。例如,设置静态 IPv4 地址、网络掩码、默认网关和 DNS 服务器:
在
IPv6 Settings标签中配置 IPv6 设置。例如,设置静态 IPv6 地址、网络掩码、默认网关和 DNS 服务器:
保存连接。
关闭
nm-connection-editor。
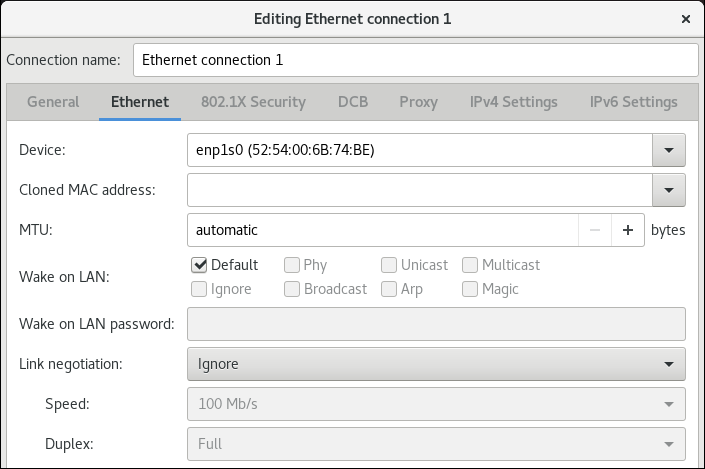
验证步骤
使用
ping实用程序验证这个主机是否可以向其他主机发送数据包。查找同一子网中的 IP 地址。
对于 IPv4:
xxxxxxxxxx# ping 192.0.2.3对于 IPv6:
xxxxxxxxxx# ping 2001:db8:2::1如果命令失败,请验证 IP 和子网的设置。
在远程子网中查找 IP 地址。
对于 IPv4:
xxxxxxxxxx# ping 198.162.3.1对于 IPv6:
xxxxxxxxxx# ping 2001:db8:2::1如果命令失败,则使用 ping 默认网关来验证设置。
对于 IPv4:
xxxxxxxxxx# ping 192.0.2.254对于 IPv6:
xxxxxxxxxx# ping 2001:db8:1::fff3
使用
host实用程序验证名称解析是否正常工作。例如:xxxxxxxxxx# host client.example.com如果命令返回任何错误,如
connection timed out或no servers could be reached,请验证您的 DNS 设置。
11.9. 配置网络管理器连接的 DHCP 行为
动态主机配置协议(DHCP)客户端在每次连接到网络时从 DHCP 服务器请求动态 IP 地址以及对应的配置信息。
当您将连接配置为从 DHCP 服务器检索 IP 地址时,网络管理器(NetworkManager)从 DHCP 服务器请求 IP 地址。默认情况下,客户端会等待 45 秒时间完成此请求。当 DHCP 连接启动时,dhcp 客户端会从 DHCP 服务器请求 IP 地址。
先决条件
- 在主机上配置了使用 DHCP 的连接。
流程
设置
ipv4.dhcp-timeout和ipv6.dhcp-timeout属性。例如:要将这两个选项都设为30秒,请输入:xxxxxxxxxx# nmcli connection modify connection_name ipv4.dhcp-timeout 30 ipv6.dhcp-timeout 30另外,将参数设置为
infinity以配置网络管理器(NetworkManager)不会停止尝试请求并续订 IP 地址,直到成功为止。可选:配置如果网络管理器(NetworkManager)在超时前没有接收 IPv4 地址时的行为:
xxxxxxxxxx# nmcli connection modify connection_name ipv4.may-fail value如果您将
ipv4.may-fail选项设置为:yes,连接的状态取决于 IPv6 配置:- 如果启用了 IPv6 配置并成功,NetworkManager 会激活 IPv6 连接,不再尝试激活 IPv4 连接。
- 如果禁用或未配置 IPv6 配置,连接会失败。
no,连接将被停用。在这种情况下:- 如果连接的
autoconnect属性被启用,NetworkManager 会重复尝试激活连接,做多的次数为autoconnect-retries属性中设置的值。默认为4。 - 如果连接仍然无法获得 DHCP 地址,则自动激活会失败。请注意,5 分钟后,自动连接过程会再次启动,从 DHCP 服务器获取 IP 地址。
- 如果连接的
可选:配置如果网络管理器(NetworkManager)在超时前没有接收 IPv6 地址时的行为:
xxxxxxxxxx# nmcli connection modify connection_name ipv6.may-fail value
其它资源
- 有关这部分所述属性的详情,请查看
nm-settings(5)man page。
第 12 章 管理 Wi-Fi 连接
这部分论述了如何配置和管理 Wi-Fi 连接。
12.1. 设置无线规范域
在 Red Hat Enterprise Linux 中,crda 软件包包含中央常规域代理,它为内核提供给定的无线管理规则。某些 udev 脚本使用它,且不应手动运行,除非要调试 udev 脚本。内核在新规范域更改时发送 udev 事件来运行 crda。规范域更改由 Linux 无线子系统(IEEE-802.11)触发。这个子系统使用 regulatory.bin 文件保存其规范的数据库信息。
setregdomain 工具为您的系统设置规范域。Setregdomain 不使用任何参数,通常通过系统脚本调用,比如 udev,而不是管理员手动调用。如果无法找到某个国家代码,系统管理员可以在 /etc/sysconfig/regdomain 文件中定义 COUNTRY 环境变量。
其它资源
有关规范域的更多信息,请参见以下手册页:
setregdomain(1)man page - 根据地区代码设置规范域。crda(8)man page - 发送至内核的给定 ISO 或者 IEC 3166 alpha2 的无线管理域。regulatory.bin(5)man page - 显示 Linux 无线法规数据库。iw(8)man page - 显示或者操作无线设备及其配置。
12.2. 使用 nmcli 配置 Wi-Fi 连接
这个步骤描述了如何使用 nmcli 配置 Wi-fi 连接配置集。
先决条件
安装了 nmcli 工具。
确保 WiFi 被启用(默认):
xxxxxxxxxx~]$ nmcli radio wifi on
流程
使用静态
IP配置创建 Wi-Fi 连接配置集:xxxxxxxxxx~]$ nmcli con add con-name MyCafe ifname wlan0 type wifi ssid MyCafe ' 'ip4 192.168.100.101/24 gw4 192.168.100.1设置一个 DNS 服务器。例如,将
192.160.100.1设置为 DNS 服务器:xxxxxxxxxx~]$ nmcli con modify con-name MyCafe ipv4.dns "192.160.100.1"另外,还可设置 DNS 搜索域。例如,要将搜索域设置为
example.com:xxxxxxxxxx~]$ nmcli con modify con-name MyCafe ipv4.dns-search "example.com"要检查特定属性,如
mtu:xxxxxxxxxx~]$ nmcli connection show id MyCafe | grep mtu802-11-wireless.mtu: auto更改设置的属性:
xxxxxxxxxx~]$ nmcli connection modify id MyCafe 802-11-wireless.mtu 1350验证更改:
xxxxxxxxxx~]$ nmcli connection show id MyCafe | grep mtu802-11-wireless.mtu: 1350
验证步骤
使用
ping实用程序验证这个主机是否可以向其他主机发送数据包。查找同一子网中的 IP 地址。例如:
xxxxxxxxxx# ping 192.168.100.103如果命令失败,请验证 IP 和子网的设置。
在远程子网中查找 IP 地址。例如:
xxxxxxxxxx# ping 198.51.16.3如果命令失败,则使用 ping 默认网关来验证设置。
xxxxxxxxxx# ping 192.168.100.1
使用
host实用程序验证名称解析是否正常工作。例如:xxxxxxxxxx# host client.example.com如果命令返回任何错误,如
connection timed out或no servers could be reached,请验证您的 DNS 设置。
其它资源
- 关于属性及其设置的更多信息,请参见
nm-settings(5)手册页。 - 如果磁盘中的配置与设备中的配置不匹配,则启动或重启 NetworkManager 会创建一个代表该设备的配置的内存连接。有关详情以及如何避免此问题,请参阅 NetworkManager 服务重启后复制连接。
12.3. 使用 control-center 配置 Wi-Fi 连接
当您连接到 Wi-Fi时,会根据当前的网络连接预先填充网络设置。这意味着当接口连接到网络时会自动探测到设置。
此流程描述了如何使用 control-center 手动配置 Wi-Fi 设置。
流程
按 Super 键输入
Activities Overview,输入Wi-Fi并按 Enter 键。在左侧的菜单条目中您可以看到可用的网络列表。选择您要编辑的
Wi-Fi连接名称右侧的 gear wheel 图标,此时会出现编辑连接对话框。Details 菜单窗口显示您可以进行进一步配置的连接详情。选项
如果您选择
Connect automatically,无论 NetworkManager 检测到可用的连接时 网络管理器(NetworkManager )自动连接到这个连接。如果您不希望 NetworkManager 自动连接,请清除复选框。请注意,当这个复选框清除时,您必须在网络连接图标的菜单中手动选择那个连接以便连接。要使连接可供其他用户使用,请选择
Make available to other users复选框。您还可以控制背景数据的使用。如果您保留
Restrict background data usage未指定(默认),则 NetworkManager 会尝试下载正在使用的主动数据。否则,选择复选框, NetworkManager 会将连接设置为 metered,并在后台数据用量中应用限制。注意
要删除
Wi-Fi连接,请点击Forget Connection红色复选框。
选择 Identity 菜单项来查看基本配置选项。
SSID- 接入点(AP)的服务集合标识符 (SSID)。BSSID- Basic Service Set Identifier (BSSID)是您要在Infrastructure模式中连接到 的特定无线访问点的 MAC 地址(也称为硬件 地址)。默认情况下,该字段为空白,您可以在无需指定BSSID的情况下连接到SSID的无线接入点。如果指定了 BSSID,它将强制系统只关联到特定的接入点。对于临时网络,BSSID在创建 ad-hoc 网络时由 mac80211 子系统随机生成。网络管理器(NetworkManager)不显示它。MAC address- MAC 地址 允许您将特定的无线适配器与特定连接(或者连接)关联。Cloned Address- 采用克隆的 MAC 地址替换真实硬件地址。保留空白,除非需要。要进行进一步的 IP 地址配置,请选择 IPv4 和 IPv6 菜单项。
默认情况下,根据当前的网络设置,
IPv4和IPv6都被设置为自动配置。这意味着,当接口连接到网络时,会自动检测到本地 IP 地址、DNS 地址和其他设置。如果有 DHCP 服务器在此网络中负责分配 IP 配置,就足够了,但您也可以在IPv4和IPv6设置中提供静态配置。在 IPv4 和 IPv6 菜单条目中,您可以看到以下设置:IPv4 MethodAutomatic (DHCP)- 如果您要连接的网络使用路由器广告(Router Advertisements,RA)或DHCP服务器来分配动态 IP 地址,请选择这个选项。您可以在 Details 菜单条目中看到分配的 IP 地址。Link-Local Only- 如果您要连接的网络没有DHCP服务器且您不想手动分配 IP 地址,请选择这个选项。随机地址将根据 RFC 3927 分配前缀169.254/16。Manual- 如果要手动分配 IP 地址,请选择这个选项。Disable-IPv4在这个连接中被禁用。
DNS如果
Automatic是ON,且没有可用的 DHCP 服务器为这个连接分配 DNS 服务器,请将其切换到OFF来输入用逗号分开的 DNS 服务器的 IP 地址。Routes请注意,在
Routes部分,当Automatic为ON时,会使用来自路由器适配器(RA)或 DHCP 的路由,但您也可以添加其他静态路由。当为OFF时,只使用静态路由。Address- 输入远程网络、子网络或主机的IP地址。Netmask- 以上输入的 IP 地址的子网掩码或前缀长度。Gateway- 上面输入的远程网络、子网络或者主机的网关的 IP 地址。Metric- 网络成本,为这个路由赋予的首选值。数值越低,优先级越高。
Use this connection only for resources on its network选择这个复选框以防止连接成为默认路由。
另外,要在
Wi-Fi连接中配置IPv6设置,请选择 IPv6 菜单条目:IPv6 MethodAutomatic- 选择这个选项使用IPv6Stateless Address AutoConfiguration(SLAAC)根据硬件地址和路由器公告(RA)创建自动的、无状态的配置。Automatic, DHCP only- 选择这个选项以不使用 RA,但从DHCPv6请求信息以创建有状态的配置。Link-Local Only- 如果您要连接的网络没有DHCP服务器且您不想手动分配 IP 地址,请选择这个选项。随机地址将根据 RFC 4862 进行分配,前缀为FE80::0。Manual- 如果要手动分配 IP 地址,请选择这个选项。Disable-IPv6在这个连接中被禁用。
DNS、Routes、Use this connection only for resources on its network字段是IPv4设置通用的。
要在连接
Wi-Fi连接中配置Security设置,请选择 Security 菜单条目。可用的配置选项如下:安全性
None- 不加密 Wi-Fi 连接。WEP 40/128-bit Key— Wired Equivalent Privacy(WEP),来自 IEEE 802.11 标准。使用单一预共享密钥(PSK)。WEP 128-bit Passphrase- 生成 WEP 密钥的密码短语的 MD5 哈希。警告
如果
Wi-Fi没有使用加密机制(如WEP或者WPA),则不要使用网络,因为它不安全,且任何人都可以读取您通过这个网络发送的数据。LEAP- 轻量级扩展认证协议,来自 Cisco 系统。Dynamic WEP (802.1X)- 动态更改 WEP 密钥。WPA & WPA2 Personal— Wi-Fi Protected Access(WPA),来自 IEEE 802.11i 标准草稿。一个 WEP 的替换。Wi-Fi Protected Access II(WPA2),来自于 802.11i-2004 标准。个人模式,使用预共享密钥(WPA-PSK)。WPA & WPA2 Enterprise- 与 RADIUS 验证服务器一起使用的 WPA 提供 IEEE 802.1X 网络访问控制。
Password - 输入要在验证过程中使用的密码。
完成配置后,点 应用 按钮保存配置。
注意
当您点 加号 按钮添加新连接时, NetworkManager 会为那个连接创建新配置文件,然后打开同一个对话框来编辑现有连接。这两个对话框之间的区别在于现有连接配置集有详情菜单条目。
12.4. 使用 nmcli 连接到 Wi-Fi 网络
这个步骤描述了如何使用 nmcli 实用程序连接到 wireless 连接。
先决条件
安装了 nmcli 工具。
确保 WiFi 被启用(默认):
xxxxxxxxxx~]$ nmcli radio wifi on
流程
刷新可用的 Wi-Fi 连接列表:
xxxxxxxxxx~]$ nmcli device wifi rescan查看可用的 Wi-Fi 接入点:
xxxxxxxxxx~]$ nmcli dev wifi listIN-USE SSID MODE CHAN RATE SIGNAL BARS SECURITY...MyCafe Infra 3 405 Mbit/s 85 ▂▄▆█ WPA1 WPA2使用 nmcli 连接到 Wi-Fi 连接:
xxxxxxxxxx~]$ nmcli dev wifi connect SSID-Name password wireless-password例如:
xxxxxxxxxx~]$ nmcli dev wifi connect MyCafe password wireless-password请注意,如果要禁用 Wi-Fi 状态:
xxxxxxxxxx~]$ nmcli radio wifi off
12.5. 使用 nmcli 连接到隐藏的 Wi-Fi 网络
所有接入点都有一个 Service Set Identifier(SSID)来识别它们。然而,接入点可以被配置为不广播其 SSID,在这种情况下,它会被隐藏,且不会出现在网络管理器(NetworkManager)的可用网络列表中。
此步骤演示了如何使用 nmcli 工具连接到隐藏网络。
先决条件
安装了 nmcli 工具。
了解 SSID,以及
Wi-Fi连接的密码。确保 WiFi 被启用(默认):
xxxxxxxxxx~]$ nmcli radio wifi on
流程
连接到隐藏的 SSID:
xxxxxxxxxx~]$ nmcli dev wifi connect SSID_Name password wireless_password hidden yes
12.6. 使用 GNOME GUI 连接至 Wi-Fi 网络
这个步骤描述了如何连接到无线网络以访问互联网。
流程
在屏幕右上角打开 GNOME Shell 网络连接图标菜单。
选择
Wi-Fi Not Connected。点击
Select Network选项。点击您要连接的网络名称,然后点击
Connect。请注意,如果没有看到网络,则网络可能是隐藏的。
如果网络需要密码或密钥保护,请输入密码并点击
Connect。请注意:如果您不知道密码,请联络 Wi-Fi 网络的管理员。
如果连接成功,则会在连接图标菜单中看到网络连接,无线指示符位于屏幕右上角。
其它资源
第 13 章 使用 802.1X 标准向网络验证 RHEL 客户端
管理员通常使用基于 IEEE 802.1X 标准的基于端口的网络访问控制(NAC)来保护网络不受未授权 LAN 和 Wi-Fi 客户端的影响。本节中的步骤描述了配置网络身份验证的不同选项。
13.1. 使用 nmcli 在现有以太网连接中配置 802.1X 网络身份验证
使用 nmcli 工具,您可以配置客户端向网络验证其自身。这个过程描述了如何在现有名为 enp1s0 的 NetworkManager 以太网连接配置集中使用微软 Challenge-Handshake Authentication Protocol 版本 2(MSCHAPv2) 配置保护扩展验证协议(PEAP)验证。
先决条件
- 网络必须具有 802.1X 网络身份验证。
- 以太网连接配置集存在于 NetworkManager 中,且具有有效的 IP 配置。
- 如果需要客户端验证验证程序证书,则必须将证书颁发机构(CA)证书存储在
/etc/pki/ca-trust/source/anchors/目录中。 - 已安装
wpa_supplicant软件包。
流程
将扩展验证协议(EAP)设置为
peap,内部验证协议为mschapv2,用户名为:xxxxxxxxxx# nmcli connection modify enp1s0 802-1x.eap peap 802-1x.phase2-auth mschapv2 802-1x.identity user_name请注意,您必须在单个命令中设置
802-1x.eap、802-1x.phase2-auth和802-1x.identity参数。另外,还可将该密码存储在配置中:
xxxxxxxxxx# nmcli connection modify enp1s0 802-1x.password password重要
默认情况下,网络管理器(NetworkManager)在
/etc/sysconfig/network-scripts/keys-*connection_name*文件中以明文形式保存密码,这只可由root用户读取。但是,在配置文件中清除文本密码会有安全隐患。要提高安全性,将
802-1x.password-flags参数设置为0x1。使用这个设置,在有 GNOME 桌面环境或nm-applet的服务器上,NetworkManager 从这些服务中检索密码。在其他情况下,NetworkManager 会提示输入密码。如果需要客户端验证验证器的证书,请将连接配置集中的
802-1x.ca-cert参数设置为 CA 证书的路径:xxxxxxxxxx# nmcli connection modify enp1s0 802-1x.ca-cert /etc/pki/ca-trust/source/anchors/ca.crt注意
为了安全起见,红帽建议使用验证程序证书来使客户端能够验证验证器的身份。
激活连接配置集:
xxxxxxxxxx# nmcli connection up enp1s0
验证步骤
- 访问需要网络身份验证的网络上的资源。
其它资源
- 有关添加网络管理器以太网连接配置集的详情,请参考 第 11 章 配置以太网连接。
- 有关 802.1X 相关参数及其描述,请查看
nm-settings(5)man page 中的802-1x settings部分。 - 有关
nmcli工具程序的详情,请查看nmcli(1)man page。
13.2. 使用 RHEL 系统角色通过 802.1X 网络身份验证配置静态以太网连接
使用 RHEL 系统角色,您可以自动创建使用 802.1X 标准验证客户端的以太网连接。此流程描述了如何通过运行 Ansible playbook 来远程为带有以下设置的 enp1s0 接口添加以太网连接:
- 静态 IPv4 地址 -
192.0.2.1,子网掩码为/24 - 静态 IPv6 地址 -
2001:db8:1::1,子网掩码为/64 - IPv4 默认网关 -
192.0.2.254 - IPv6 默认网关 -
2001:db8:1::fffe - IPv4 DNS 服务器 -
192.0.2.200 - IPv6 DNS 服务器 -
2001:db8:1::ffbb - DNS 搜索域 -
example.com - 802.1X 网络验证使用
TLS可扩展验证协议(EAP)
在 Ansible 控制节点上运行此步骤。
先决条件
在控制节点上安装
ansible和rhel-system-roles软件包。如果您运行 playbook 时使用了与
root不同的远程用户, 则此用户在受管节点上需要具有适当的sudo权限。网络支持 802.1X 网络身份验证。
受管节点使用 NetworkManager。
control 节点上存在 TLS 身份验证所需的以下文件:
- 保存在
/srv/data/client.key文件中的客户端密钥。 - 存储在
/srv/data/client.crt文件中的客户端证书。 - 存储在
/srv/data/ca.crt文件中的证书颁发机构(CA)证书。
- 保存在
流程
如果 playbook 要针对其执行的主机还没有在清单中,请将此主机的 IP 地址或名称添加到
/etc/ansible/hostsAnsible 清单文件中:xxxxxxxxxxnode.example.com使用以下内容创建
~/enable-802.1x.ymlplaybook:xxxxxxxxxx---- name: Configure an Ethernet connection with 802.1X authenticationhosts: node.example.combecome: truetasks:- name: Copy client key for 802.1X authenticationcopy:src: "/srv/data/client.key"dest: "/etc/pki/tls/private/client.key"mode: 0600- name: Copy client certificate for 802.1X authenticationcopy:src: "/srv/data/client.crt"dest: "/etc/pki/tls/certs/client.crt"- name: Copy CA certificate for 802.1X authenticationcopy:src: "/srv/data/ca.crt"dest: "/etc/pki/ca-trust/source/anchors/ca.crt"- include_role:name: linux-system-roles.networkvars:network_connections:- name: enp1s0type: ethernetautoconnect: yesip:address:- 192.0.2.1/24- 2001:db8:1::1/64gateway4: 192.0.2.254gateway6: 2001:db8:1::fffedns:- 192.0.2.200- 2001:db8:1::ffbbdns_search:- example.comieee802_1x:identity: user_nameeap: tlsprivate_key: "/etc/pki/tls/private/client.key"private_key_password: "password"client_cert: "/etc/pki/tls/certs/client.crt"ca_cert: "/etc/pki/ca-trust/source/anchors/ca.crt"domain_suffix_match: example.comstate: up运行 playbook:
以
root用户身份连接到受管主机,输入:xxxxxxxxxx# ansible-playbook -u root ~/enable-802.1x.yml以用户身份连接到受管主机,请输入:
xxxxxxxxxx# ansible-playbook -u user_name --ask-become-pass ~/ethernet-static-IP.yml--ask-become-pass选项定义ansible-playbook命令提示输入-u *user_name*选项定义的用户sudo密码。
如果没有指定
-u *user_name*选项,请以当前登录到控制节点的用户ansible-playbook连接到受管主机。
其它资源
- 有关使用的参数
network_connections以及network系统角色的额外信息,请查看/usr/share/ansible/roles/rhel-system-roles.network/README.md文件。 - 有关 802.1X 参数的详情,请查看文件
ieee802_1x中的/usr/share/ansible/roles/rhel-system-roles.network/README.md部分。 - 有关
ansible-playbook命令的详情请参考ansible-playbook(1)man page。
13.3. 使用 nmcli 在现有 Wi-Fi 连接中配置 802.1X 网络身份验证
使用 nmcli 工具,您可以配置客户端向网络验证其自身。这个过程描述了如何在现有名为 wlp1s0 的 NetworkManager Wi-Fi 连接配置集中使用微软 Challenge-Handshake Authentication Protocol 版本 2(MSCHAPv2) 配置保护扩展验证协议(PEAP)验证。
先决条件
- 网络必须具有 802.1X 网络身份验证。
- Wi-Fi 连接配置集存在于 NetworkManager 中,且具有有效的 IP 配置。
- 如果需要客户端验证验证程序证书,则必须将证书颁发机构(CA)证书存储在
/etc/pki/ca-trust/source/anchors/目录中。 - 已安装
wpa_supplicant软件包。
流程
将 Wi-Fi 安全模式设置为
wpa-eap,可扩展验证协议(EAP)设置为peap,内部验证协议为mschapv2,以及用户名:xxxxxxxxxx# nmcli connection modify wpl1s0 802-11-wireless-security.key-mgmt wpa-eap 802-1x.eap peap 802-1x.phase2-auth mschapv2 802-1x.identity user_name请注意,您必须在单个命令中设置
802-11-wireless-security.key-mgmt、802-1x.eap、802-1x.phase2-auth和802-1x.identity参数。另外,还可将该密码存储在配置中:
xxxxxxxxxx# nmcli connection modify wpl1s0 802-1x.password password重要
默认情况下,网络管理器(NetworkManager)在
/etc/sysconfig/network-scripts/keys-*connection_name*文件中以明文形式保存密码,这只可由root用户读取。但是,在配置文件中清除文本密码会有安全隐患。要提高安全性,将
802-1x.password-flags参数设置为0x1。使用这个设置,在有 GNOME 桌面环境或nm-applet的服务器上,NetworkManager 从这些服务中检索密码。在其他情况下,NetworkManager 会提示输入密码。如果需要客户端验证验证器的证书,请将连接配置集中的
802-1x.ca-cert参数设置为 CA 证书的路径:xxxxxxxxxx# nmcli connection modify wpl1s0 802-1x.ca-cert /etc/pki/ca-trust/source/anchors/ca.crt注意
为了安全起见,红帽建议使用验证程序证书来使客户端能够验证验证器的身份。
激活连接配置集:
xxxxxxxxxx# nmcli connection up wpl1s0
验证步骤
- 访问需要网络身份验证的网络上的资源。
其它资源
- 有关添加网络管理器以太网连接配置集的详情,请参考 第 12 章 管理 Wi-Fi 连接。
- 有关 802.1X 相关参数及其描述,请查看
nm-settings(5)man page 中的802-1x settings部分。 - 有关
nmcli工具程序的详情,请查看nmcli(1)man page。
第 14 章 设置现有连接的默认网关
在大多数情况下,管理员在创建连接时设置默认网关。但是,您也可以在创建连接后设置默认网关。
这部分论述了如何设置现有网络连接的默认网关。
14.1. 使用 nmcli 在现有连接上设置默认网关
在大多数情况下,管理员在创建连接时设置默认网关,如 第 11.1 节 “使用 nmcli 配置静态以太网连接” 所述。
本节论述了如何使用 nmcli 实用程序在之前创建的连接中设置或更新默认网关。
先决条件
- 至少需要在设置默认网关的连接上配置一个静态 IP 地址。
- 如果用户在物理控制台中登录,用户权限就足够了。否则,用户必须拥有
root权限。
流程
设置默认网关的 IP 地址。
例如,要将
*example*连接中默认网关的 IPv4 地址设置为192.0.2.1:xxxxxxxxxx$ sudo nmcli connection modify example ipv4.gateway "192.0.2.1"例如,要将
*example*连接中默认网关的 IPv6 地址设置为2001:db8:1::1:xxxxxxxxxx$ sudo nmcli connection modify example ipv6.gateway "2001:db8:1::1"重启网络连接以使更改生效。例如,要使用命令行重启
*example*连接:xxxxxxxxxx$ sudo nmcli connection up example警告
所有目前使用这个网络连接的连接在重启过程中暂时中断。
(可选)验证路由是否活跃。
显示 IPv4 默认网关:
xxxxxxxxxx$ ip -4 routedefault via 192.0.2.1 dev example proto static metric 100显示 IPv6 默认网关:
xxxxxxxxxx$ ip -6 routedefault via 2001:db8:1::1 dev example proto static metric 100 pref medium
其它资源
14.2. 使用 nmcli 互动模式在现有连接上设置默认网关
在大多数情况下,管理员在创建连接时设置默认网关,如 第 11.5 节 “使用 nmcli 互动编辑器配置动态以太网连接” 所述。
本节论述了如何使用 nmcli 工具的互动模式在之前创建的连接中设置或更新默认网关。
先决条件
- 至少需要在设置默认网关的连接上配置一个静态 IP 地址。
- 如果用户在物理控制台中登录,用户权限就足够了。否则,该用户必须具有
root权限。
流程
为所需连接打开
nmcli互动模式。例如,要为 example 连接打开nmcli互动模式:xxxxxxxxxx$ sudo nmcli connection edit example设置默认网关。
例如,要将
*example*连接中默认网关的 IPv4 地址设置为192.0.2.1:xxxxxxxxxxnmcli> set ipv4.gateway 192.0.2.1例如,要将
*example*连接中默认网关的 IPv6 地址设置为2001:db8:1::1:xxxxxxxxxxnmcli> set ipv6.gateway 2001:db8:1::1另外,还可验证默认网关是否正确设置:
xxxxxxxxxxnmcli> print...ipv4.gateway: 192.0.2.1...ipv6.gateway: 2001:db8:1::1...保存配置:
xxxxxxxxxxnmcli> save persistent重启网络连接以使更改生效:
xxxxxxxxxxnmcli> activate example警告
所有目前使用这个网络连接的连接在重启过程中暂时中断。
保留
nmcli互动模式:xxxxxxxxxxnmcli> quit(可选)验证路由是否活跃。
显示 IPv4 默认网关:
xxxxxxxxxx$ ip -4 routedefault via 192.0.2.1 dev example proto static metric 100显示 IPv6 默认网关:
xxxxxxxxxx$ ip -6 routedefault via 2001:db8:1::1 dev example proto static metric 100 pref medium
其它资源
14.3. 使用 nm-connection-editor 在现有连接上设置默认网关
在大多数情况下,管理员在创建连接时设置默认网关。本节论述了如何使用 nm-connection-editor 实用程序在之前创建的连接中设置或更新默认网关。
先决条件
- 至少需要在设置默认网关的连接上配置一个静态 IP 地址。
流程
打开终端窗口,输入
nm-connection-editor:xxxxxxxxxx$ nm-connection-editor选择要修改的连接,并点击 gear wheel 图标编辑现有连接。
设置 IPv4 默认网关。例如,要将连接中默认网关的 IPv4 地址设置为
192.0.2.1:打开
IPv4 Settings标签。在
gateway字段中输入网关地址在其中 IP 范围旁的地址:
设置 IPv6 默认网关。例如,要将连接中默认网关的 IPv6 地址设置为
2001:db8:1::1:打开
IPv6标签。在
gateway字段中输入网关地址在其中 IP 范围旁的地址:
点击 确定。
点击 Save。
重启网络连接以使更改生效。例如,要使用命令行重启
*example*连接:xxxxxxxxxx$ sudo nmcli connection up example警告
所有目前使用这个网络连接的连接在重启过程中暂时中断。
(可选)验证路由是否活跃。
显示 IPv4 默认网关:
xxxxxxxxxx$ ip -4 routedefault via 192.0.2.1 dev example proto static metric 100显示 IPv6 默认网关:
xxxxxxxxxx$ ip -6 routedefault via 2001:db8:1::1 dev example proto static metric 100 pref medium
其它资源
14.4. 使用 control-center 在现有连接上设置默认网关
在大多数情况下,管理员在创建连接时设置默认网关。本节论述了如何使用 control-center 应用程序在之前创建的连接中设置或更新默认网关。
先决条件
- 至少需要在设置默认网关的连接上配置一个静态 IP 地址。
- 连接的网络配置在
control-center应用程序中打开。
流程
设置 IPv4 默认网关。例如,要将连接中默认网关的 IPv4 地址设置为
192.0.2.1:打开
IPv4标签页。在
gateway字段中输入网关地址在其中 IP 范围旁的地址:
设置 IPv6 默认网关。例如,要将连接中默认网关的 IPv6 地址设置为
2001:db8:1::1:打开
IPv6标签。在
gateway字段中输入网关地址在其中 IP 范围旁的地址:
点击 应用。
在
Network窗口中,通过将连接到 Off 的按钮切换为 Off 并返回 On 来禁用并重新启用连接,以使 更改 生效。警告
所有目前使用这个网络连接的连接在重启过程中暂时中断。
(可选)验证路由是否活跃。
显示 IPv4 默认网关:
xxxxxxxxxx$ ip -4 routedefault via 192.0.2.1 dev example proto static metric 100显示 IPv6 默认网关:
xxxxxxxxxx$ ip -6 routedefault via 2001:db8:1::1 dev example proto static metric 100 pref medium
其它资源
14.5. 使用旧的网络脚本在现有连接中设置默认网关
这个步骤描述了如何使用旧的网络脚本配置默认网关。示例将默认网关设置为 192.0.2.1,可通过 enp1s0 接口访问。
先决条件
- 未安装
NetworkManager软件包,或者NetworkManager服务被禁用。 - 已安装
network-scripts软件包。
流程
将
/etc/sysconfig/network-scripts/ifcfg-enp1s0文件中的GATEWAY参数设置为192.0.2.1:xxxxxxxxxxGATEWAY=192.0.2.1在
default文件中添加/etc/sysconfig/network-scripts/route-enp0s1条目:xxxxxxxxxxdefault via 192.0.2.1重启网络:
xxxxxxxxxx# systemctl restart network
第 15 章 配置静态路由
默认情况下,如果配置了默认网关,Red Hat Enterprise Linux 会将没有直接连接到主机的网络流量转发到默认网关。使用静态路由,您可以配置 Red Hat Enterprise Linux 将特定主机或网络的流量转发到不同于默认网关的不同路由器。本节论述了配置静态路由的不同选项。
15.1. 如何使用 nmcli 命令配置静态路由
要配置静态路由,请使用以下语法的 nmcli 工具:
xxxxxxxxxx$ nmcli connection modify connection_name ipv4.routes "ip[/prefix] [next_hop] [metric] [attribute=value] [attribute=value] ..."
该命令支持以下路由属性:
table=*n*src=*address*tos=*n*onlink=true|falsewindow=*n*cwnd=*n*mtu=*n*lock-window=true|falselock-cwdn=true|falselock-mtu=true|false
如果您使用 ipv4.routes 子命令,nmcli 会覆盖这个参数的所有当前设置。要添加额外路由,请使用 nmcli connection modify *connection_name* +ipv4.routes "…" 命令。同样,您可以使用 nmcli connection modify *connection_name* -ipv4.routes "…" 删除特定路由。
15.2. 使用 nmcli 命令配置静态路由
您可以使用 nmcli connection modify 命令在网络连接配置中添加静态路由。
本节中的步骤论述了如何将路由添加到使用 192.0.2.0/24 运行网关的 198.51.100.1 网络,这些网关可通过 example 连接访问。
先决条件
- 网络已配置
- 静态路由的网关必须在接口上直接访问。
- 如果用户在物理控制台中登录,用户权限就足够了。否则,命令需要
root权限。
流程
将静态路由添加到
example连接:xxxxxxxxxx$ sudo nmcli connection modify example +ipv4.routes "192.0.2.0/24 198.51.100.1"要在一个步骤中设置多个路由,使用逗号分隔单个路由传递给该命令。例如,要将路由添加到
192.0.2.0/24和203.0.113.0/24网络(都通过198.51.100.1网关路由),请输入:xxxxxxxxxx$ sudo nmcli connection modify example +ipv4.routes "192.0.2.0/24 198.51.100.1, 203.0.113.0/24 198.51.100.1"(可选)验证路由是否已正确添加到配置中:
xxxxxxxxxx$ nmcli connection show example...ipv4.routes: { ip = 192.0.2.1/24, nh = 198.51.100.1 }...重启网络连接:
xxxxxxxxxx$ sudo nmcli connection up example警告
重启连接会破坏那个接口的连接。
(可选)验证路由是否活跃:
xxxxxxxxxx$ ip route...192.0.2.0/24 via 198.51.100.1 dev example proto static metric 100
其它资源
- 有关
nmcli的详情,请查看nmcli(1)man page。
15.3. 使用 control-center 配置静态路由
您可以在 GNOME 中使用 control-center 来添加到网络连接配置的静态路由。
本节中的步骤论述了如何将路由添加到使用 198.51.100.1 运行的网关的 192.0.2.0/24 网络。
先决条件
- 网络已配置。
- 静态路由的网关必须在接口上直接访问。
- 连接的网络配置在
control-center应用程序中打开。请参阅 第 11.8 节 “使用 nm-connection-editor 配置以太网连接”。
流程
打开
IPv4标签页。(可选)通过点击
IPv4标签中的Routes项中的 On 按钮来禁用自动路由,只使用静态路由。如果启用了自动路由,Red Hat Enterprise Linux 将使用静态路由和从 DHCP 服务器接收的路由。输入地址、子网掩码、网关和可选的指标值:

点击 应用。
在
Network窗口中,通过将连接到 Off 的按钮切换为 Off 并返回 On 来禁用并重新启用连接,以使 更改 生效。警告
重启连接会破坏那个接口的连接。
(可选)验证路由是否活跃:
xxxxxxxxxx$ ip route...192.0.2.0/24 via 198.51.100.1 dev example proto static metric 100
15.4. 使用 nm-connection-editor 配置静态路由
您可以使用 nm-connection-editor 应用程序为网络连接配置添加静态路由。
本节中的步骤论述了如何将路由添加到使用 192.0.2.0/24 运行网关的 198.51.100.1 网络,这些网关可通过 example 连接访问。
先决条件
- 网络已配置。
- 静态路由的网关必须在接口上直接访问。
流程
打开终端窗口并输入
nm-connection-editor:xxxxxxxxxx$ nm-connection-editor选择
example连接并点击 gear wheel 图标编辑现有连接。打开
IPv4标签页。点击 路由 按钮。
点击 添加 按钮并输入地址、子网掩码、网关以及可选的指标值。

点击 确定。
点击 Save。
重启网络连接以使更改生效。例如,要使用命令行重启
example连接:xxxxxxxxxx$ sudo nmcli connection up example(可选)验证路由是否活跃:
xxxxxxxxxx$ ip route...192.0.2.0/24 via 198.51.100.1 dev example proto static metric 100
15.5. 使用 nmcli 互动模式配置静态路由
您可以使用 nmcli 程序的互动模式将静态路由添加到网络连接配置中。
本节中的步骤论述了如何将路由添加到使用 192.0.2.0/24 运行网关的 198.51.100.1 网络,这些网关可通过 example 连接访问。
先决条件
- 网络已配置
- 静态路由的网关必须在接口上直接访问。
- 如果用户在物理控制台中登录,用户权限就足够了。否则,命令需要
root权限。
流程
为
example连接打开nmcli互动模式:xxxxxxxxxx$ sudo nmcli connection edit example添加静态路由:
xxxxxxxxxxnmcli> set ipv4.routes 192.0.2.0/24 198.51.100.1(可选)验证路由是否已正确添加到配置中:
xxxxxxxxxxnmcli> print...ipv4.routes: { ip = 192.0.2.1/24, nh = 198.51.100.1 }...ip属性显示了要路由的网络,nh属性显示了网关(下一跳)。保存配置:
xxxxxxxxxxnmcli> save persistent重启网络连接:
xxxxxxxxxxnmcli> activate example警告
当您重启连接时,所有当前使用这个连接的连接将会被暂时中断。
保留
nmcli互动模式:xxxxxxxxxxnmcli> quit(可选)验证路由是否活跃:
xxxxxxxxxx$ ip route...192.0.2.0/24 via 198.51.100.1 dev example proto static metric 100
其它资源
- 有关互动模式中可用命令列表,请在互动 shell 中输入
help。
15.6. 使用旧的网络脚本以 key-value-format 创建静态路由配置文件
这个步骤描述了,在使用旧的网络脚本而不是 NetworkManager 时,如何手动为 192.0.2.0/24 网络的 IPv4 路由创建路由配置文件。在这个示例中,IP 地址为 198.51.100.1 的对应网关可以通过 enp1s0 接口访问。
此流程中的示例使用 key-value-format 中的配置条目。
注意
旧的网络脚本只支持静态 IPv4 路由的键值格式。对于 IPv6 路由,请使用 ip-command-format。请参阅 第 15.7 节 “在使用旧的网络脚本时,使用 ip-command-format 创建静态路由配置文件”。
先决条件
- 静态路由的网关必须在接口上直接访问。
- 未安装
NetworkManager软件包,或者NetworkManager服务被禁用。 - 已安装
network-scripts软件包。
流程
将静态 IPv4 路由添加到
/etc/sysconfig/network-scripts/route-enp0s1文件:xxxxxxxxxxADDRESS0=192.0.2.0NETMASK0=255.255.255.0GATEWAY0=198.51.100.1ADDRESS0变量定义第一个路由条目的网络。NETMASK0变量定义第一个路由条目的子网掩码。GATEWAY0变量定义了到远程网络或主机的网关 IP 地址,用于第一个路由条目。如果您添加了多个静态路由,请在变量名称中增加其数量。请注意,每个路由的变量都必须按顺序编号。例如,
ADDRESS0、ADDRESS1、ADDRESS3等。
重启网络:
xxxxxxxxxx# systemctl restart network
其它资源
- 有关配置旧的网络脚本的详情,请参考
/usr/share/doc/network-scripts/sysconfig.txt文件。
15.7. 在使用旧的网络脚本时,使用 ip-command-format 创建静态路由配置文件
此流程描述了如何使用旧网络脚本为以下静态路由手动创建路由配置文件:
- 到
192.0.2.0/24网络的 IPv4 路由。IP 地址为198.51.100.1的对应网关可以通过enp1s0接口访问。 - 到
2001:db8:1::/64网络的 IPv6 路由。IP 地址为2001:db8:2::1的对应网关可以通过enp1s0接口访问。
以下操作过程的示例使用 ip中的配置条目 -command-format。
先决条件
- 静态路由的网关必须在接口上直接访问。
- 未安装
NetworkManager软件包,或者NetworkManager服务被禁用。 - 已安装
network-scripts软件包。
流程
将静态 IPv4 路由添加到
/etc/sysconfig/network-scripts/route-enp0s1文件:xxxxxxxxxx192.0.2.0/24 via 198.51.100.1 dev enp0s1将静态 IPv6 路由添加到
/etc/sysconfig/network-scripts/route6-enp0s1文件:xxxxxxxxxx2001:db8:1::/64 via 2001:db8:2::1 dev enp0s1重启网络:
xxxxxxxxxx# systemctl restart network
其它资源
- 有关配置旧的网络脚本的详情,请参考
/usr/share/doc/network-scripts/sysconfig.txt文件。
第 16 章 配置基于策略的路由以定义其他路由
默认情况下,RHEL 中的内核决定使用路由表根据目标地址转发网络数据包。基于策略的路由允许您配置复杂的路由场景。例如,您可以根据各种条件路由数据包,如源地址、数据包元数据或协议。
本节论述了如何使用 NetworkManager 配置基于策略的路由。
注意
在使用 NetworkManager 的系统中,只有 nmcli 工具支持设置路由规则,并将路由分配到特定表。
16.1. 使用 NetworkManager 将特定子网的流量路由到不同的默认网关
本节论述了如何将 RHEL 配置为默认路由将所有流量路由到互联网供应商 A 的路由器。使用基于策略的路由,RHEL 会将从内部工作站子网接收的流量路由到供应商 B。
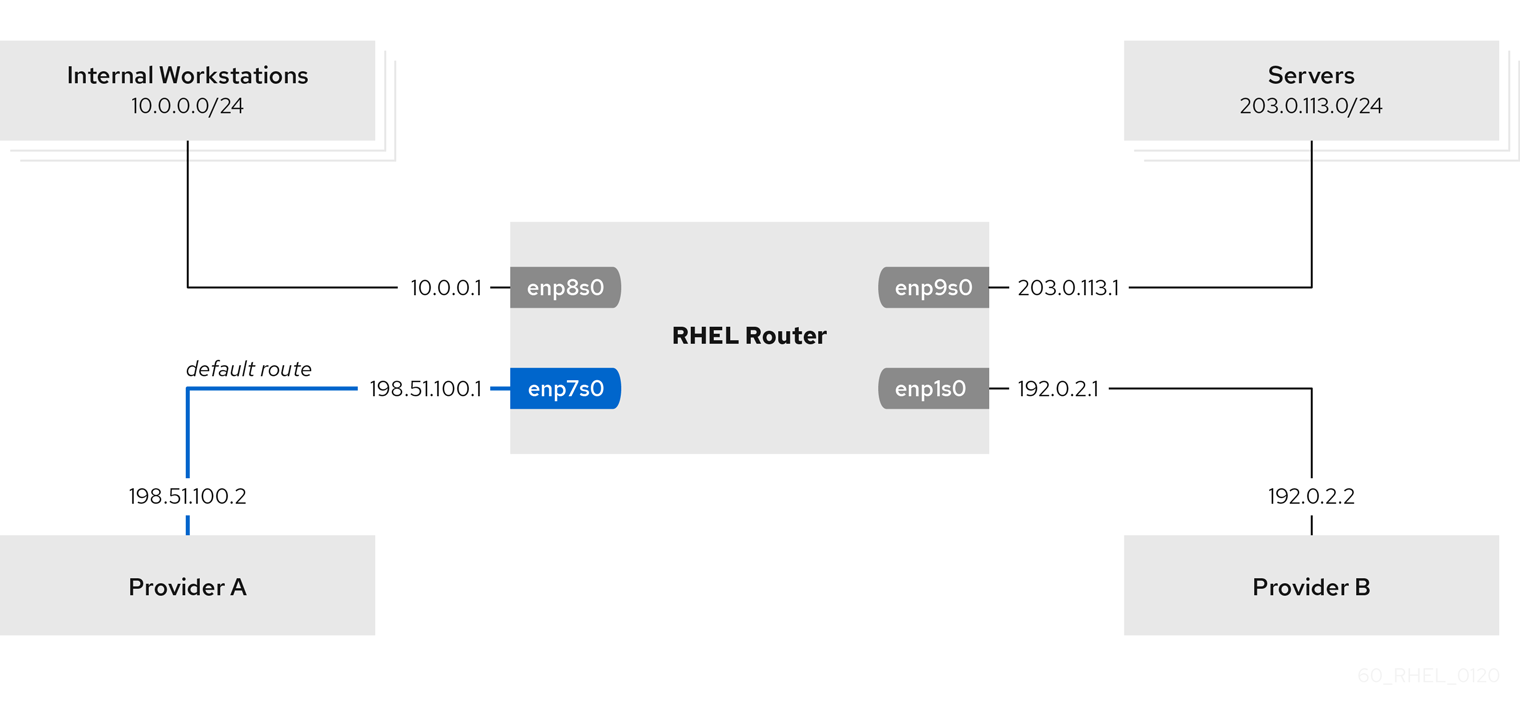
该流程假设以下网络拓扑:
先决条件
系统使用
NetworkManager配置网络,这是 RHEL 8 中的默认设置。要在流程中设置的 RHEL 路由器有四个网络接口:
enp7s0接口连接到供应商 A 的网络。提供商网络中的网关 IP 是198.51.100.2,网络使用了/30网络掩码。enp1s0接口连接到供应商 B 的网络。提供商网络中的网关 IP 是192.0.2.2,网络使用了/30网络掩码。enp8s0接口使用内部工作站连接到10.0.0.0/24子网。enp9s0界面连接到有公司服务器的203.0.113.0/24子网。
内部工作站子网中的主机使用
10.0.0.1作为默认网关。在此过程中,您可以将此 IP 地址分配给路由器的enp8s0网络接口。服务器子网中的主机使用
203.0.113.1作为默认网关。在此过程中,您可以将此 IP 地址分配给路由器的enp9s0网络接口。firewalld服务已启用并激活。
流程
将网络接口配置为供应商 A:
xxxxxxxxxx# nmcli connection add type ethernet con-name Provider-A ifname enp7s0 ipv4.method manual ipv4.addresses 198.51.100.1/30 ipv4.gateway 198.51.100.2 ipv4.dns 198.51.100.200 connection.zone externalnmcli connection add命令创建网络管理器连接配置集。以下列表描述了该命令的选项:typeethernet:定义连接类型是以太网。con-name*connection_name*:设置配置集的名称。使用有意义的名称以避免混淆。ifname*network_device*:设置网络接口。ipv4.methodmanual:允许配置静态 IP 地址。ipv4.addresses*IP_address*/*subnet_mask*:设置 IPv4 地址和子网掩码。ipv4.gateway*IP_address*:设置默认网关地址。ipv4.dns*IP_of_DNS_server*:设置 DNS 服务器的 IPv4 地址。connection.zone*firewalld_zone*:将网络接口分配给定义的firewalld区。请注意,firewalld会自动启用分配给external区的接口的伪装。
将网络接口配置为供应商 B:
xxxxxxxxxx# nmcli connection add type ethernet con-name Provider-B ifname enp1s0 ipv4.method manual ipv4.addresses 192.0.2.1/30 ipv4.routes "0.0.0.0/1 192.0.2.2 table=5000, 128.0.0.0/1 192.0.2.2 table=5000" connection.zone external这个命令使用
ipv4.routes参数而不是ipv4.gateway设置默认网关。这需要为这个连接分配默认网关到不同的路由表(5000)而不是默认路由表。当连接激活时网络管理器(NetworkManager)会自动创建这个新路由表。注意
nmcli实用程序不支持将0.0.0.0/0用于ipv4.gateway的默认网关。要临时解决这个问题,命令为0.0.0.0/1和128.0.0.0/1子网创建独立路由,它们还可覆盖完整的 IPv4 地址空间。将网络接口配置为内部工作站子网:
xxxxxxxxxx# nmcli connection add type ethernet con-name Internal-Workstations ifname enp8s0 ipv4.method manual ipv4.addresses 10.0.0.1/24 ipv4.routes "10.0.0.0/24 src=192.0.2.1 table=5000" ipv4.routing-rules "priority 5 from 10.0.0.0/24 table 5000" connection.zone internal此命令使用
ipv4.routes参数将静态路由添加到路由表(ID5000)。10.0.0.0/24子网的这个静态路由使用本地网络接口的 IP 地址到供应商 B(192.0.2.1)作为下一跳。另外,该命令使用
ipv4.routing-rules参数添加带有优先级5的路由规则,该规则将10.0.0.0/24子网中的流量路由到表5000。低的值具有更高的优先级。请注意,
ipv4.routing-rules参数中的语法与ip route add命令中的语法相同,不过ipv4.routing-rules始终需要指定优先级。将网络接口配置为服务器子网:
xxxxxxxxxx# nmcli connection add type ethernet con-name Servers ifname enp9s0 ipv4.method manual ipv4.addresses 203.0.113.1/24 connection.zone internal
验证步骤
在内部工作站子网的 RHEL 主机上:
安装
traceroute软件包:xxxxxxxxxx# yum install traceroute使用
traceroute工具显示到互联网主机的路由:xxxxxxxxxx# traceroute redhat.comtraceroute to redhat.com (209.132.183.105), 30 hops max, 60 byte packets1 10.0.0.1 (10.0.0.1) 0.337 ms 0.260 ms 0.223 ms2 192.0.2.1 (192.0.2.1) 0.884 ms 1.066 ms 1.248 ms...命令的输出显示路由器通过
192.0.2.1发送数据包,这是供应商 B 的网络。
在服务器子网的 RHEL 主机上:
安装
traceroute软件包:xxxxxxxxxx# yum install traceroute使用
traceroute工具显示到互联网主机的路由:xxxxxxxxxx# traceroute redhat.comtraceroute to redhat.com (209.132.183.105), 30 hops max, 60 byte packets1 203.0.113.1 (203.0.113.1) 2.179 ms 2.073 ms 1.944 ms2 198.51.100.2 (198.51.100.2) 1.868 ms 1.798 ms 1.549 ms...命令的输出显示路由器通过
198.51.100.2发送数据包,这是供应商 A 的网络。
故障排除步骤
在 RHEL 路由器中:
显示规则列表:
xxxxxxxxxx# ip rule list0: from all lookup local5: from 10.0.0.0/24 lookup 500032766: from all lookup main32767: from all lookup default默认情况下,RHEL 包含表
local、main和default的规则。显示表
5000中的路由:xxxxxxxxxx# ip route list table 50000.0.0.0/1 via 192.0.2.2 dev enp1s0 proto static metric 10010.0.0.0/24 dev enp8s0 proto static scope link src 192.0.2.1 metric 102128.0.0.0/1 via 192.0.2.2 dev enp1s0 proto static metric 100显示接口和防火墙区:
xxxxxxxxxx# firewall-cmd --get-active-zonesexternalinterfaces: enp1s0 enp7s0internalinterfaces: enp8s0 enp9s0验证
external区是否启用了伪装:xxxxxxxxxx# firewall-cmd --info-zone=externalexternal (active)target: defaulticmp-block-inversion: nointerfaces: enp1s0 enp7s0sources:services: sshports:protocols:masquerade: yes...
其它资源
- 有关您可以在
nmcli connection add命令中设置的ipv4.*参数的详情,请查看nm-settings(5)man page 中的IPv4 settings部分。 - 有关您可以在
nmcli connection add命令中设置的connection.*参数的详情,请查看nm-settings(5)man page 中的Connection settings部分。 - 有关使用
nmcli管理网络管理器连接的详情,请参考nmcli(1)man page 中的Connection management commands部分。
16.2. 使用旧网络脚本时,涉及基于策略的路由的配置文件概述
如果您使用旧的网络脚本而不是 NetworkManager 配置网络,您也可以配置基于策略的路由。
注意
使用 network-scripts 软件包(在 RHEL 8 中已弃用)提供的旧网络脚本配置网络。红帽建议您使用 NetworkManager 配置基于策略的路由。请参阅 第 16.1 节 “使用 NetworkManager 将特定子网的流量路由到不同的默认网关” 提供的示例。
使用旧的网络脚本时,以下配置文件会涉及基于策略的路由:
/etc/sysconfig/network-scripts/route-*interface*:此文件定义 IPv4 路由。使用table选项指定路由表。例如:xxxxxxxxxx192.0.2.0/24 via 198.51.100.1 table 1203.0.113.0/24 via 198.51.100.2 table 2/etc/sysconfig/network-scripts/route6-*interface*:此文件定义 IPv6 路由。/etc/sysconfig/network-scripts/rule-*interface*:此文件定义内核将流量路由到特定路由表的 IPv4 源网络规则。例如:xxxxxxxxxxfrom 192.0.2.0/24 lookup 1from 203.0.113.0/24 lookup 2/etc/sysconfig/network-scripts/rule6-*interface*:此文件定义内核将流量路由到特定路由表的 IPv6 源网络规则。/etc/iproute2/rt_tables:如果您想要使用名称而不是数字来引用特定的路由表,这个文件会定义映射映射。例如:xxxxxxxxxx1 Provider_A2 Provider_B
其它资源
- 有关 IP 路由的详情,请查看
ip-route(8)man page。 - 有关路由规则的详情,请查看
ip-rule(8)man page。
16.3. 使用旧网络脚本将特定子网的流量路由到不同的默认网关
本节论述了如何将 RHEL 配置为默认路由将所有流量路由到互联网供应商 A 的路由器。使用基于策略的路由,RHEL 会将从内部工作站子网接收的流量路由到供应商 B。
重要
使用 network-scripts 软件包(在 RHEL 8 中已弃用)提供的旧网络脚本配置网络。只有在主机上使用旧网络脚本而不是 NetworkManager 时,才需要按照本节中的步骤进行操作。如果使用 NetworkManager 管理您的网络设置,请参阅 第 16.1 节 “使用 NetworkManager 将特定子网的流量路由到不同的默认网关”。
该流程假设以下网络拓扑:
注意
旧的网络脚本会按照字母顺序处理配置文件。因此,您必须为配置文件命名,确保当依赖接口需要时,用于其他接口的规则和路由的接口会被启动。要实现正确顺序,这个过程使用 ifcfg-*、route-*和 rules-* 文件中的数字。
先决条件
未安装
NetworkManager软件包,或者NetworkManager服务被禁用。已安装
network-scripts软件包。要在流程中设置的 RHEL 路由器有四个网络接口:
enp7s0接口连接到供应商 A 的网络。提供商网络中的网关 IP 是198.51.100.2,网络使用了/30网络掩码。enp1s0接口连接到供应商 B 的网络。提供商网络中的网关 IP 是192.0.2.2,网络使用了/30网络掩码。enp8s0接口使用内部工作站连接到10.0.0.0/24子网。enp9s0界面连接到有公司服务器的203.0.113.0/24子网。
内部工作站子网中的主机使用
10.0.0.1作为默认网关。在此过程中,您可以将此 IP 地址分配给路由器的enp8s0网络接口。服务器子网中的主机使用
203.0.113.1作为默认网关。在此过程中,您可以将此 IP 地址分配给路由器的enp9s0网络接口。firewalld服务已启用并激活。
流程
通过创建包含以下内容的
/etc/sysconfig/network-scripts/ifcfg-1_Provider-A文件将网络接口配置添加到供应商 A:xxxxxxxxxxTYPE=EthernetIPADDR=198.51.100.1PREFIX=30GATEWAY=198.51.100.2DNS1=198.51.100.200DEFROUTE=yesNAME=1_Provider-ADEVICE=enp7s0ONBOOT=yesZONE=external以下列表描述了配置文件里使用的参数:
TYPE=Ethernet:定义连接类型是以太网。IPADDR=*IP_address*:设置 IPv4 地址。PREFIX=*subnet_mask*:设置子网掩码。GATEWAY=*IP_address*:设置默认网关地址。DNS1=*IP_of_DNS_server*:设置 DNS 服务器的 IPv4 地址。DEFROUTE=*yes|no*:定义连接是否为默认路由。NAME=*connection_name*:设置连接配置集的名称。使用有意义的名称以避免混淆。DEVICE=*network_device*:设置网络接口。ONBOOT=yes:定义 RHEL 在系统引导时启动此连接。ZONE=*firewalld_zone*:将网络接口分配给定义的firewalld区。请注意,firewalld会自动启用分配给external区的接口的伪装。
为供应商 B 添加网络接口配置:
使用以下内容创建
/etc/sysconfig/network-scripts/ifcfg-2_Provider-B文件:xxxxxxxxxxTYPE=EthernetIPADDR=192.0.2.1PREFIX=30DEFROUTE=noNAME=2_Provider-BDEVICE=enp1s0ONBOOT=yesZONE=external请注意,这个接口的配置文件不包含默认的网关设置。
将
2_Provider-B连接的网关分配给单独的路由表。因此,使用以下内容创建/etc/sysconfig/network-scripts/route-2_Provider-B文件:xxxxxxxxxx0.0.0.0/0 via 192.0.2.2 table 5000这个条目将通过这个网关路由的所有子网的网关和流量分配到表
5000.
为内部工作站子网创建网络接口配置:
使用以下内容创建
/etc/sysconfig/network-scripts/ifcfg-3_Internal-Workstations文件:xxxxxxxxxxTYPE=EthernetIPADDR=10.0.0.1PREFIX=24DEFROUTE=noNAME=3_Internal-WorkstationsDEVICE=enp8s0ONBOOT=yesZONE=internal为内部工作站子网添加路由规则配置。因此,使用以下内容创建
/etc/sysconfig/network-scripts/rule-3_Internal-Workstations文件:xxxxxxxxxxpri 5 from 10.0.0.0/24 table 5000此配置定义了带有优先级
5的路由规则,该规则将所有流量从10.0.0.0/24子网路由到表5000。低的值具有更高的优先级。使用以下内容创建
/etc/sysconfig/network-scripts/route-3_Internal-Workstations文件,将静态路由添加到路由表, ID 为5000:xxxxxxxxxx10.0.0.0/24 via 192.0.2.1 table 5000这个静态路由定义 RHEL 将流量从
10.0.0.0/24子网发送到本地网络接口的 IP 发送到供应商 B(192.0.2.1)。这个界面用于路由表5000,并用作下一跳。
通过创建包含以下内容的
/etc/sysconfig/network-scripts/ifcfg-4_Servers文件将网络接口配置添加到服务器子网中:xxxxxxxxxxTYPE=EthernetIPADDR=203.0.113.1PREFIX=24DEFROUTE=noNAME=4_ServersDEVICE=enp9s0ONBOOT=yesZONE=internal重启网络:
xxxxxxxxxx# systemctl restart network
验证步骤
在内部工作站子网的 RHEL 主机上:
安装
traceroute软件包:xxxxxxxxxx# yum install traceroute使用
traceroute工具显示到互联网主机的路由:xxxxxxxxxx# traceroute redhat.comtraceroute to redhat.com (209.132.183.105), 30 hops max, 60 byte packets1 10.0.0.1 (10.0.0.1) 0.337 ms 0.260 ms 0.223 ms2 192.0.2.1 (192.0.2.1) 0.884 ms 1.066 ms 1.248 ms...命令的输出显示路由器通过
192.0.2.1发送数据包,这是供应商 B 的网络。
在服务器子网的 RHEL 主机上:
安装
traceroute软件包:xxxxxxxxxx# yum install traceroute使用
traceroute工具显示到互联网主机的路由:xxxxxxxxxx# traceroute redhat.comtraceroute to redhat.com (209.132.183.105), 30 hops max, 60 byte packets1 203.0.113.1 (203.0.113.1) 2.179 ms 2.073 ms 1.944 ms2 198.51.100.2 (198.51.100.2) 1.868 ms 1.798 ms 1.549 ms...命令的输出显示路由器通过
198.51.100.2发送数据包,这是供应商 A 的网络。
故障排除步骤
在 RHEL 路由器中:
显示规则列表:
xxxxxxxxxx# ip rule list0: from all lookup local5: from 10.0.0.0/24 lookup 500032766: from all lookup main32767: from all lookup default默认情况下,RHEL 包含表
local、main和default的规则。显示表
5000中的路由:xxxxxxxxxx# ip route list table 5000default via 192.0.2.2 dev enp1s010.0.0.0/24 via 192.0.2.1 dev enp1s0显示接口和防火墙区:
xxxxxxxxxx# firewall-cmd --get-active-zonesexternalinterfaces: enp1s0 enp7s0internalinterfaces: enp8s0 enp9s0验证
external区是否启用了伪装:xxxxxxxxxx# firewall-cmd --info-zone=externalexternal (active)target: defaulticmp-block-inversion: nointerfaces: enp1s0 enp7s0sources:services: sshports:protocols:masquerade: yes...
其它资源
- 第 16.2 节 “使用旧网络脚本时,涉及基于策略的路由的配置文件概述”
ip-route(8)man pageip-rule(8)man page- 有关旧的网络脚本的详情,请查看
/usr/share/doc/network-scripts/sysconfig.txt文件
第 17 章 配置 VLAN 标记
这部分论述了如何配置虚拟本地区域网络(VLAN)。VLAN 是物理网络中的一个逻辑网络。当 VLAN 接口通过接口时,VLAN 接口标签带有 VLAN ID 的数据包,并删除返回的数据包的标签。
您可以在另一个接口(如以太网、绑定、team 或桥接设备)上创建 VLAN 接口。这个界面被称为 parent interface。
17.1. 使用 nmcli 命令配置 VLAN 标记
本节论述了如何使用 nmcli 程序配置 Virtual Local Area Network(VLAN)标记。
先决条件
您计划用作虚拟 VLAN 接口的父接口支持 VLAN 标签。
如果您在绑定接口之上配置 VLAN:
- 绑定的从设备是上线的。
- 该绑定没有使用
fail_over_mac=follow选项配置。VLAN 虚拟设备无法更改其 MAC 地址以匹配父设备的新 MAC 地址。在这种情况下,流量仍会与不正确的源 MAC 地址一同发送。
主机连接到的交换机被配置为支持 VLAN 标签。详情请查看您的交换机文档。
流程
显示网络接口:
xxxxxxxxxx# nmcli device statusDEVICE TYPE STATE CONNECTIONenp1s0 ethernet disconnected enp1s0bridge0 bridge connected bridge0bond0 bond connected bond0...创建 VLAN 接口。例如,要创建一个名为
vlan10的 VLAN 接口,它使用enp1s0作为它的上级接口,并带有 VLAN ID10的标签数据包,请输入:xxxxxxxxxx# nmcli connection add type vlan con-name vlan10 ifname vlan10 vlan.parent enp1s0 vlan.id 10请注意,VLAN 必须在
0到4094范围内。默认情况下,VLAN 连接会继承上级接口的最大传输单元(MTU)。另外,还可设置不同的 MTU 值:
xxxxxxxxxx# nmcli connection modify vlan10 802-3-ethernet.mtu 2000配置 VLAN 设备的 IP 设置。如果要使用这个 VLAN 设备作为其它设备的从设备,请跳过这一步。
配置 IPv4 设置。例如,要为
vlan10连接设置静态 IPv4 地址、网络掩码、默认网关和 DNS 服务器设置,请输入:xxxxxxxxxx# nmcli connection modify vlan10 ipv4.addresses '192.0.2.1/24'# nmcli connection modify vlan10 ipv4.gateway '192.0.2.254'# nmcli connection modify vlan10 ipv4.dns '192.0.2.253'# nmcli connection modify vlan10 ipv4.method manual配置 IPv6 设置。例如,要为
vlan10连接设置静态 IPv6 地址、网络掩码、默认网关和 DNS 服务器设置,请输入:xxxxxxxxxx# nmcli connection modify vlan10 ipv6.addresses '2001:db8:1::1/32'# nmcli connection modify vlan10 ipv6.gateway '2001:db8:1::fffe'# nmcli connection modify vlan10 ipv6.dns '2001:db8:1::fffd'# nmcli connection modify vlan10 ipv6.method manual
激活连接:
xxxxxxxxxx# nmcli connection up vlan10
验证步骤
验证设置:
xxxxxxxxxx# ip -d addr show vlan104: vlan10@enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000link/ether 52:54:00:d5:e0:fb brd ff:ff:ff:ff:ff:ff promiscuity 0vlan protocol 802.1Q id 10 <REORDER_HDR> numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute vlan10valid_lft forever preferred_lft foreverinet6 2001:db8:1::1/32 scope global noprefixroutevalid_lft forever preferred_lft foreverinet6 fe80::8dd7:9030:6f8e:89e6/64 scope link noprefixroutevalid_lft forever preferred_lft forever
其它资源
- 有关测试连接的更多信息,请参阅 第 38 章 测试基本网络设置。
- 有关
nmcli示例,请查看nmcli-examples(7)man page。 - 有关您可以设置的所有 vlan 属性,请参阅
nm-settings(5)man page 中的vlan setting部分。
17.2. 使用 nm-connection-editor 配置 VLAN 标记
本节论述了如何使用 nm-connection-editor 应用程序配置 Virtual Local Area Network(VLAN)标记。
先决条件
您计划用作虚拟 VLAN 接口的父接口支持 VLAN 标签。
如果您在绑定接口之上配置 VLAN:
- 绑定的从设备是上线的。
- 该绑定没有使用
fail_over_mac=follow选项配置。VLAN 虚拟设备无法更改其 MAC 地址以匹配父设备的新 MAC 地址。在这种情况下,流量仍会与不正确的源 MAC 地址一同发送。
主机连接到的交换机被配置为支持 VLAN 标签。详情请查看您的交换机文档。
流程
打开终端窗口,输入
nm-connection-editor:xxxxxxxxxx$ nm-connection-editor点 + 按钮添加新连接。
选择
VLAN连接类型,并点击 Create。在
VLAN标签页中:选择上级接口。
选择 VLAN ID。请注意,VLAN 必须在
0到4094范围内。默认情况下,VLAN 连接会继承上级接口的最大传输单元(MTU)。另外,还可设置不同的 MTU 值。
另外,还可设置 VLAN 接口的名称以及其它特定 VLAN 选项。

配置 VLAN 设备的 IP 设置。如果要使用这个 VLAN 设备作为其它设备的从设备,请跳过这一步。
- 在
IPv4 Settings标签中配置 IPv4 设置。例如,设置静态 IPv4 地址、网络掩码、默认网关和 DNS 服务器:
- 在
IPv6 Settings标签中配置 IPv6 设置。例如,设置静态 IPv6 地址、网络掩码、默认网关和 DNS 服务器:
- 在
点击 Save 保存 VLAN 连接。
关闭
nm-connection-editor。
验证步骤
验证设置:
xxxxxxxxxx# ip -d addr show vlan104: vlan10@enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000link/ether 52:54:00:d5:e0:fb brd ff:ff:ff:ff:ff:ff promiscuity 0vlan protocol 802.1Q id 10 <REORDER_HDR> numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535inet 192.0.2.1/24 brd 192.0.2.255 scope global noprefixroute vlan10valid_lft forever preferred_lft foreverinet6 2001:db8:1::1/32 scope global noprefixroutevalid_lft forever preferred_lft foreverinet6 fe80::8dd7:9030:6f8e:89e6/64 scope link noprefixroutevalid_lft forever preferred_lft forever
其它资源
- 有关测试连接的更多信息,请参阅 第 38 章 测试基本网络设置。
第 18 章 配置网络桥接
网络桥接是一个链路层设备,它可根据 MAC 地址列表转发网络间的流量。网桥通过侦听网络流量并了解连接到每个网络的主机来构建 MAC 地址表。例如,您可以使用 Red Hat Enterprise Linux 8 主机中的软件桥接模拟硬件桥接或在虚拟化环境中,将虚拟机(VM)集成到与主机相同的网络中。
桥接需要在桥接应该连接的每个网络中有一个网络设备。当您配置桥接时,桥接名为 master,其使用的设备为 slave 设备。
您可以在不同类型的从设备中创建桥接,例如:
- 物理和虚拟以太网设备
- 网络绑定
- 网络团队(team)
- VLAN 设备
由于 IEEE 802.11 标准指定在 Wi-Fi 中使用 3 个地址帧以便有效地使用随机时间,您无法通过 Ad-Hoc 或者 Infrastructure 模式中的 Wi-Fi 网络配置网桥。
18.1. 使用 nmcli 命令配置网络桥接
本小节论述了如何使用 nmcli 程序配置网络桥接。
先决条件
在服务器中安装两个或者两个以上物理或者虚拟网络设备。
要将以太网设备用作桥接的辅设备,必须在服务器中安装物理或者虚拟以太网设备。
要使用 team、bond 或 VLAN 设备作为网桥的从属设备,您可以在创建桥接时创建这些设备,或者预先创建它们,如:
流程
创建网桥接口:
xxxxxxxxxx# nmcli connection add type bridge con-name bridge0 ifname bridge0这个命令会创建一个名为
bridge0的桥接,输入:显示网络接口,并记录您要添加到网桥中的接口名称:
xxxxxxxxxx# nmcli device statusDEVICE TYPE STATE CONNECTIONenp7s0 ethernet disconnected --enp8s0 ethernet disconnected --bond0 bond connected bond0bond1 bond connected bond1...在本例中:
enp7s0和enp8s0没有配置。要将这些设备作为从设备使用,请在下一步中添加连接配置集。bond0和bond1已有连接配置集。要将这些设备用作从设备,在下一步中修改其配置集。
将接口分配给网桥。
如果没有配置您要分配给网桥的接口,为其创建新的连接配置集:
xxxxxxxxxx# nmcli connection add type ethernet slave-type bridge con-name bridge0-port1 ifname enp7s0 master bridge0# nmcli connection add type ethernet slave-type bridge con-name bridge0-port2 ifname enp8s0 master bridge0这些命令为
enp7s0和enp8s0创建配置集,并将其添加到bridge0连接中。要为网桥分配现有连接配置集,将这些连接的
master参数设置为bridge0:xxxxxxxxxx# nmcli connection modify bond0 master bridge0# nmcli connection modify bond1 master bridge0这些命令将名为
bond0和bond1的现有连接配置集分配给bridge0连接。
配置网桥的 IP 设置。如果要使用这个网桥作为其它设备的从设备,请跳过这一步。
配置 IPv4 设置。例如:要设置
bridge0连接的静态 IPv4 地址、网络掩码、默认网关、DNS 服务器和DNS 搜索域,请输入:xxxxxxxxxx# nmcli connection modify bridge0 ipv4.addresses '192.0.2.1/24'# nmcli connection modify bridge0 ipv4.gateway '192.0.2.254'# nmcli connection modify bridge0 ipv4.dns '192.0.2.253'# nmcli connection modify bridge0 ipv4.dns-search 'example.com'# nmcli connection modify bridge0 ipv4.method manual配置 IPv6 设置。例如:要设置
bridge0连接的静态 IPv6 地址、网络掩码、默认网关、DNS 服务器和DNS 搜索域,请输入:xxxxxxxxxx# nmcli connection modify bridge0 ipv6.addresses '2001:db8:1::1/64'# nmcli connection modify bridge0 ipv6.gateway '2001:db8:1::fffe'# nmcli connection modify bridge0 ipv6.dns '2001:db8:1::fffd'# nmcli connection modify bridge0 ipv6.dns-search 'example.com'# nmcli connection modify bridge0 ipv6.method manual
可选:配置网桥的其他属性。例如,要将
bridge0的生成树协议(STP)优先级设置为16384,请输入:xxxxxxxxxx# nmcli connection modify bridge0 bridge.priority '16384'默认情况下启用 STP。
激活连接:
xxxxxxxxxx# nmcli connection up bridge0验证从设备已连接,
CONNECTION列显示从设备的连接名称:xxxxxxxxxx# nmcli deviceDEVICE TYPE STATE CONNECTION...enp7s0 ethernet connected bridge0-port1enp8s0 ethernet connected bridge0-port2Red Hat Enterprise Linux 在系统引导时激活主设备和从属设备。在激活任何从连接时,主设备也会被激活。然而,在这种情况下,只会激活一个从连接。默认情况下,激活主设备不会自动激活从设备。但是,您可以对其进行设置:
启用网桥连接的
connection.autoconnect-slaves参数:xxxxxxxxxx# nmcli connection modify bridge0 connection.autoconnect-slaves 1重新激活桥接:
xxxxxxxxxx# nmcli connection up bridge0
验证步骤
显示特定网桥从属的以太网设备链接状态:
xxxxxxxxxx# ip link show master bridge03: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000link/ether 52:54:00:62:61:0e brd ff:ff:ff:ff:ff:ff4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000link/ether 52:54:00:9e:f1:ce brd ff:ff:ff:ff:ff:ff显示到任意网桥设备的以太网设备状态:
xxxxxxxxxx# bridge link show3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state forwarding priority 32 cost 1004: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state listening priority 32 cost 1005: enp9s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge1 state forwarding priority 32 cost 1006: enp11s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge1 state blocking priority 32 cost 100...要显示具体以太网设备的状态,请使用
bridge link show dev *ethernet_device_name*命令。
其它资源
- 有关测试连接的更多信息,请参阅 第 38 章 测试基本网络设置。
- 有关
nmcli示例,请查看nmcli-examples(7)man page。 - 有关您可以设置的所有网桥属性,请参阅
nm-settings(5)man page 中的bridge settings部分。 - 有关您可以设置的所有网桥端口属性,请参阅
nm-settings(5)man page 中的bridge-port settings部分。 - 有关
bridge工具程序的详情,请查看bridge(8)man page。 - 如果磁盘中的配置与设备中的配置不匹配,则启动或重启 NetworkManager 会创建一个代表该设备的配置的内存连接。有关详情以及如何避免此问题,请参阅 NetworkManager 服务重启后复制连接。
18.2. 使用 nm-connection-editor 配置网络桥接
本节介绍如何使用 nm-connection-editor 应用程序配置网络桥接。
请注意,nm-connection-editor 只能在桥接中添加新的从设备。要使用现有连接配置集作为从设备,请使用 nmcli 工具创建桥接,如 第 18.1 节 “使用 nmcli 命令配置网络桥接” 所述。
先决条件
- 在服务器中安装两个或者两个以上物理或者虚拟网络设备。
- 要将以太网设备用作桥接的辅设备,必须在服务器中安装物理或者虚拟以太网设备。
- 要使用 team、bond 或 VLAN 设备作为网桥的从设备,请确保这些设备还没有配置。
流程
打开终端窗口,输入
nm-connection-editor:xxxxxxxxxx$ nm-connection-editor点 + 按钮添加新连接。
选择
Bridge连接类型,并点 Create。在
Bridge标签页中:可选:在
Interface name字段中设置桥接接口的名称。点添加按钮为网络接口创建新的连接配置集,并将配置集作为从设备添加到桥接中。
- 选择接口的连接类型。例如,为有线连接选择
Ethernet。 - 另外,还可为从设备设置连接名称。
- 如果您是为以太网设备创建连接配置集,打开
Ethernet标签,在Device字段中选择您要添加为桥接的从接口。如果您选择了不同的设备类型,请相应地进行配置。 - 点 Save。
- 选择接口的连接类型。例如,为有线连接选择
对您要添加到桥接的每个接口重复前面的步骤。

可选:配置其他网桥设置,如生成树协议(STP)选项。
配置网桥的 IP 设置。如果要使用这个网桥作为其它设备的从设备,请跳过这一步。
在
IPv4 Settings标签页中,配置 IPv4 设置。例如,设置静态 IPv4 地址、网络掩码、默认网关、DNS 服务器和 DNS 搜索域:
在
IPv6 Settings标签页中,配置 IPv6 设置。例如,设置静态 IPv6 地址、网络掩码、默认网关、DNS 服务器和 DNS 搜索域:
保存网桥连接。
关闭
nm-connection-editor。
验证步骤
显示某个特定网桥的以太网设备的链接状态。
xxxxxxxxxx# ip link show master bridge03: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000link/ether 52:54:00:62:61:0e brd ff:ff:ff:ff:ff:ff4: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master bridge0 state UP mode DEFAULT group default qlen 1000link/ether 52:54:00:9e:f1:ce brd ff:ff:ff:ff:ff:ff显示到任意网桥设备的以太网设备状态:
xxxxxxxxxx# bridge link show3: enp7s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state forwarding priority 32 cost 1004: enp8s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge0 state listening priority 32 cost 1005: enp9s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge1 state forwarding priority 32 cost 1006: enp11s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master bridge1 state blocking priority 32 cost 100...要显示具体以太网设备的状态,请使用
bridge link show dev *ethernet_device_name*命令。
其它资源
- 第 20.6 节 “使用 nm-connection-editor 配置网络绑定”
- 第 19.7 节 “使用 nm-connection-editor 配置网络团队”
- 第 17.2 节 “使用 nm-connection-editor 配置 VLAN 标记”
- 有关测试连接的更多信息,请参阅 第 38 章 测试基本网络设置。
第 19 章 配置网络团队(team)
这部分论述了网络团队的基础知识、绑定和团队之间的不同以及如何在 Red Hat Enterprise Linux 8 中配置网络团队。
您可以在不同类型的从设备中创建网络团队,例如:
- 物理和虚拟以太网设备
- 网络绑定
- 网络桥接
- VLAN 设备
19.1. 了解网络团队
网络团队(network teaming)是一个合并或聚合网络接口的功能,它提供了一个高吞吐量或冗余的逻辑接口。
网络团队使用内核驱动程序来实现对数据包流、用户空间库以及用于其他任务的服务的快速处理。因此,网络团队是一个易扩展的解决方案,来满足负载平衡和冗余的要求。
请注意,在网络团队环境中,port 也称为 slave。在 teamd 服务中,一般使用 port,而在 NetworkManager 服务中,slave 用来代表创建团队的接口。
重要
某些网络团队的功能,比如故障切换机制,不支持不通过网络交换机的直接电缆连接。详情请查看是否支持直接连接的绑定?
19.2. 了解主和从接口的默认行为
在使用 NetworkManager 服务管理网络团队或对其进行故障排出时,请考虑以下默认行为:
- 启动主接口不会自动启动端口接口。
- 启动端口接口总是启动主接口。
- 停止主接口也会停止端口接口。
- 没有端口的主接口可以启动静态 IP 连接。
- 没有端口的主接口在启动 DHCP 连接时会等待端口。
- 当您添加带有载体的端口时,具有 DHCP 连接的主连接等待端口完成。
- 具有 DHCP 连接的主接口在您添加没有载体的端口时,将继续等待端口等待。
19.3. 网络团队和绑定功能的比较
了解网络团队和网络绑定支持的功能:
| 功能 | 网络绑定 | 网络团队 |
|---|---|---|
| 广播 Tx 策略 | 是 | 是 |
| 轮询 Tx 策略 | 是 | 是 |
| Active-backup Tx 策略 | 是 | 是 |
| LACP(802.3ad)支持 | 是(仅活动) | 是 |
| 基于 hash 的 Tx 策略 | 是 | 是 |
| 用户可以设置哈希功能 | 否 | 是 |
| TX 负载均衡支持(TLB) | 是 | 是 |
| LACP 哈希端口选择 | 是 | 是 |
| LACP 支持的负载均衡 | 否 | 是 |
| ethtool 链接监控 | 是 | 是 |
| ARP 链路监控 | 是 | 是 |
| NS/NA(IPv6)链路监控 | 否 | 是 |
| 端口启动/关闭延时 | 是 | 是 |
| 端口优先级和粘性("主要" 选项增强) | 否 | 是 |
| 独立的每个端口链路监控设置 | 否 | 是 |
| 多个链路监控设置 | 有限 | 是 |
| Lockless Tx/Rx 路径 | 否(rwlock) | 是(RCU) |
| VLAN 支持 | 是 | 是 |
| 用户空间运行时控制 | 有限 | 是 |
| 用户空间中的逻辑 | 否 | 是 |
| 可扩展性 | 难 | 易 |
| 模块化设计 | 否 | 是 |
| 性能开销 | 低 | 非常低 |
| D-Bus 接口 | 否 | 是 |
| 多设备堆栈 | 是 | 是 |
| 使用 LLDP 时零配置 | 否 | (在计划中) |
| NetworkManager 支持 | 是 | 是 |
19.4. 了解 teamd 服务、运行程序和 link-watchers
team 服务 teamd用来控制网络团队驱动的一个实例。这个驱动的实例添加硬件设备驱动程序实例组成一个网络接口组。团队(team)驱动为内核提供了一个网络接口,如 team0。
teamd 服务采用所有团队方法的通用逻辑。这些功能对不同的负载共享和备份方法是唯一的,比如 round-robin,并使用不同的代码单元(请参考 runners)实现。管理员以 JavaScript Object Notation(JSON)格式指定运行程序,在创建实例时,JSON 代码编译到 teamd 实例中。另外,在使用 NetworkManager时,您可以在 team.runner 参数中设置运行程序(runner),NetworkManager 会自动创建对应的 JSON 代码。
可用的运行程序如下:
broadcast:在所有端口上传输数据。roundrobin:依次传输所有端口上的数据。activebackup:通过一个端口传输数据,其他端口则作为备份。loadbalance:通过所有使用活跃 Tx 负载平衡和 Berkeley Packet 过滤器(BPF)的 Tx 端口选择器传输数据。random:在随机选择的端口上传输数据。lacp:实现 802.3ad 链接聚合控制协议(LACP)。
teamd 服务使用一个链接监视器来监控下级设备的状态。可用的 link-watchers 如下:
ethtool:libteam库使用ethtool程序来监视链接状态的改变。这是默认的 link-watcher。arp_ping:libteam库使用arp_ping工具来监控使用地址解析协议(ARP)远端硬件地址是否存在。nsna_ping:在 IPv6 连接中,libteam库使用 IPv6 Neighbor Discovery 协议中的邻居广告和邻居排序特性来监控邻居接口的存在。
每个运行程序都可以使用任何链路监视器,但 lacp除外。这个运行程序只能使用 ethtool 链路监视器。
19.5. 安装 teamd 服务
要在 NetworkManager 中配置网络团队,您需要 teamd 服务和 NetworkManager 的团队插件。默认情况下,它们都会在 Red Hat Enterprise Linux 8 中安装。这部分论述了如何在删除所需软件包时安装它们。
先决条件
- 为主机分配了活跃的红帽订阅。
流程
安装
teamd和NetworkManager-team软件包:xxxxxxxxxx# yum install teamd NetworkManager-team
19.6. 使用 nmcli 命令配置网络团队
本节论述了如何使用 nmcli 工具配置网络团队。
先决条件
在服务器中安装两个或者两个以上物理或者虚拟网络设备。
要使用以太网设备作为团队的从设备,必须在服务器中安装物理或者虚拟以太网设备并连接到交换机。
要将 bond、bridge 或 VLAN 设备用作团队的从属设备,您可以在创建团队时创建这些设备,或者预先创建它们,如下所述:
流程
创建团队接口:
xxxxxxxxxx# nmcli connection add type team con-name team0 ifname team0 team.runner activebackup这个命令会创建一个名为
team0的网络团队,它使用activebackup运行程序。另外,还可设置链接监视器。例如,要在
team0连接配置集中设置ethtool链路监视器:xxxxxxxxxx# nmcli connection modify team0 team.link-watchers "name=ethtool"链路监视器支持不同的参数。要为链接监视器设置参数,在
name属性中指定它们(以空格分隔)。请注意,name 属性必须用引号包围起来。例如,使用ethtool链路监视器,并将其delay-up参数设置为2500毫秒(2.5 秒):xxxxxxxxxx# nmcli connection modify team0 team.link-watchers "name=ethtool delay-up=2500"要设置多个链路监视器,每个都使用特定的参数,不同的连接监视器以逗号分隔。以下示例使用
delay-up参数设置ethtool链接监视器,使用source-host和target-host参数设置arp_ping链路监视器:xxxxxxxxxx# nmcli connection modify team0 team.link-watchers "name=ethtool delay-up=2, name=arp_ping source-host=192.0.2.1 target-host=192.0.2.2"显示网络接口,并记录您要添加到团队中的接口名称:
xxxxxxxxxx# nmcli device statusDEVICE TYPE STATE CONNECTIONenp7s0 ethernet disconnected --enp8s0 ethernet disconnected --bond0 bond connected bond0bond1 bond connected bond1...在本例中:
enp7s0和enp8s0没有配置。要将这些设备作为从设备使用,请在下一步中添加连接配置集。请注意,您只能在没有分配给任何连接的团队中使用以太网接口。bond0和bond1已有连接配置集。要将这些设备用作从设备,在下一步中修改其配置集。
为团队分配端口接口:
如果没有配置您要分配给团队的接口,为其创建新的连接配置集:
xxxxxxxxxx# nmcli connection add type ethernet slave-type team con-name team0-port1 ifname enp7s0 master team0# nmcli connection add type ethernet slave-type team con-name team0-port2 ifname enp8s0 master team0.这些命令为
enp7s0和enp8s0创建配置集,并将其添加到team0连接中。要为团队分配现有连接配置集,将这些连接的
master参数设置为team0:xxxxxxxxxx# nmcli connection modify bond0 master team0# nmcli connection modify bond1 master team0这些命令将名为
bond0和bond1的现有连接配置集分配给team0连接。
配置团队的 IP 设置。如果要使用这个团队作为其它设备的从设备,请跳过这一步。
配置 IPv4 设置。例如:要设置
team0连接的静态 IPv4 地址、网络掩码、默认网关、DNS 服务器和DNS 搜索域,请输入:xxxxxxxxxx# nmcli connection modify team0 ipv4.addresses '192.0.2.1/24'# nmcli connection modify team0 ipv4.gateway '192.0.2.254'# nmcli connection modify team0 ipv4.dns '192.0.2.253'# nmcli connection modify team0 ipv4.dns-search 'example.com'# nmcli connection modify team0 ipv4.method manual配置 IPv6 设置。例如:要设置
team0连接的静态 IPv6 地址、网络掩码、默认网关、DNS 服务器和DNS 搜索域,请输入:xxxxxxxxxx# nmcli connection modify team0 ipv6.addresses '2001:db8:1::1/64'# nmcli connection modify team0 ipv6.gateway '2001:db8:1::fffe'# nmcli connection modify team0 ipv6.dns '2001:db8:1::fffd'# nmcli connection modify team0 ipv6.dns-search 'example.com'# nmcli connection modify team0 ipv6.method manual
激活连接:
xxxxxxxxxx# nmcli connection up team0
验证步骤
显示团队状态:
xxxxxxxxxx# teamdctl team0 statesetup:runner: activebackupports:enp7s0link watches:link summary: upinstance[link_watch_0]:name: ethtoollink: updown count: 0enp8s0link watches:link summary: upinstance[link_watch_0]:name: ethtoollink: updown count: 0runner:active port: enp7s0在这个示例中,两个端口都是上线的。
其它资源
- 有关测试连接的更多信息,请参阅 第 38 章 测试基本网络设置。
- 第 19.4 节 “了解 teamd 服务、运行程序和 link-watchers”.
- 有关
nmcli示例,请查看nmcli-examples(7)man page。 - 有关您可以设置的所有团队属性,请查看
teamman page 中的nm-settings(5)部分。 - 有关您可以在 JSON 配置中设置的参数以及 JSON 示例,请参阅
teamd.conf(5)man page。
19.7. 使用 nm-connection-editor 配置网络团队
本节论述了如何使用 nm-connection-editor 应用程序配置网络团队。
请注意,nm-connection-editor 只能向团队添加新的从设备。要使用现有连接配置集作为从设备,使用 nmcli 工具创建团队,如 第 19.6 节 “使用 nmcli 命令配置网络团队” 所述 。
先决条件
- 在服务器中安装两个或者两个以上物理或者虚拟网络设备。
- 要将以太网设备用作团队的从设备,必须在服务器中安装物理或者虚拟以太网设备。
- 要使用 team、bond 或 VLAN 设备作为团队的从设备,请确保这些设备还没有配置。
流程
打开终端窗口,输入
nm-connection-editor:xxxxxxxxxx$ nm-connection-editor点 + 按钮添加新连接。
选择
Team连接类型,并点 Create。在
Team标签页中:可选:在
Interface name字段中设置 team 接口的名称。点添加按钮为网络接口添加新连接配置集,并将配置集作为从属添加到团队。
- 选择接口的连接类型。例如,为有线连接选择
Ethernet。 - 可选:为从设备设置连接名称。
- 如果您是为以太网设备创建连接配置集,打开
Ethernet标签,在Device字段中选择您要添加为团队的从接口。如果您选择了不同的设备类型,请相应地进行配置。请注意,您只能在没有分配给任何连接的团队中使用以太网接口。 - 点 Save。
- 选择接口的连接类型。例如,为有线连接选择
对您要添加到团队的每个接口重复前面的步骤。

点 Advanced 按钮将高级选项设置为团队连接。
- 在
Runner选项卡中,选择运行程序。 - 在
Link Watcher标签中,设置链路监视器及其可选设置。 - 点击 确定。
- 在
配置团队的 IP 设置。如果要使用这个团队作为其它设备的从设备,请跳过这一步。
- 在
IPv4 Settings标签页中,配置 IPv4 设置。例如,设置静态 IPv4 地址、网络掩码、默认网关、DNS 服务器和 DNS 搜索域:
- 在
IPv6 Settings标签页中,配置 IPv6 设置。例如,设置静态 IPv6 地址、网络掩码、默认网关、DNS 服务器和 DNS 搜索域:
- 在
保存团队连接。
关闭
nm-connection-editor。
验证步骤
显示团队状态:
xxxxxxxxxx# teamdctl team0 statesetup:runner: activebackupports:enp7s0link watches:link summary: upinstance[link_watch_0]:name: ethtoollink: updown count: 0enp8s0link watches:link summary: upinstance[link_watch_0]:name: ethtoollink: updown count: 0runner:active port: enp7s0
其它资源
- 第 20.6 节 “使用 nm-connection-editor 配置网络绑定”
- 第 18.2 节 “使用 nm-connection-editor 配置网络桥接”
- 第 17.2 节 “使用 nm-connection-editor 配置 VLAN 标记”
- 有关测试连接的更多信息,请参阅 第 38 章 测试基本网络设置。
- 第 19.4 节 “了解 teamd 服务、运行程序和 link-watchers”.
- 如果磁盘中的配置与设备中的配置不匹配,则启动或重启 NetworkManager 会创建一个代表该设备的配置的内存连接。有关详情以及如何避免此问题,请参阅 NetworkManager 服务重启后复制连接。
第 20 章 配置网络绑定
这部分论述了网络绑定的基础知识、绑定和组合间的不同,以及如何在 Red Hat Enterprise Linux 8 中配置网络绑定。
您可以在不同类型的从设备中创建绑定,例如:
- 物理和虚拟以太网设备
- 网络桥接
- 网络团队(team)
- VLAN 设备
20.1. 了解网络绑定
网络绑定(network bonding)是组合或者整合网络接口的方法,以便提供一个高吞吐量或冗余的逻辑接口。
active-backup、balance-tlb和 balance-alb 模式不需要任何网络交换机的具体配置。然而,其他绑定模式需要配置交换机来聚合链接。例如:对于模式 0、2 和 3,Cisco 交换机需要 EtherChannel,但对于模式 4,链接聚合控制协议(LACP)和 EtherChannel 是必需的。
详情请查看您的交换机和 Linux 以太网捆绑驱动程序 HOWTO 文档。
重要
某些网络绑定的功能,比如故障切换机制,不支持不通过网络交换机的直接电缆连接。详情请查看是否支持直接连接的绑定?KCS 解决方案。
20.2. 了解主和从接口的默认行为
在使用 NetworkManager 服务管理网络团队或对其进行故障排出时,请考虑以下默认行为:
- 启动主接口不会自动启动端口接口。
- 启动端口接口总是启动主接口。
- 停止主接口也会停止端口接口。
- 没有端口的主接口可以启动静态 IP 连接。
- 没有端口的主接口在启动 DHCP 连接时会等待端口。
- 当您添加带有载体的端口时,具有 DHCP 连接的主连接等待端口完成。
- 具有 DHCP 连接的主接口在您添加没有载体的端口时,将继续等待端口等待。
20.3. 网络团队和绑定功能的比较
了解网络团队和网络绑定支持的功能:
| 功能 | 网络绑定 | 网络团队 |
|---|---|---|
| 广播 Tx 策略 | 是 | 是 |
| 轮询 Tx 策略 | 是 | 是 |
| Active-backup Tx 策略 | 是 | 是 |
| LACP(802.3ad)支持 | 是(仅活动) | 是 |
| 基于 hash 的 Tx 策略 | 是 | 是 |
| 用户可以设置哈希功能 | 否 | 是 |
| TX 负载均衡支持(TLB) | 是 | 是 |
| LACP 哈希端口选择 | 是 | 是 |
| LACP 支持的负载均衡 | 否 | 是 |
| ethtool 链接监控 | 是 | 是 |
| ARP 链路监控 | 是 | 是 |
| NS/NA(IPv6)链路监控 | 否 | 是 |
| 端口启动/关闭延时 | 是 | 是 |
| 端口优先级和粘性("主要" 选项增强) | 否 | 是 |
| 独立的每个端口链路监控设置 | 否 | 是 |
| 多个链路监控设置 | 有限 | 是 |
| Lockless Tx/Rx 路径 | 否(rwlock) | 是(RCU) |
| VLAN 支持 | 是 | 是 |
| 用户空间运行时控制 | 有限 | 是 |
| 用户空间中的逻辑 | 否 | 是 |
| 可扩展性 | 难 | 易 |
| 模块化设计 | 否 | 是 |
| 性能开销 | 低 | 非常低 |
| D-Bus 接口 | 否 | 是 |
| 多设备堆栈 | 是 | 是 |
| 使用 LLDP 时零配置 | 否 | (在计划中) |
| NetworkManager 支持 | 是 | 是 |
20.4. 上游交换配置取决于绑定模式
下表描述了根据绑定模式,您必须对上游交换机应用哪些设置:
| 绑定模式 | 交换机上的配置 |
|---|---|
0 - balance-rr | 需要启用静态的 Etherchannel(未启用 LACP 协商) |
1 - active-backup | 需要可自主端口 |
2 - balance-xor | 需要启用静态的 Etherchannel(未启用 LACP 协商) |
3 - broadcast | 需要启用静态的 Etherchannel(未启用 LACP 协商) |
4 - 802.3ad | 需要启用 LACP 协商的 Etherchannel |
5 - balance-tlb | 需要可自主端口 |
6 - balance-alb | 需要可自主端口 |
有关在交换机中配置这些设置,请查看交换机文档。
20.5. 使用 nmcli 命令配置网络绑定
这部分论述了如何使用 nmcli 命令配置网络绑定。
先决条件
在服务器中安装两个或者两个以上物理或者虚拟网络设备。
要将以太网设备用作绑定的从设备,必须在服务器中安装物理或者虚拟以太网设备。
要使用 team、bridge 或 VLAN 设备作为绑定的从属设备,您可以在创建绑定时创建这些设备,或者预先创建它们,如:
流程
创建绑定接口:
xxxxxxxxxx# nmcli connection add type bond con-name bond0 ifname bond0 bond.options "mode=active-backup"这个命令会创建一个名为
bond0的绑定,它使用active-backup模式。另外,要设置 Media 独立的接口(MII)监控间隔,请将
miimon=*interval*选项添加到bond.options属性中。例如:要使用同样的命令,但还需要将 MII 监控间隔设置为1000毫秒(1秒),请输入:xxxxxxxxxx# nmcli connection add type bond con-name bond0 ifname bond0 bond.options "mode=active-backup,miimon=1000"显示网络接口以及您要添加到绑定中的接口名称:
xxxxxxxxxx# nmcli device statusDEVICE TYPE STATE CONNECTIONenp7s0 ethernet disconnected --enp8s0 ethernet disconnected --bridge0 bridge connected bridge0bridge1 bridge connected bridge1...在本例中:
enp7s0和enp8s0没有配置。要将这些设备作为从设备使用,请在下一步中添加连接配置集。bridge0和bridge1已有连接配置集。要将这些设备用作从设备,在下一步中修改其配置集。
为绑定分配接口:
如果没有配置您要分配给绑定的接口,为其创建新的连接配置集:
xxxxxxxxxx# nmcli connection add type ethernet slave-type bond con-name bond0-port1 ifname enp7s0 master bond0# nmcli connection add type ethernet slave-type bond con-name bond0-port2 ifname enp8s0 master bond0这些命令为
enp7s0和enp8s0创建配置集,并将其添加到bond0连接中。要为绑定分配现有连接配置集,请将这些连接的
master参数设置为bond0:xxxxxxxxxx# nmcli connection modify bridge0 master bond0# nmcli connection modify bridge1 master bond0这些命令将名为
bridge0和bridge1的现有连接配置集分配给bond0连接。
配置绑定的 IP 设置。如果要使用这个绑定作为其它设备的从设备,请跳过这一步。
配置 IPv4 设置。例如:要设置
bond0连接的静态 IPv4 地址、网络掩码、默认网关、DNS 服务器和DNS 搜索域,请输入:xxxxxxxxxx# nmcli connection modify bond0 ipv4.addresses '192.0.2.1/24'# nmcli connection modify bond0 ipv4.gateway '192.0.2.254'# nmcli connection modify bond0 ipv4.dns '192.0.2.253'# nmcli connection modify bond0 ipv4.dns-search 'example.com'# nmcli connection modify bond0 ipv4.method manual配置 IPv6 设置。例如:要设置
bond0连接的静态 IPv6 地址、网络掩码、默认网关、DNS 服务器和DNS 搜索域,请输入:xxxxxxxxxx# nmcli connection modify bond0 ipv6.addresses '2001:db8:1::1/64# nmcli connection modify bond0 ipv6.gateway '2001:db8:1::fffe'# nmcli connection modify bond0 ipv6.dns '2001:db8:1::fffd'# nmcli connection modify bond0 ipv6.dns-search 'example.com'# nmcli connection modify bond0 ipv6.method manual
激活连接:
xxxxxxxxxx# nmcli connection up bond0验证从设备已连接,
CONNECTION列显示从设备的连接名称:xxxxxxxxxx# nmcli deviceDEVICE TYPE STATE CONNECTION...enp7s0 ethernet connected bond0-port1enp8s0 ethernet connected bond0-port2Red Hat Enterprise Linux 在系统引导时激活主设备和从属设备。在激活任何从连接时,主设备也会被激活。然而,在这种情况下,只会激活一个从连接。默认情况下,激活主设备不会自动激活从设备。但是,您可以对其进行设置:
启用绑定连接的
connection.autoconnect-slaves参数:xxxxxxxxxx# nmcli connection modify bond0 connection.autoconnect-slaves 1重新激活桥接:
xxxxxxxxxx# nmcli connection up bond0
验证步骤
显示绑定状态:
x# cat /proc/net/bonding/bond0Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011)Bonding Mode: fault-tolerance (active-backup)Primary Slave: NoneCurrently Active Slave: enp7s0MII Status: upMII Polling Interval (ms): 100Up Delay (ms): 0Down Delay (ms): 0Slave Interface: enp7s0MII Status: upSpeed: UnknownDuplex: UnknownLink Failure Count: 0Permanent HW addr: 52:54:00:d5:e0:fbSlave queue ID: 0Slave Interface: enp8s0MII Status: upSpeed: UnknownDuplex: UnknownLink Failure Count: 0Permanent HW addr: 52:54:00:b2:e2:63Slave queue ID: 0在这个示例中,两个端口都是上线的。
验证绑定故障切换是否正常工作:
从主机中临时删除网络电缆。请注意,无法使用命令行正确测试链路失败事件。
显示绑定状态:
xxxxxxxxxx# cat /proc/net/bonding/bond0
其它资源
- 有关测试连接的更多信息,请参阅 第 38 章 测试基本网络设置。
- 有关
nmcli示例,请查看nmcli-examples(7)man page。 - 有关您可以在创建绑定时在
nmcli命令的bond.options参数中设置的选项列表,请参阅 https://www.kernel.org/doc/Documentation/networking/bonding.txt。
20.6. 使用 nm-connection-editor 配置网络绑定
本节论述了如何使用 nm-connection-editor 应用程序配置网络绑定。
请注意,nm-connection-editor 只能向绑定中添加新的从设备。要将现有连接配置集用作从设备,使用 nmcli 实用程序创建绑定,如 第 20.5 节 “使用 nmcli 命令配置网络绑定” 所述。
先决条件
- 在服务器中安装两个或者两个以上物理或者虚拟网络设备。
- 要将以太网设备用作绑定的从设备,必须在服务器中安装物理或者虚拟以太网设备。
- 要使用 team、bond 或 VLAN 设备作为绑定的从设备,请确保这些设备还没有配置。
流程
打开终端窗口,输入
nm-connection-editor:xxxxxxxxxx$ nm-connection-editor点 + 按钮添加新连接。
选
Bond连接类型,并点 Create。在
Bond标签页中:可选:在
Interface name字段中设置绑定接口的名称。点添加按钮将网络接口作为从属添加到绑定。
- 选择接口的连接类型。例如,为有线连接选择
Ethernet。 - 可选:为从设备设置连接名称。
- 如果您是为以太网设备创建连接配置集,打开
Ethernet标签,在Device字段中选择您要添加为绑定的从接口。如果您选择了不同的设备类型,请相应地进行配置。请注意,您只能在没有配置的绑定中使用以太网接口。 - 点 Save。
- 选择接口的连接类型。例如,为有线连接选择
对您要添加到绑定的每个接口重复前面的步骤:

可选:设置其他选项,如介质独立接口(MII)监控间隔。
配置绑定的 IP 设置。如果要使用这个绑定作为其它设备的从设备,请跳过这一步。
在
IPv4 Settings标签页中,配置 IPv4 设置。例如,设置静态 IPv4 地址、网络掩码、默认网关、DNS 服务器和 DNS 搜索域:
在
IPv6 Settings标签页中,配置 IPv6 设置。例如,设置静态 IPv6 地址、网络掩码、默认网关、DNS 服务器和 DNS 搜索域:
点 Save 保存绑定连接。
关闭
nm-connection-editor。
验证步骤
查看绑定的状态:
xxxxxxxxxx$ cat /proc/net/bonding/bond0Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011)Bonding Mode: fault-tolerance (active-backup)Primary Slave: NoneCurrently Active Slave: enp7s0MII Status: upMII Polling Interval (ms): 100Up Delay (ms): 0Down Delay (ms): 0Slave Interface: enp7s0MII Status: upSpeed: UnknownDuplex: UnknownLink Failure Count: 0Permanent HW addr: 52:54:00:d5:e0:fbSlave queue ID: 0Slave Interface: enp8s0MII Status: upSpeed: UnknownDuplex: UnknownLink Failure Count: 0Permanent HW addr: 52:54:00:b2:e2:63Slave queue ID: 0在这个示例中,两个端口都是上线的。
其它资源
- 第 19.7 节 “使用 nm-connection-editor 配置网络团队”
- 第 18.2 节 “使用 nm-connection-editor 配置网络桥接”
- 第 17.2 节 “使用 nm-connection-editor 配置 VLAN 标记”
- 有关测试连接的更多信息,请参阅 第 38 章 测试基本网络设置。
20.7. 创建网络绑定以便在不中断 VPN 的情况下在以太网和无线连接间进行切换
将工作站连接到公司网络的 RHEL 用户通常会使用 VPN 访问远程资源。然而,如果工作站在以太网和 Wi-Fi 连接间切换,例如:如果您是从带以太网连接的 docking 站中释放的笔记本电脑,VPN 连接就中断。要避免这个问题,您可以在 active-backup 模式中使用以太网和 Wi-Fi 连接创建一个网络绑定。
先决条件
主机包含以太网和 Wi-Fi 设备。
已创建以太网和 Wi-Fi 网络管理器连接配置集,且两个连接都可以独立工作。
此流程使用以下连接配置集来创建名为
bond0的网络绑定:Docking_station与enp11s0u1以太网设备相关联Wi-Fi与wlp61s0Wi-Fi 设备相关联
流程
在
active-backup模式中创建绑定接口:xxxxxxxxxx# nmcli connection add type bond con-name bond0 ifname bond0 bond.options "mode=active-backup"这个命令为接口和连接配置集
bond0命名。配置绑定的 IPv4 设置:
如果您的网络中的 DHCP 服务器为主机分配 IPv4 地址,则不需要任何操作。
如果您的本地网络需要静态 IPv4 地址,请将地址、网络掩码、默认网关、DNS 服务器和 DNS 搜索域设置为
bond0连接:xxxxxxxxxx# nmcli connection modify bond0 ipv4.addresses '192.0.2.1/24'# nmcli connection modify bond0 ipv4.gateway '192.0.2.254'# nmcli connection modify bond0 ipv4.dns '192.0.2.253'# nmcli connection modify bond0 ipv4.dns-search 'example.com'# nmcli connection modify bond0 ipv4.method manual
配置绑定的 IPv6 设置:
如果您的网络中的路由器或者 DHCP 服务器为主机分配 IPv6 地址,则不需要任何操作。
如果您的本地网络需要静态 IPv6 地址,请将地址、网络掩码、默认网关、DNS 服务器和 DNS 搜索域设置为
bond0连接:xxxxxxxxxx# nmcli connection modify bond0 ipv6.addresses '2001:db8:1::1/64'# nmcli connection modify bond0 ipv6.gateway '2001:db8:1::fffe'# nmcli connection modify bond0 ipv6.dns '2001:db8:1::fffd'# nmcli connection modify bond0 ipv6.dns-search 'example.com'# nmcli connection modify bond0 ipv6.method manual
显示连接配置集:
xxxxxxxxxx# nmcli connection showNAME UUID TYPE DEVICEDocking_station 256dd073-fecc-339d-91ae-9834a00407f9 ethernet enp11s0u1Wi-Fi 1f1531c7-8737-4c60-91af-2d21164417e8 wifi wlp61s0...下一步需要连接配置集的名称和以太网设备名称。
为绑定分配以太网连接的配置:
xxxxxxxxxx# nmcli connection modify Docking_station master bond0为绑定分配 Wi-Fi 连接的连接配置集:
xxxxxxxxxx# nmcli connection modify Wi-Fi master bond0如果您的 Wi-Fi 网络使用 MAC 过滤来只允许白名单中的 MAC 地址访问网络,请将活跃的从设备 MAC 地址动态地分配给绑定:
xxxxxxxxxx# nmcli connection modify bond0 +bond.options fail_over_mac=1使用这个设置时,您必须将 Wi-Fi 设备的 MAC 地址设置为白名单,而不是以太网和 Wi-Fi 设备的 MAC 地址。
将与以太连接关联的设备设置为绑定的主设备:
xxxxxxxxxx# nmcli con modify bond0 +bond.options "primary=enp11s0u1"使用这个设置时,如果可用,绑定总是使用以太网连接。
配置在激活
bond0设备时,网络管理器(NetworkManager)会自动激活从设备:xxxxxxxxxx# nmcli connection modify bond0 connection.autoconnect-slaves 1激活
bond0连接:xxxxxxxxxx# nmcli connection up bond0
验证步骤
显示当前激活的设备,绑定及其从设备的状态:
xxxxxxxxxx# cat /proc/net/bonding/bond0Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011)Bonding Mode: fault-tolerance (active-backup) (fail_over_mac active)Primary Slave: enp11s0u1 (primary_reselect always)Currently Active Slave: enp11s0u1MII Status: upMII Polling Interval (ms): 1Up Delay (ms): 0Down Delay (ms): 0Peer Notification Delay (ms): 0Slave Interface: enp11s0u1MII Status: upSpeed: 1000 MbpsDuplex: fullLink Failure Count: 0Permanent HW addr: 00:53:00:59:da:b7Slave queue ID: 0Slave Interface: wlp61s0MII Status: upSpeed: UnknownDuplex: UnknownLink Failure Count: 2Permanent HW addr: 00:53:00:b3:22:baSlave queue ID: 0
其它资源
第 21 章 使用以太网配置光纤
根据 IEEE T11 FC-BB-5 标准,使用以太网(FCoE)的光纤通道是通过以太网传输光纤通道帧的协议。通常数据中心有一个专用的 LAN 和 Storage Area Network(SAN),它和它们自己的配置是相互分开的。FCoE 将这些网络合并为一个整合的网络结构。例如 FCoE 的优点是降低硬件和能源成本。
21.1. 在 RHEL 中使用硬件 FCoE HBA
在 Red Hat Enterprise Linux 中,您可以使用以下驱动程序支持的硬件 FCoE 主机总线适配器(HBA):
qedfbnx2fcfnic
如果您使用这样的 HBA,在 HBA 设置中配置 FCoE 设置。详情请查看适配器文档。
您在设置中配置了 HBA 后,从 Storage Area Network(SAN)中导出的逻辑单元号(LUN)将自动可用于 RHEL 作为 /dev/sd* 设备。您可以使用类似本地存储设备的设备。
21.2. 设置软件 FCoE 设备
软件 FCoE 设备可让您使用部分支持 FCoE 的以太网适配器访问 FCoE 的逻辑单元号(LUN)。
重要
RHEL 不支持需要 fcoe.ko 内核模块的软件 FCoE 设备。详情请查看 Considerations in adopting RHEL 8 文档中的 删除 FCoE 软件。
完成此步骤后,RHEL 会自动访问 Storage Area Network(SAN)中导出的 LUN 作为 /dev/sd* 设备。您可以使用类似本地存储设备的设备。
先决条件
- 主机总线适配器(HBA)使用
qedf、bnx2fc或fnic驱动程序,且不需要fcoe.ko内核模块。 - SAN 使用 VLAN 来将存储流量与普通以太网流量分开。
- 网络切换已被配置为支持 VLAN。
- 服务器的 HBA 在它的 BIOS 中被配置。详情请查看您的 HBA 文档。
- HBA 连接至网络,连接是在线的。
流程
安装
fcoe-utils软件包:xxxxxxxxxx# yum install fcoe-utils将
/etc/fcoe/cfg-ethx模板文件复制到/etc/fcoe/cfg-*interface_name*。例如:如果要配置enp1s0接口使用 FCoE,输入:xxxxxxxxxx# cp /etc/fcoe/cfg-ethx /etc/fcoe/cfg-enp1s0启用并启动
fcoe服务:xxxxxxxxxx# systemctl enable --now fcoe发现 FCoE VLAN ID,启动发起程序,并为发现的 VLAN 创建网络设备:
xxxxxxxxxx# fipvlan -s -c enp1s0Created VLAN device enp1s0.200Starting FCoE on interface enp1s0.200Fibre Channel Forwarders Discoveredinterface | VLAN | FCF MAC------------------------------------------enp1s0 | 200 | 00:53:00:a7:e7:1b可选: 要显示发现的目标、LUN 和与 LUN 关联的设备详情,请输入:
xxxxxxxxxx# fcoeadm -tInterface: enp1s0.200Roles: FCP TargetNode Name: 0x500a0980824acd15Port Name: 0x500a0982824acd15Target ID: 0MaxFrameSize: 2048 bytesOS Device Name: rport-11:0-1FC-ID (Port ID): 0xba00a0State: OnlineLUN ID Device Name Capacity Block Size Description------ ----------- ---------- ---------- ---------------------0 sdb 28.38 GiB 512 NETAPP LUN (rev 820a)...这个示例显示 SAN 中的 LUN 0 已作为
/dev/sdb设备附加到主机中。
验证步骤
使用
fcoeadm -i命令显示所有活跃 FCoE 接口的信息:xxxxxxxxxx# fcoeadm -iDescription: BCM57840 NetXtreme II 10 Gigabit EthernetRevision: 11Manufacturer: Broadcom Inc. and subsidiariesSerial Number: 000AG703A9B7Driver: bnx2x UnknownNumber of Ports: 1Symbolic Name: bnx2fc (QLogic BCM57840) v2.12.13 over enp1s0.200OS Device Name: host11Node Name: 0x2000000af70ae935Port Name: 0x2001000af70ae935Fabric Name: 0x20c8002a6aa7e701Speed: 10 GbitSupported Speed: 1 Gbit, 10 GbitMaxFrameSize: 2048 bytesFC-ID (Port ID): 0xba02c0State: Online
其它资源
- 有关
fcoeadm工具程序的详情,请查看fcoeadm(8)man page。 - 有关如何在系统引导时通过软件 FCoE 挂载存储的详情,请查看
/usr/share/doc/fcoe-utils/README文件。
21.3. 其它资源
- 有关使用光纤通道设备的详情,请参考
Managing storage devices指南中的 使用光纤通道设备 部分。
第 22 章 配置 VPN 连接
这部分论述了如何配置虚拟专用网络(VPN)连接。
VPN 是通过互联网连接到本地网络的一种方式。IPsec 由 Libreswan 提供是创建 VPN 的首选方法。Libreswan 是 VPN 在用户空间 IPsec 的一个实现。VPN 通过在中间网络(比如互联网)设置隧道,启用 LAN 和另一个远程 LAN 之间的通信。为了安全起见,VPN 隧道总是使用认证和加密。对于加密操作,Libreswan 使用 NSS 库。
22.1. 使用 control-center 配置 VPN 连接
这个步骤描述了如何使用control-center配置 VPN 连接。
先决条件
- 已安装
NetworkManager-libreswan-gnome软件包。
流程
按 Super 键,键入
Settings,然后按 Enter 键打开control-center应用程序。选择左侧的
Network条目。点 + 图标。
选择
VPN。选择
Identity菜单条目来查看基本配置选项:常规
Gateway- 远程 VPN 网关的名称或者IP地址。Authentication
TypeIKEv2 (Certificate)- 客户端使用证书进行验证。它更安全(默认)。IKEv1 (XAUTH)- 客户端通过用户名和密码或者一个预共享密钥(PSK)进行验证。以下配置设置位于
Advanced部分:图 22.1. VPN 连接的高级选项

警告
当使用
gnome-control-center应用程序配置基于 IPsec 的 VPN 连接时,Advanced对话框会显示配置,但它不允许任何更改。因此,用户无法更改任何高级 IPsec 选项。使用nm-connection-editor或nmcli工具来配置高级属性。身份识别
Domain- 如果需要,输入域名。安全性
Phase1 Algorithms- 对应于ikeLibreswan 参数 - 输入用来验证和设置加密频道的算法。Phase2 Algorithms- 对应于espLibreswan 参数 - 输入用于IPsec的算法。检查
Disable PFS字段关闭 Perfect Forward Secrecy(PFS)以确保与不支持 PFS 的旧服务器兼容。Phase1 Lifetime- 对应于ikelifetimeLibreswan 参数 - 用于加密流量的密钥的有效期。Phase2 Lifetime- 对应于salifetimeLibreswan 参数 - 在过期前连接的特定实例应当在多久时间内继续。注意:为了安全起见,加密密钥应该不时地更改。
Remote network- 对应于rightsubnetLibreswan 参数 - 应该通过 VPN 访问的目标专用远程网络。检查
narrowing字段以启用缩小功能。请注意,它只在 IKEv2 协商中有效。Enable fragmentation- 对应于fragmentationLibreswan 参数 - 是否允许 IKE 分段。有效值为yes(默认)或no。Enable Mobike- 对应于mobikeLibreswan 参数 - 是否允许移动性和多功能协议(MOBIKE,RFC 4555)启用连接以启用连接以迁移其端点,而无需从头开始重启连接。这可用于在有线、无线或者移动数据连接之间进行切换的移动设备。值为no(默认)或yes。
选择 IPv4 菜单条目:
IPv4 方法
Automatic (DHCP)- 如果您要连接的网络使用路由器广告(Router Advertisements,RA)或DHCP服务器来分配动态IP地址,请选择这个选项。Link-Local Only- 如果您要连接的网络没有DHCP服务器且您不想手动分配IP地址,请选择这个选项。随机地址将根据 RFC 3927 分配前缀169.254/16。Manual- 如果要手动分配IP地址,请选择这个选项。Disable-IPv4在这个连接中被禁用。DNS
在
DNS部分,当Automatic为ON时,将其切换到OFF以输入您要用逗号分开的 DNS 服务器的 IP 地址。Routes
请注意,在
Routes部分,当Automatic为ON时,会使用来自 DHCP 的路由,但您也可以添加其他静态路由。当为OFF时,只使用静态路由。Address- 输入远程网络或主机的IP地址。Netmask- 上面输入的IP地址的子网掩码或前缀长度。Gateway- 上面输入的远程网络或主机的IP地址。Metric- 网络成本,为这个路由赋予的首选值。数值越低,优先级越高。仅将此连接用于其网络上的资源
选择这个复选框以防止连接成为默认路由。选择这个选项意味着只有特别用于路由的流量才会通过连接自动获得,或者手动输入到连接上。
要在
VPN连接中配置IPv6设置,请选择 IPv6 菜单条目:IPv6 Method
Automatic- 选择这个选项使用IPv6Stateless Address AutoConfiguration(SLAAC)根据硬件地址和路由器公告(RA)创建自动的、无状态的配置。Automatic, DHCP only- 选择这个选项以不使用 RA,但从DHCPv6请求信息以创建有状态的配置。Link-Local Only- 如果您要连接的网络没有DHCP服务器且您不想手动分配IP地址,请选择这个选项。随机地址将根据 RFC 4862 进行分配,前缀为FE80::0。Manual- 如果要手动分配IP地址,请选择这个选项。Disable-IPv6在这个连接中被禁用。请注意,
DNS、Routes、Use this connection only for resources on its network对于IPv4设置是通用的。
编辑完
VPN连接后,点添加按钮自定义配置或应用按钮为现有配置保存它。将配置集切换为
ON来激活VPN连接。
其它资源
- 有关支持的
Libreswan参数的详情,请查看nm-settings-libreswan(5)man page。
22.2. 使用 nm-connection-editor 配置 VPN 连接
这个步骤描述了如何使用 nm-connection-editor 配置 VPN 连接。
先决条件
已安装
NetworkManager-libreswan-gnome软件包。如果您配置了互联网密钥交换版本 2(IKEv2)连接:
- 证书导入到 IPsec 网络安全服务(NSS)数据库中。
- NSS 数据库中的证书 nickname 是已知的。
流程
打开终端窗口,输入:
xxxxxxxxxx$ nm-connection-editor点 + 按钮添加新连接。
选择
IPsec based VPN连接类型,并点 Create。在
VPN标签页中:在
Gateway字段中输入 VPN 网关的主机名或 IP 地址,并选择验证类型。根据验证类型,您必须输入不同的附加信息:IKEv2 (Certifiate)使用更安全的证书验证客户端。这个设置需要在 IPsec NSS 数据库中指定证书的 nicknameIKEv1 (XAUTH)使用用户名和密码(预共享密钥)验证用户。此设置要求您输入以下值:- 用户名
- 密码
- 组名称
- Secret
如果远程服务器为 IKE 交换指定本地标识符,在
Remote ID字段输入具体字符串。在运行 Libreswan 的远程服务器中,这个值在服务器的leftid参数中设定。
(可选)点击高级按钮配置附加设置。您可以配置以下设置:
身份识别
Domain- 如果需要,输入域名。
安全性
Phase1 Algorithms对应于ikeLibreswan 参数。输入用来验证和设置加密频道的算法。Phase2 Algorithms对应于espLibreswan 参数。输入用于IPsec的算法。检查
Disable PFS字段关闭 Perfect Forward Secrecy(PFS)以确保与不支持 PFS 的旧服务器兼容。Phase1 Lifetime对应于ikelifetimeLibreswan 参数。此参数定义用于加密流量的密钥的有效期。Phase2 Lifetime对应于salifetimeLibreswan 参数。这个参数定义安全关联有效期。
连接性
Remote network对应于rightsubnetLibreswan 参数,并定义应该通过 VPN 访问的目标专用远程网络。检查
narrowing字段以启用缩小功能。请注意,它只在 IKEv2 协商中有效。Enable fragmentation对应于fragmentationLibreswan 参数,并定义是否允许 IKE 分段。有效值为yes(默认)或no。Enable Mobike对应于mobikeLibreswan 参数。参数定义是否允许移动和多功能协议(MOBIKE)(RFC 4555)启用连接来迁移其端点而无需从头开始重启连接。这可用于在有线、无线或者移动数据连接之间进行切换的移动设备。值为no(默认)或yes。
在
IPv4 Settings标签中,选择 IP 分配方法,并(可选)设置额外的静态地址、DNS 服务器、搜索域和路由。
保存连接。
关闭
nm-connection-editor。
注意
当您点 + 按钮添加新连接时, NetworkManager 会为那个连接创建新配置文件,然后打开同一个对话框来编辑现有连接。这两个对话框之间的区别在于现有连接配置集有详情菜单条目。
其它资源
- 有关支持的 IPsec 参数的详情,请查看
nm-settings-libreswan(5)man page。
22.3. 相关信息
- 有关使用 IPsec 配置 VPN 的详情,请参考 安全网络 文档中 的使用 IPsec 配置 VPN 章节。
第 23 章 创建 dummy 接口
作为 Red Hat Enterprise Linux 用户,您可以创建并使用 dummy 网络接口进行调试和测试。dummy 接口提供了一个设备来路由数据包而无需实际传送数据包。它可让您创建使用网络管理器(NetworkManager)管理的其他回送设备,使不活跃 SLIP(Serial Line Internet Protocol)地址类似本地程序的实际地址。
23.1. 使用 nmcli 使用 IPv4 和 IPv6 地址创建 dummy 接口
您可以创建带有各种设置的 dummy 接口。这个步骤描述了如何使用 IPv4 和 IPv6 地址创建 dummy 接口。创建 dummy 接口后,NetworkManager 会自动将其分配给默认的 public 防火墙区域。
注意
要配置没有 IPv4 或 IPv6 地址的 dummy 接口,请将 ipv4.method 和 ipv6.method 参数设置为 disabled。否则,IP 自动配置失败,NetworkManager 会取消激活连接并删除 dummy 设备。
流程
要创建一个名为 dummy0 的、带有静态 IPv4 和 IPv6 地址的 dummy 接口,请输入:
xxxxxxxxxx# nmcli connection add type dummy ifname dummy0 ipv4.method manual ipv4.addresses 192.0.2.1/24 ipv6.method manual ipv6.addresses 2001:db8:2::1/64可选: 要查看 dummy 接口,请输入:
xxxxxxxxxx# nmcli connection showNAME UUID TYPE DEVICEenp1s0 db1060e9-c164-476f-b2b5-caec62dc1b05 ethernet ens3dummy-dummy0 aaf6eb56-73e5-4746-9037-eed42caa8a65 dummy dummy0
其它资源
- The nm-settings(5) man page
第 24 章 配置 IP 隧道
与 VPN 类似,IP 隧道通过网络(如互联网)直接连接两个网络。然而,不是所有的隧道协议都支持加密。
两个建立隧道网络的路由器至少需要两个接口:
- 一个连接到本地网络的接口
- 一个连接到建立隧道的网络的接口。
要建立隧道,您可以在两个路由器中使用来自远程子网的 IP 地址创建一个虚拟接口。
NetworkManager 支持以下 IP 隧道:
- 通用路由封装(GRE)
- IPv6 上的通用路由封装(IP6GRE)
- 通用路由封装终端接入点(GRETAP)
- 通用路由登录在 IPv6(IP6GRETAP)上
- IPv4 over IPv4(IPIP)
- IPv4 over IPv6(IPIP6)
- IPv6 over IPv6(IP6IP6)
- 简单的互联网转换(SIT)
根据类型,这些通道在 Open Systems Interconnection(OSI)的第 2 层或 3 层动作。
24.1. 使用 nmcli 配置 IPIP 隧道来封装 IPv4 数据包中的 IPv4 流量
IP over IP(IPIP)隧道在 OSI 层 3 上运行,并封装 IPv4 数据包中的 IPv4 流量,如 RFC 2003 所述。
重要
通过 IPIP 隧道发送的数据没有加密。出于安全考虑,只在已经加密的数据中使用隧道,比如 HTTPS。
请注意,IPIP 隧道只支持单播数据包。如果您需要支持多播的 IPv4 隧道,请参考 第 24.2 节 “使用 nmcli 配置 GRE 隧道来封装 IPv4 数据包中的层 3 流量”。
此流程描述了如何在两个 RHEL 路由器之间创建 IPIP 隧道以通过互联网连接两个内部子网,如下图所示:
先决条件
- 每个 RHEL 路由器都有一个网络接口,它连接到其本地子网。
- 每个 RHEL 路由器都有一个网络接口,它连接到互联网。
- 您需要通过隧道发送的流量是 IPv4 单播。
流程
在网络 A 的 RHEL 路由器上:
创建名为
tun0的 IPIP 隧道接口:xxxxxxxxxx# nmcli connection add type ip-tunnel ip-tunnel.mode ipip con-name tun0 ifname tun0 remote 198.51.100.5 local 203.0.113.10remote和local参数设置远程和本地路由器的公共 IP 地址。将 IPv4 地址设置为
tun0设备:xxxxxxxxxx# nmcli connection modify tun0 ipv4.addresses '10.0.1.1/30'请注意,有两个可用的 IP 地址的
/30子网足以满足隧道的需要。将
tun0连接配置为使用手动 IPv4 配置:xxxxxxxxxx# nmcli connection modify tun0 ipv4.method manual添加将流量路由到
172.16.0.0/24网络的静态路由到路由器 B 的隧道 IP:xxxxxxxxxx# nmcli connection modify tun0 +ipv4.routes "172.16.0.0/24 10.0.1.2"启用
tun0连接。xxxxxxxxxx# nmcli connection up tun0启用数据包转发:
xxxxxxxxxx# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf# sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
在网络 B 中的 RHEL 路由器中:
创建名为
tun0的 IPIP 隧道接口:xxxxxxxxxx# nmcli connection add type ip-tunnel ip-tunnel.mode ipip con-name tun0 ifname tun0 remote 203.0.113.10 local 198.51.100.5remote和local参数设置远程和本地路由器的公共 IP 地址。将 IPv4 地址设置为
tun0设备:xxxxxxxxxx# nmcli connection modify tun0 ipv4.addresses '10.0.1.2/30'将
tun0连接配置为使用手动 IPv4 配置:xxxxxxxxxx# nmcli connection modify tun0 ipv4.method manual添加将流量路由到
192.0.2.0/24网络的静态路由到路由器 A 的隧道 IP:xxxxxxxxxx# nmcli connection modify tun0 +ipv4.routes "192.0.2.0/24 10.0.1.1"启用
tun0连接。xxxxxxxxxx# nmcli connection up tun0启用数据包转发:
xxxxxxxxxx# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf# sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
验证步骤
从每个 RHEL 路由器中,ping 路由器的内部接口的 IP 地址:
在路由器 A 中,ping
172.16.0.1:xxxxxxxxxx# ping 172.16.0.1在路由器 B 中,ping
192.0.2.1:xxxxxxxxxx# ping 192.0.2.1
其它资源
- 有关使用
nmcli的详情,请查看nmcliman page。 - 有关您可以使用
nmcli设定的隧道设置的详情,请查看nm-settings(5)man page 中的ip-tunnel settings部分。
24.2. 使用 nmcli 配置 GRE 隧道来封装 IPv4 数据包中的层 3 流量
Generic Routing Encapsulation(GRE)隧道封装 IPv4 数据包中的第 3 层流量,如 RFC 2784 所述。GRE 隧道可以使用有效的以太网类型封装任何第 3 层协议。
重要
通过 GRE 隧道发送的数据没有加密。出于安全考虑,只在已经加密的数据中使用隧道,比如 HTTPS。
此流程描述了如何在两个 RHEL 路由器之间创建 GRE 隧道以通过互联网连接两个内部子网,如下图所示:
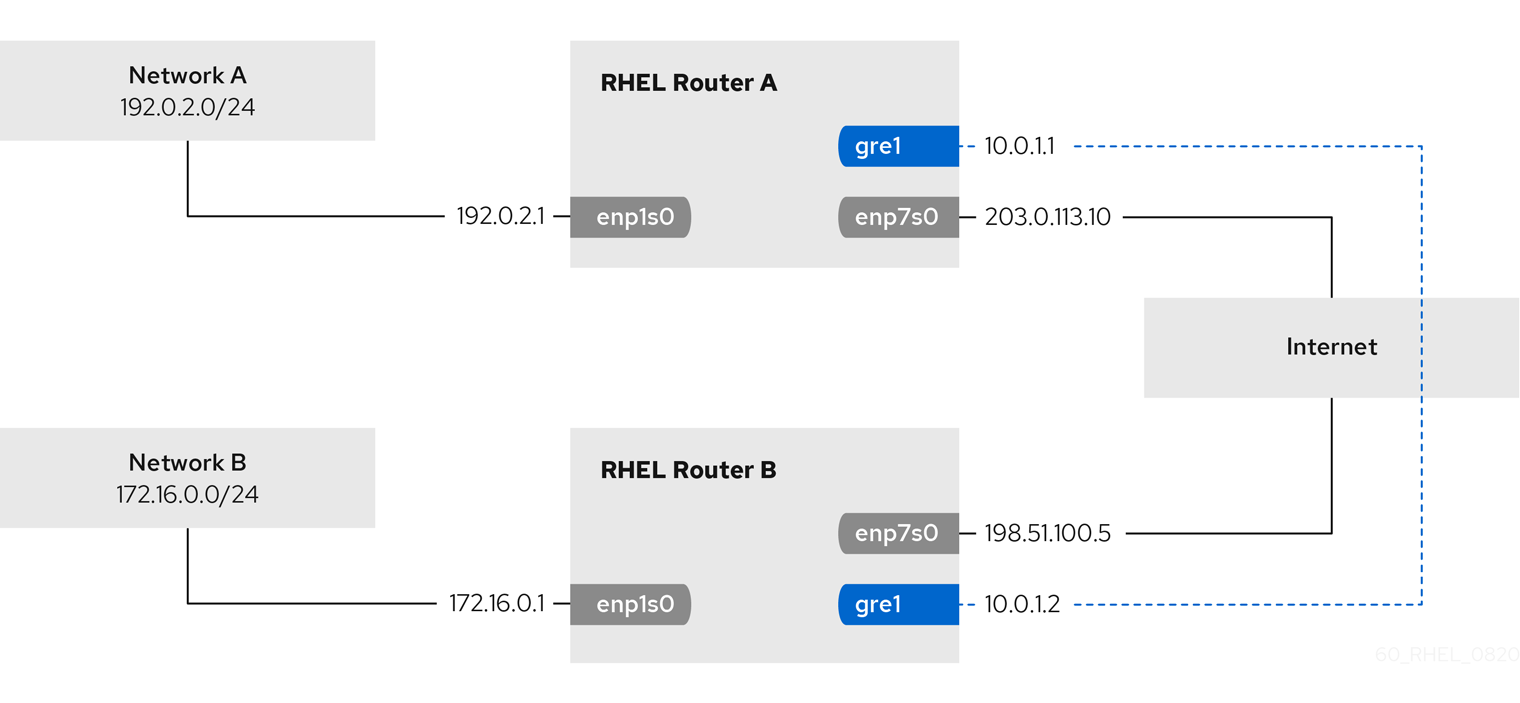
注意
gre0 设备名称被保留。为该设备使用 gre1 或者不同名称。
先决条件
- 每个 RHEL 路由器都有一个网络接口,它连接到其本地子网。
- 每个 RHEL 路由器都有一个网络接口,它连接到互联网。
流程
在网络 A 的 RHEL 路由器上:
创建名为
gre1的 GRE 隧道接口:xxxxxxxxxx# nmcli connection add type ip-tunnel ip-tunnel.mode gre con-name gre1 ifname gre1 remote 198.51.100.5 local 203.0.113.10remote和local参数设置远程和本地路由器的公共 IP 地址。将 IPv4 地址设置为
gre1设备:xxxxxxxxxx# nmcli connection modify gre1 ipv4.addresses '10.0.1.1/30'请注意,有两个可用的 IP 地址的
/30子网足以满足隧道的需要。将
gre1连接配置为使用手动 IPv4 配置:xxxxxxxxxx# nmcli connection modify gre1 ipv4.method manual添加将流量路由到
172.16.0.0/24网络的静态路由到路由器 B 的隧道 IP:xxxxxxxxxx# nmcli connection modify tun0 +ipv4.routes "172.16.0.0/24 10.0.1.2"启用
gre1连接。xxxxxxxxxx# nmcli connection up gre1启用数据包转发:
xxxxxxxxxx# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf# sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
在网络 B 中的 RHEL 路由器中:
创建名为
gre1的 GRE 隧道接口:xxxxxxxxxx# nmcli connection add type ip-tunnel ip-tunnel.mode ipip con-name gre1 ifname gre1 remote 203.0.113.10 local 198.51.100.5remote和local参数设置远程和本地路由器的公共 IP 地址。将 IPv4 地址设置为
gre1设备:xxxxxxxxxx# nmcli connection modify gre1 ipv4.addresses '10.0.1.2/30'将
gre1连接配置为使用手动 IPv4 配置:xxxxxxxxxx# nmcli connection modify gre1 ipv4.method manual添加将流量路由到
192.0.2.0/24网络的静态路由到路由器 A 的隧道 IP:xxxxxxxxxx# nmcli connection modify tun0 +ipv4.routes "192.0.2.0/24 10.0.1.1"启用
gre1连接。xxxxxxxxxx# nmcli connection up gre1启用数据包转发:
xxxxxxxxxx# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf# sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
验证步骤
从每个 RHEL 路由器中,ping 路由器的内部接口的 IP 地址:
在路由器 A 中,ping
172.16.0.1:xxxxxxxxxx# ping 172.16.0.1在路由器 B 中,ping
192.0.2.1:xxxxxxxxxx# ping 192.0.2.1
其它资源
- 有关使用
nmcli的详情,请查看nmcliman page。 - 有关您可以使用
nmcli设定的隧道设置的详情,请查看nm-settings(5)man page 中的ip-tunnel settings部分。
24.3. 配置 GRETAP 隧道来通过 IPv4 传输以太网帧
Generic Routing Encapsulation Terminal Access Point(GRETAP)隧道在 OSI 级别 2 中运行,并封装 IPv4 数据包中的以太网流量,如 RFC 2784 所述。
重要
通过 GRETAP 隧道发送的数据没有加密。出于安全考虑,通过 VPN 或不同的加密连接建立隧道。
此流程描述了如何在两个 RHEL 路由器之间创建 GRETAP 隧道以使用桥接连接两个网络,如下图所示:
注意
gretap0 设备名称被保留。为该设备使用 gretap1 或者不同名称。
先决条件
- 每个 RHEL 路由器都有一个网络接口,它连接到其本地网络,接口没有分配 IP 配置。
- 每个 RHEL 路由器都有一个网络接口,它连接到互联网。
流程
在网络 A 的 RHEL 路由器上:
创建名为
bridge0的网桥接口:xxxxxxxxxx# nmcli connection add type bridge con-name bridge0 ifname bridge0配置网桥的 IP 设置:
xxxxxxxxxx# nmcli connection modify bridge0 ipv4.addresses '192.0.2.1/24'# nmcli connection modify bridge0 ipv4.method manual为连接到本地网络的接口添加新连接配置集到网桥:
xxxxxxxxxx# nmcli connection add type ethernet slave-type bridge con-name bridge0-port1 ifname enp1s0 master bridge0为网桥添加 GRETAP 隧道接口的新连接配置集:
xxxxxxxxxx# nmcli connection add type ip-tunnel ip-tunnel.mode gretap slave-type bridge con-name bridge0-port2 ifname gretap1 remote 198.51.100.5 local 203.0.113.10 master bridge0remote和local参数设置远程和本地路由器的公共 IP 地址。可选:如果您不需要,禁用生成树协议(STP):
xxxxxxxxxx# nmcli connection modify bridge0 bridge.stp no默认情况下,STP 被启用并导致在使用连接前出现延迟。
配置激活
bridge0连接会自动激活网桥的从设备:xxxxxxxxxx# nmcli connection modify bridge0 connection.autoconnect-slaves 1激活
bridge0连接:xxxxxxxxxx# nmcli connection up bridge0
在网络 B 中的 RHEL 路由器中:
创建名为
bridge0的网桥接口:xxxxxxxxxx# nmcli connection add type bridge con-name bridge0 ifname bridge0配置网桥的 IP 设置:
xxxxxxxxxx# nmcli connection modify bridge0 ipv4.addresses '192.0.2.2/24'# nmcli connection modify bridge0 ipv4.method manual为连接到本地网络的接口添加新连接配置集到网桥:
xxxxxxxxxx# nmcli connection add type ethernet slave-type bridge con-name bridge0-port1 ifname enp1s0 master bridge0为网桥添加 GRETAP 隧道接口的新连接配置集:
xxxxxxxxxx# nmcli connection add type ip-tunnel ip-tunnel.mode gretap slave-type bridge con-name bridge0-port2 ifname gretap1 remote 203.0.113.10 local 198.51.100.5 master bridge0remote和local参数设置远程和本地路由器的公共 IP 地址。可选:如果您不需要,禁用生成树协议(STP):
xxxxxxxxxx# nmcli connection modify bridge0 bridge.stp no配置激活
bridge0连接会自动激活网桥的从设备:xxxxxxxxxx# nmcli connection modify bridge0 connection.autoconnect-slaves 1激活
bridge0连接:xxxxxxxxxx# nmcli connection up bridge0
验证步骤
在两个路由器中,验证
enp1s0和gretap1连接是否已连接,并且CONNECTION列显示了从的连接名称:xxxxxxxxxx# nmcli devicenmcli deviceDEVICE TYPE STATE CONNECTION...bridge0 bridge connected bridge0enp1s0 ethernet connected bridge0-port1gretap1 iptunnel connected bridge0-port2从每个 RHEL 路由器中,ping 路由器的内部接口的 IP 地址:
在路由器 A 中,ping
192.0.2.2:xxxxxxxxxx# ping 192.0.2.2在路由器 B 中,ping
192.0.2.1:xxxxxxxxxx# ping 192.0.2.1
其它资源
- 有关使用
nmcli的详情,请查看nmcliman page。 - 有关您可以使用
nmcli设定的隧道设置的详情,请查看nm-settings(5)man page 中的ip-tunnel settings部分。
24.4. 其它资源
- 有关隧道接口列表以及使用
ip程序临时配置隧道的详情,请查看ip-link(8)man page。
第 25 章 多路径 TCP 入门
重要
多路径 TCP 仅作为技术预览提供。红帽产品服务级别协议(SLA)不支持技术预览功能,且其功能可能并不完善,因此红帽不建议在生产环境中使用它们。这些预览可让用户早期访问将来的产品功能,让用户在开发过程中测试并提供反馈意见。
如需有关 技术预览功能支持范围 的信息,请参阅红帽客户门户网站中的技术预览功能支持范围。
多路径 TCP(MPTCP)是传输控制协议(TCP)的扩展。使用互联网协议(IP),主机可将数据包发送到目的地。TCP 可确保通过互联网可靠地提供数据,并自动调整其带宽以响应网络负载。
以下是 MPTCP 的优点:
- 它为带有两个或者多个网络接口的设备启用 TCP。
- 它允许用户同时使用不同的网络接口或从一个连接间无缝切换。
- 它提高了网络中的资源使用量以及网络故障的恢复能力。
本节描述了如何:
- 创建新的 MPTCP 连接,
- 使用
iproute2为 MPTCP 连接添加新的子流和 IP 地址,以及 - 在内核中禁用 MPTCP 以避免使用 MPTCP 连接的应用程序。
25.1. 准备 RHEL 启用 MPTCP 支持
一些应用程序原生支持 MPTCP。大多数情况下, connection 和 stream-based 套接字在调用操作系统的 socket()里请求 TCP 协议。您可以在 RHEL 中为原生 MPTCP 支持使用 sysctl 工具启用 MPTCP 支持。MPTCP 实现也被设计为允许 MPTCP 协议用于向向内核发出 IPPROTO_TCP 调用的应用程序使用 MPTCP 协议。
此流程描述了如何启用 MPTCP 支持并准备 RHEL,以便使用 SystemTap 脚本启用 MPTCP 系统范围。
先决条件
安装以下软件包:
kernel-debuginfokernel-debuginfo-commonsystemtapsystemtap-develkernel-develnmap-ncat
流程
在内核中启用 MPTCP 套接字:
xxxxxxxxxx# echo "net.mptcp.enabled=1" > /etc/sysctl.d/90-enable-MPTCP.conf# sysctl -p /etc/sysctl.d/90-enable-MPTCP.conf使用以下内容创建
mptcp.stap文件:xxxxxxxxxx#! /usr/bin/env stap%{#include <linux/in.h>#include <linux/ip.h>%}/* according to [1], RSI contains 'type' and RDX* contains 'protocol'.* [1] https://github.com/torvalds/linux/blob/master/arch/x86/entry/entry_64.S#L79*/function mptcpify () %{if (CONTEXT->kregs->si == SOCK_STREAM &&(CONTEXT->kregs->dx == IPPROTO_TCP ||CONTEXT->kregs->dx == 0)) {CONTEXT->kregs->dx = IPPROTO_MPTCP;STAP_RETVALUE = 1;} else {STAP_RETVALUE = 0;}%}probe kernel.function("__sys_socket") {if (mptcpify() == 1) {printf("command %16s mptcpified\n", execname());}}将 TCP 套接字替换为 MPTCP:
#
stap -vg mptcp.stap注: 使用 Ctrl+C 将连接从 MPTCP 转换回 TCP。
启动侦听 TCP 端口 4321 的服务器:
#
ncat -4 -l *4321*连接到服务器并交换流量。例如,这里的客户端将 "Hello world" 写入服务器 5 次,然后它终止连接。
xxxxxxxxxx# ncat -4 192.0.2.1 4321Hello world 1Hello world 2Hello world 3Hello world 4Hello world 5按 Ctrl+D 退出。
验证步骤
验证内核中是否启用了 MPTCP:
xxxxxxxxxx# sysctl -a | grep mptcp.enablednet.mptcp.enabled = 1在
mptcp.stap脚本安装内核探测后,会在内核dmesg输出中出现以下警告:xxxxxxxxxx# dmesg...[ 1752.694072] Kprobes globally unoptimized[ 1752.730147] stap_1ade3b3356f3e68765322e26dec00c3d_1476: module_layout: kernel tainted.[ 1752.732162] Disabling lock debugging due to kernel taint[ 1752.733468] stap_1ade3b3356f3e68765322e26dec00c3d_1476: loading out-of-tree module taints kernel.[ 1752.737219] stap_1ade3b3356f3e68765322e26dec00c3d_1476: module verification failed: signature and/or required key missing - tainting kernel建立连接后,验证
ss输出以查看特定于子流的状态:xxxxxxxxxx# ss -nti '( dport :4321 )' dst 192.0.2.1State Recv-Q Send-Q Local Address:Port Peer Address:Port ProcessESTAB 0 0 192.0.2.2:60874 192.0.2.1:4321cubic wscale:7,7 rto:201 rtt:0.042/0.017 mss:1448 pmtu:1500 rcvmss:536 advmss:1448 cwnd:10 bytes_sent:64 bytes_$cked:65 segs_out:6 segs_in:5 data_segs_out:4 send 2758095238bps lastsnd:57 lastrcv:3054 lastack:57 pacing_rate 540361516$bps delivery_rate 413714280bps delivered:5 rcv_space:29200 rcv_ssthresh:29200 minrtt:0.009 tcp-ulp-mptcp flags:Mmec token:0000(id:0)/4bffe73d(id:0) seq:c11f40d6c5337463 sfseq:1 ssnoff:f7455705 maplen:0使用
tcpdump捕获流量并检查 MPTCP 子选项的使用:xxxxxxxxxx# tcpdump -tnni interface TCP 端口 4321client Out IP 192.0.2.2.60802 > 192.0.2.1.4321: Flags [S], seq 3420255622, win 29200, options [mss 1460,sackOK,TS val 411 4539945 ecr 0,nop,wscale 7,mptcp capable v1], length 0client In IP 192.0.2.1.4321 > 192.0.2.2.60802: Flags [S.], seq 2619315374, ack 3420255623, win 28960, options [mss 1460 sackOK,TS val 3241564233 ecr 4114539945,nop,wscale 7,mptcp capable v1 {0xb6f8dc721aee7f64}], length 0client Out IP 192.0.2.2.60802 > 192.0.2.1.4321: Flags [.], ack 1, win 229, options [nop,nop,TS val 4114539945 ecr 3241564 233,mptcp capable v1 {0xcc58d5d632a32d13,0xb6f8dc721aee7f64}], length 0client Out IP 192.0.2.2.60802 > 192.0.2.1.4321: Flags [P.], seq 1:17, ack 1, win 229, options [nop,nop,TS val 4114539945 ecr 3241564233,mptcp capable v1 {0xcc58d5d632a32d13,0xb6f8dc721aee7f64},nop,nop], length 16client In IP 192.0.2.1.4321 > 192.0.2.2.60802: Flags [.], ack 17, win 227, options [nop,nop,TS val 3241564233 ecr 411459945,mptcp dss ack 1105509586894558345], length 0client Out IP 192.0.2.2.60802 > 192.0.2.1.4321: Flags [P.], seq 17:33, ack 1, win 229, options [nop,nop,TS val 4114540939 ecr 3241564233,mptcp dss ack 13265586846326199424 seq 105509586894558345 subseq 17 len 16,nop,nop], length 16运行这个命令时需要
tcpdump软件包。
其它资源
- 如需更多信息,请参阅如何为 RHEL 系统下载或安装 debuginfo 软件包?
- 有关
IPPROTO_TCP的详情,请参考tcp(7)man page。
25.2. 使用 iproute2 通知应用程序有关多个可用路径
默认情况下,MPTCP 套接字以一个子流开始,但您可以在第一次创建它后向连接添加新的子流和 IP 地址。此流程描述了如何为子流和 IP 地址更新每个连接限制,并在 MPTCP 连接中添加新的 IP 地址(端点)。
请注意,MPTCP 尚不支持为同一套接字混合 IPv6 和 IPv4 端点。使用属于同一地址系列的端点。
流程
将每个连接和 IP 地址限值设置为服务器上的 1:
#
ip mptcp limits set subflow *1*在客户端中将每个连接和 IP 地址限制设置为 1:
#
ip mptcp limits set subflow *1* add_addr_accepted *1*在服务器中添加 IP 地址 198.51.100.1 作为新的 MPTCP 端点:
#
ip mptcp endpoint add *198.51.100.1* dev *enp1s0* *signal*重要
您可以为
subflow、backup、signal设置以下值。将标签设置为:signal,在三方握手完成后发送ADD_ADDR数据包subflow,由客户端发送MP_JOIN SYNbackup,将端点设置为备份地址
用
-k参数启动服务器绑定到 0.0.0.0,以防止 [systemitem]'ncat' 在接受第一个连接后关闭侦听套接字,并让服务器拒绝客户端执行的MP_JOIN SYN。#
ncat -4 0.0.0.0 -k -l *4321*启动客户端并连接到服务器以交换流量。例如,这里的客户端将 "Hello world" 写入服务器 5 次,然后它终止连接。
xxxxxxxxxx# ncat -4 192.0.2.1 4321Hello world 1Hello world 2Hello world 3Hello world 4Hello world 5按 Ctrl+D 退出。
验证步骤
验证连接和 IP 地址限制:
#
ip mptcp limit show验证新添加的端点:
#
ip mptcp endpoint show使用
tcpdump捕获流量并检查 MPTCP 子选项的使用:xxxxxxxxxx# tcpdump -tnni interface TCP 端口 4321client Out IP 192.0.2.2.56868 > 192.0.2.1.4321: Flags [S], seq 3107783947, win 29200, options [mss 1460,sackOK,TS val 2568752336 ecr 0,nop,wscale 7,mptcp capable v1], length 0client In IP 192.0.2.1.4321 > 192.0.2.2.56868: Flags [S.], seq 4222339923, ack 3107783948, win 28960, options [mss 1460,sackOK,TS val 1713130246 ecr 2568752336,nop,wscale 7,mptcp capable v1 {0xf51c07a47cc2ba75}], length 0client Out IP 192.0.2.2.56868 > 192.0.2.1.4321: Flags [.], ack 1, win 229, options [nop,nop,TS val 2568752336 ecr 1713130246,mptcp capable v1 {0xb243376cc5af60bd,0xf51c07a47cc2ba75}], length 0client Out IP 192.0.2.2.56868 > 192.0.2.1.4321: Flags [P.], seq 1:17, ack 1, win 229, options [nop,nop,TS val 2568752336 ecr 1713130246,mptcp capable v1 {0xb243376cc5af60bd,0xf51c07a47cc2ba75},nop,nop], length 16client In IP 192.0.2.1.4321 > 192.0.2.2.56868: Flags [.], ack 17, win 227, options [nop,nop,TS val 1713130246 ecr 2568752336,mptcp add-addr id 1 198.51.100.1 hmac 0xe445335073818837,mptcp dss ack 5562689076006296132], length 0client Out IP 198.51.100.2.42403 > 198.51.100.1.4321: Flags [S], seq 3356992178, win 29200, options [mss 1460,sackOK,TS val 4038525523 ecr 0,nop,wscale 7,mptcp join backup id 0 token 0xad58df1 nonce 0x74a8137f], length 0client In IP 198.51.100.1.4321 > 198.51.100.2.42403: Flags [S.], seq 1680863152, ack 3356992179, win 28960, options [mss 1460,sackOK,TS val 4213669942 ecr 4038525523,nop,wscale 7,mptcp join backup id 0 hmac 0x9eff7a1bf4e65937 nonce 0x77303fd8], length 0client Out IP 198.51.100.2.42403 > 198.51.100.1.4321: Flags [.], ack 1, win 229, options [nop,nop,TS val 4038525523 ecr 4213669942,mptcp join hmac 0xdfdc0129424f627ea774c094461328ce49d195bc], length 0client In IP 198.51.100.1.4321 > 198.51.100.2.42403: Flags [.], ack 1, win 227, options [nop,nop,TS val 4213669942 ecr 4038525523,mptcp dss ack 5562689076006296132], length 0运行这个命令时需要
tcpdump软件包。
其它资源
- 有关可用端点标记的更多信息,请参阅
ip-mptcp(8)man page。
25.3. 在内核中禁用多路径 TCP
这个步骤描述了如何在内核中禁用 MPTCP 选项。
流程
禁用
mptcp.enabled选项。xxxxxxxxxx# echo "net.mptcp.enabled=0" > /etc/sysctl.d/90-enable-MPTCP.conf# sysctl -p /etc/sysctl.d/90-enable-MPTCP.conf
验证步骤
验证
mptcp.enabled是否在内核中被禁用。xxxxxxxxxx# sysctl -a | grep mptcp.enablednet.mptcp.enabled = 0
第 26 章 配置 DNS 服务器顺序
大多数应用程序使用 getaddrinfo() 库的 glibc 功能来解决 DNS 请求。默认情况下,glibc 将所有 DNS 请求发送到 /etc/resolv.conf 文件中指定的第一个 DNS 服务器。如果这个服务器没有回复,Red Hat Enterprise Linux 会使用这个文件中的下一个服务器。
这部分论述了如何自定义 DNS 服务器顺序。
26.1. NetworkManager 如何在 /etc/resolv.conf 中对 DNS 服务器进行排序
NetworkManager 根据以下规则对 /etc/resolv.conf 文件中的 DNS 服务器排序:
如果只有一个连接配置集,NetworkManager 将使用那个连接中指定的 IPv4 和 IPv6 DNS 服务器顺序。
如果激活多个连接配置集,NetworkManager 会根据 DNS 优先级值对 DNS 服务器进行排序。如果您设置 DNS 优先级,NetworkManager 的行为取决于
dns参数中设置的值。您可以在文件/etc/NetworkManager/NetworkManager.conf中的[main]部分设置此参数:dns=default,或如果没有设置dns参数:NetworkManager 根据每个连接中的
ipv4.dns-priority和ipv6.dns-priority参数将 DNS 服务器从不同的连接中排序。如果未设置值,或者您将
ipv4.dns-priority和ipv6.dns-priority设置为0,NetworkManager 将使用全局默认值。请参阅 “DNS 优先级参数的默认值”一节。dns=dnsmasq或dns=systemd-resolved:当您使用这些设置之一时,NetworkManager 在
/etc/resolv.conf文件中将127.0.0.1设置为dnsmasq,或将127.0.0.53设置为nameserver条目。dnsmasq和systemd-resolved服务都转发网络管理器(NetworkManager)中与连接中指定的 DNS 服务器连接中设置的搜索域的查询,并将查询转发到其他域与默认路由的连接。当多个连接有相同的搜索域集时,dnsmasq和systemd-resolved会将对这个域的查询转发到具有最低优先级值的连接中的 DNS 服务器。
DNS 优先级参数的默认值
NetworkManager 对连接使用以下默认值:
50对于 VPN 连接100对于其他连接
有效的 DNS 优先级值:
您可以将全局默认和具体连接 ipv4.dns-priority 和 ipv6.dns-priority 参数设置为 -2147483647 和 2147483647 之间的值。
低的值具有更高的优先级。
负值具有一个特殊的效果,它会排除其他带有更大值的配置。例如,如果至少有一个连接具有负优先级值,NetworkManager 只使用在连接配置集中指定的具有最低优先级的 DNS 服务器。
如果多个连接具有相同的 DNS 优先级,NetworkManager 会按照以下顺序排列 DNS 的优先顺序:
- VPN 连接
- 带有活跃的默认路由的连接。活跃的默认路由是最低指标的默认路由。
其它资源
- 有关
/etc/resolv.conf文件中 NetworkManager 排序 DNS 服务器条目的详情,请查看nm-settings(5)手册页中的ipv4和ipv6部分中的dns-priority参数描述。 - 有关使用
systemd-resolved为不同域使用不同 DNS 服务器的详情,请参考 第 33 章 在不同域中使用不同的 DNS 服务器。
26.2. 设置 NetworkManager 范围默认 DNS 服务器优先级值
NetworkManager 为连接使用以下 DNS 优先级默认值:
50对于 VPN 连接100对于其他连接
这部分论述了如何使用 IPv4 和 IPv6 连接的自定义默认值覆盖这些系统范围的默认值。
流程
编辑
/etc/NetworkManager/NetworkManager.conf文件:添加
[connection]部分(如果不存在):xxxxxxxxxx[connection]在
[connection]部分添加自定义默认值。例如:要将 IPv4 和 IPv6 的新默认值设置为200,请添加:xxxxxxxxxxipv4.dns-priority=200ipv6.dns-priority=200您可以将参数设置为
-2147483647和2147483647间的值。请注意,将参数设置为0可启用内置的默认值(50用于 VPN 连接,其它连接为100)。
重新载入
NetworkManager服务:xxxxxxxxxx# systemctl reload NetworkManager
其它资源
- 有关为所有网络管理器连接设置默认值的详情,请参考
NetworkManager.conf(5)man page 中的Connection Section。
26.3. 设置网络管理器连接的 DNS 优先级
这部分论述了如何在 NetworkManager 创建或更新 /etc/resolv.conf 文件时定义 DNS 服务器的顺序。
请注意,只有在您配置了多个与不同 DNS 服务器的连接时,设置 DNS 优先级才有意义。如果您只有一个与多个 DNS 服务器的连接,请在连接配置集中按首选顺序手动设置 DNS 服务器。
先决条件
- 系统配置了多个网络管理器连接。
- 系统在
/etc/NetworkManager/NetworkManager.conf文件中没有设置dns参数,或者将参数设置为default。
流程
另外,还可显示可用的连接:
xxxxxxxxxx# nmcli connection showNAME UUID TYPE DEVICEExample_con_1 d17ee488-4665-4de2-b28a-48befab0cd43 ethernet enp1s0Example_con_2 916e4f67-7145-3ffa-9f7b-e7cada8f6bf7 ethernet enp7s0...设置
ipv4.dns-priority和ipv6.dns-priority参数。例如,为Example_con_1连接将两个参数设置为10:xxxxxxxxxx# nmcli connection modify Example_con_1 ipv4.dns-priority 10 ipv6.dns-priority 10另外,还可为其他连接重复前面的步骤。
重新激活您更新的连接:
xxxxxxxxxx# nmcli connection up Example_con_1
验证步骤
显示
/etc/resolv.conf文件的内容以验证 DNS 服务器顺序是否正确:xxxxxxxxxx# cat /etc/resolv.conf
第 27 章 使用 ifcfg 文件配置 ip 网络
这部分论述了如何通过编辑 ifcfg 文件手动配置网络接口。
接口配置(ifcfg)文件可控制不同网络设备的软件接口。当系统引导时,它使用这些文件来决定启动哪些界面以及如何进行配置。这些文件通常命名为 ifcfg-*name*,后缀 name 指的是配置文件控制的设备名称。通常 ifcfg 文件的后缀与配置文件中 DEVICE 指令给出的字符串相同。
27.1. 使用 ifcfg 文件配置带有静态网络设置的接口
这个步骤描述了如何使用 ifcfg 文件配置网络接口。
流程
要使用
ifcfg文件配置带有静态网络设置的接口,对于名为enp1s0的接口,在包含以下内容的/etc/sysconfig/network-scripts/目录中创建一个名为ifcfg-enp1s0的文件:对于
IPv4配置:xxxxxxxxxxDEVICE=enp1s0BOOTPROTO=noneONBOOT=yesPREFIX=24IPADDR=10.0.1.27GATEWAY=10.0.1.1对于
IPv6配置:xxxxxxxxxxDEVICE=enp1s0BOOTPROTO=noneONBOOT=yesIPV6INIT=yesIPV6ADDR=2001:db8:1::2/64
其它资源
- 有关测试连接的更多信息,请参阅 第 38 章 测试基本网络设置。
- 更多
IPv6ifcfg 配置选项请查看 *nm-settings-ifcfg-rh(5)* man page。
27.2. 使用 ifcfg 文件配置带有动态网络设置的接口
这个步骤描述了如何使用 ifcfg 文件配置带有动态网络设置的网络接口。
流程
要使用
ifcfg文件配置名为 em1 的接口,请在包含以下内容的/etc/sysconfig/network-scripts/目录中创建一个名为ifcfg-em1的文件:xxxxxxxxxxDEVICE=em1BOOTPROTO=dhcpONBOOT=yes要配置接口来向
DHCP服务器发送不同的主机名,请在ifcfg文件中添加以下行:xxxxxxxxxxDHCP_HOSTNAME=hostname要将接口配置为将不同的完全限定域名(FQDN)发送到
DHCP服务器,请在ifcfg文件中添加以下行:xxxxxxxxxxDHCP_FQDN=fully.qualified.domain.name注意
在给定的
ifcfg文件中只能使用DHCP_HOSTNAME或DHCP_FQDN指令中的一个。如果同时指定了DHCP_HOSTNAME和DHCP_FQDN,则只使用后者。要将接口配置为使用特定的
DNS服务器,请在ifcfg文件中添加以下行:xxxxxxxxxxPEERDNS=noDNS1=ip-addressDNS2=ip-address其中 ip-address 是
DNS服务器的地址。这会导致网络服务使用指定的DNS服务器更新/etc/resolv.conf。只需要一个DNS服务器地址,另一个是可选的。
27.3. 使用 ifcfg 文件管理系统范围以及专用连接配置集
这个步骤描述了如何配置 ifcfg 文件来管理系统范围以及专用连接配置集。
流程
权限与 ifcfg 文件中的 USERS 指令对应。如果没有 USERS 指令,则所有用户都可使用网络配置集。
例如,使用以下行修改
ifcfg文件,这会使连接只对列出的用户有效:xxxxxxxxxxUSERS="joe bob alice"
第 28 章 使用 NetworkManager 为特定连接禁用 IPv6
这部分论述了如何在使用 NetworkManager 管理网络接口的系统中禁用 IPv6 协议。如果您禁用 IPv6,NetworkManager 会自动在内核中设置对应的 sysctl 值。
注意
NetworkManager 服务在启动连接时设置特定的 sysctl 值。要避免意外行为,请不要手动设置 sysctl 值来禁用 IPv6。
先决条件
- 系统使用 NetworkManager 管理网络接口,这是 Red Hat Enterprise Linux 8 中的默认设置。
- 系统运行 Red Hat Enterprise Linux 8.1 或更高版本。
28.1. 使用 nmcli 在连接上禁用 IPv6
使用这个部分,通过 nmcli 实用程序禁用 IPv6 协议。
流程
另外,还可显示网络连接列表:
xxxxxxxxxx# nmcli connection showNAME UUID TYPE DEVICEExample 7a7e0151-9c18-4e6f-89ee-65bb2d64d365 ethernet enp1s0...将连接的
ipv6.method参数设置为disabled:xxxxxxxxxx# nmcli connection modify Example ipv6.method "disabled"重启网络连接:
xxxxxxxxxx# nmcli connection up Example
验证步骤
输入
ip address show命令显示设备的 IP 设置:xxxxxxxxxx# ip address show enp1s02: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000link/ether 52:54:00:6b:74:be brd ff:ff:ff:ff:ff:ffinet 192.0.2.1/24 brd 192.10.2.255 scope global noprefixroute enp1s0valid_lft forever preferred_lft forever如果没有
inet6条目,则在该设备中禁用 IPv6。验证
/proc/sys/net/ipv6/conf/*enp1s0*/disable_ipv6文件现在包含1值:xxxxxxxxxx# cat /proc/sys/net/ipv6/conf/enp1s0/disable_ipv611表示该设备禁用 IPv6。
第 29 章 手动配置 /etc/resolv.conf 文件
默认情况下,Red Hat Enterprise Linux(RHEL)8 上的网络管理器(NetworkManager)使用来自活跃网络管理器连接配置集的 DNS 设置动态地更新 /etc/resolv.conf 文件。这部分论述了如何在 /etc/resolv.conf 中禁用此功能的不同选项来手动配置 DNS 设置。
29.1. 在 NetworkManager 配置中禁用 DNS 处理
这部分论述了如何在 NetworkManager 配置中禁用 DNS 处理来手动配置 /etc/resolv.conf 文件。
流程
作为 root 用户,使用文本编辑器使用以下内容创建
/etc/NetworkManager/conf.d/90-dns-none.conf文件:xxxxxxxxxx[main]dns=none重新载入
NetworkManager服务:xxxxxxxxxx# systemctl reload NetworkManager注意
重新载入该服务后,NetworkManager 不再更新
/etc/resolv.conf文件。但是该文件的最后内容将被保留。(可选)从
Generated by NetworkManager中删除/etc/resolv.conf注释以避免混淆。
验证步骤
编辑
/etc/resolv.conf文件并手动更新配置。重新载入
NetworkManager服务:xxxxxxxxxx# systemctl reload NetworkManager显示
/etc/resolv.conf文件:xxxxxxxxxx# cat /etc/resolv.conf如果您成功禁用了 DNS 处理,NetworkManager 不会覆盖手动配置的设置。
其它资源
- 详情请查看
dnsman page 中的NetworkManager.conf(5)参数描述。
29.2. 使用符号链接替换 /etc/resolv.conf 来手动配置 DNS 设置
如果 /etc/resolv.conf 是符号链接,NetworkManager 不会自动更新 DNS 配置。这部分论述了如何使用 DNS 配置的替代文件的符号链接替换 /etc/resolv.conf。
先决条件
rc-manager选项没有设置为file。要验证,请使用NetworkManager --print-config命令。
流程
创建文件,如
/etc/resolv.conf.manually-configured,并将您的环境的 DNS 配置添加到其中。使用与原来的/etc/resolv.conf相同的参数和语法。删除
/etc/resolv.conf文件:xxxxxxxxxx# rm /etc/resolv.conf创建名为
/etc/resolv.conf的符号链接,引用/etc/resolv.conf.manually-configured:xxxxxxxxxx# ln -s /etc/resolv.conf.manually-configured /etc/resolv.conf
其它资源
- 有关您可以在
/etc/resolv.conf中设置的参数的详情,请查看resolv.conf(5)man page。 - 有关当
/etc/resolv.conf是符号链接时,为什么网络管理器(NetworkManager)无法处理 DNS 设置的更多详情,请参阅NetworkManager.conf(5)man page 中的rc-manager参数描述。
第 30 章 配置 802.3 链路设置
您可以通过修改以下配置参数来配置以太网连接的 802.3 链接设置:
802-3-ethernet.auto-negotiate802-3-ethernet.speed802-3-ethernet.duplex
您可以将 802.3 链接设置配置为以下主要模式:
- 忽略链路协商
- 强制自动协商激活
- 手动设置
speed和duplex链接设置
30.1. 使用 nmcli 工具配置 802.3 链路设置
此流程描述了如何使用 nmcli 工具配置 802.3 链路设置。
先决条件
- 必须安装并运行 NetworkManager。
流程
要忽略链路协商,请设置以下参数:
xxxxxxxxxx~]# nmcli connection modify connection_name 802-3-ethernet.auto-negotiate no 802-3-ethernet.speed 0 802-3-ethernet.duplex ""注意,即使未设置 speed 和 duplex 参数且自动协商参数设为 no,也不会禁用 auto-negotiation 参数。
要强制自动协商激活,请输入以下命令:
xxxxxxxxxx~]# nmcli connection modify connection_name 802-3-ethernet.auto-negotiate yes 802-3-ethernet.speed 0 802-3-ethernet.duplex ""这允许协商 NIC 支持的所有可用速度和双工模式。
您还可以在广告时启用自动协商功能,并只允许一个速度/双工模式。如果您要强制
1000BASE-T和10GBASE-T以太网链路配置,这非常有用,因为这些规则启用了自动协商。强制执行1000BASE-T标准:xxxxxxxxxx~]# nmcli connection modify connection_name 802-3-ethernet.auto-negotiate yes 802-3-ethernet.speed 1000 802-3-ethernet.duplex full要手动设置速度和双工链路设置,请输入以下命令:
xxxxxxxxxx~]# nmcli connection modify connection_name 802-3-ethernet.auto-negotiate no 802-3-ethernet.speed [speed in Mbit/s] 802-3-ethernet.duplex [full|half]
第 31 章 配置 ethtool offload 功能
网络接口卡可使用 TCP 卸载引擎(TOE)将某些操作卸载到网络控制器以提高网络吞吐量。
这部分论述了如何设置卸载功能。
31.1. NetworkManager 支持的卸载功能
您可以使用 NetworkManager 设置以下 ethtool 卸载功能:
- ethtool.feature-esp-hw-offload
- ethtool.feature-esp-tx-csum-hw-offload
- ethtool.feature-fcoe-mtu
- ethtool.feature-gro
- ethtool.feature-gso
- ethtool.feature-highdma
- ethtool.feature-hw-tc-offload
- ethtool.feature-l2-fwd-offload
- ethtool.feature-loopback
- ethtool.feature-lro
- ethtool.feature-ntuple
- ethtool.feature-rx
- ethtool.feature-rx-all
- ethtool.feature-rx-fcs
- ethtool.feature-rx-gro-hw
- ethtool.feature-rx-udp_tunnel-port-offload
- ethtool.feature-rx-vlan-filter
- ethtool.feature-rx-vlan-stag-filter
- ethtool.feature-rx-vlan-stag-hw-parse
- ethtool.feature-rxhash
- ethtool.feature-rxvlan
- ethtool.feature-sg
- ethtool.feature-tls-hw-record
- ethtool.feature-tls-hw-tx-offload
- ethtool.feature-tso
- ethtool.feature-tx
- ethtool.feature-tx-checksum-fcoe-crc
- ethtool.feature-tx-checksum-ip-generic
- ethtool.feature-tx-checksum-ipv4
- ethtool.feature-tx-checksum-ipv6
- ethtool.feature-tx-checksum-sctp
- ethtool.feature-tx-esp-segmentation
- ethtool.feature-tx-fcoe-segmentation
- ethtool.feature-tx-gre-csum-segmentation
- ethtool.feature-tx-gre-segmentation
- ethtool.feature-tx-gso-partial
- ethtool.feature-tx-gso-robust
- ethtool.feature-tx-ipxip4-segmentation
- ethtool.feature-tx-ipxip6-segmentation
- ethtool.feature-tx-nocache-copy
- ethtool.feature-tx-scatter-gather
- ethtool.feature-tx-scatter-gather-fraglist
- ethtool.feature-tx-sctp-segmentation
- ethtool.feature-tx-tcp-ecn-segmentation
- ethtool.feature-tx-tcp-mangleid-segmentation
- ethtool.feature-tx-tcp-segmentation
- ethtool.feature-tx-tcp6-segmentation
- ethtool.feature-tx-udp-segmentation
- ethtool.feature-tx-udp_tnl-csum-segmentation
- ethtool.feature-tx-udp_tnl-segmentation
- ethtool.feature-tx-vlan-stag-hw-insert
- ethtool.feature-txvlan
有关各个卸载功能的详情,请查看 ethtool 实用程序文档和内核文档。
31.2. 使用 NetworkManager 配置 ethtool offload 功能
本节论述了如何使用 NetworkManager 启用和禁用 ethtool 卸载功能,以及如何从 NetworkManager 连接配置集中删除功能设置。
流程
例如:要启用 RX 卸载功能并在
enp0s1连接配置集中禁用 TX 卸载,请输入:xxxxxxxxxx# nmcli con modify enp0s1 ethtool.feature-rx on ethtool.feature-tx off这个命令明确启用 RX 卸载并禁用 TX 卸载功能。
要删除之前启用或禁用的卸载功能的设置,请将功能的参数设置为
ignore。例如,要删除 TX 卸载的配置,请输入:xxxxxxxxxx# nmcli con modify enp0s1 ethtool.feature-tx ignore重新激活网络配置集:
xxxxxxxxxx# nmcli connection up enp0s1
验证步骤
使用
ethtool -k命令显示网络设备的当前卸载功能:xxxxxxxxxx# ethtool -k network_device
其它资源
- 有关
ethtool卸载功能 NetworkManager 支持的列表,请参考 第 31.1 节 “NetworkManager 支持的卸载功能”。
第 32 章 配置 MACsec
下面的部分提供了如何配置 Media Control Access Security(MACsec)的信息,它是一个 802.1AE IEEE 标准安全技术,用于以太网链路上所有流量的安全通讯。
32.1. MACsec 简介
Media Access Control Security (MACsec,IEEE 802.1AE)使用 GCM-AES-128 算法加密并验证 LAN 中的所有流量。MACsec 不仅可以保护 IP ,还可以保护地址解析协议(ARP),Neighbor Discovery(ND)或者 DHCP。IPsec 在网络层(层 3)中,SSL 或 TLS 在应用程序层(层 7),MACsec 在数据链路层(层 2)中运行。将 MACsec 与其它网络层的安全协议合并,利用这些规则提供的不同安全功能。
32.2. 在 nmcli 工具中使用 MACsec
此流程演示了如何使用 nmcli 工具配置 MACsec。
先决条件
- 网络管理器 必须正在运行。
- 您已经有一个 16 字节十六进制 CAK(
$MKA_CAK)和 32 位十六进制 CKN($MKA_CKN)。
流程
要使用
nmcli添加新连接,请输入:xxxxxxxxxx~]# nmcli connection add type macsec \con-name test-macsec+ ifname macsec0 \connection.autoconnect no \macsec.parent enp1s0 macsec.mode psk \macsec.mka-cak $MKA_CAK \macsec.mka-ckn $MKA_CKN使用您要配置的设备名称替换 macsec0。
要激活连接,请输入:
xxxxxxxxxx~]# nmcli connection up test-macsec+
在这个步骤之后,macsec0 设备会被配置并可用于网络。
32.3. 使用带有 wpa_supplicant 的 MACsec
以下操作过程演示了如何使用预共享连接关联的密钥/CAK 名称(CAK/CKN)对启用 MACsec。
流程
创建 CAK/CKN 对。例如,以下命令在十六进制表示中生成 16 字节密钥:
xxxxxxxxxx~]$ dd if=/dev/urandom count=16 bs=1 2> /dev/null | hexdump -e '1/2 "%02x"'创建
wpa_supplicant.conf配置文件并添加以下行:xxxxxxxxxxctrl_interface=/var/run/wpa_supplicanteapol_version=3ap_scan=0fast_reauth=1network={key_mgmt=NONEeapol_flags=0macsec_policy=1mka_cak=0011... # 16 bytes hexadecimalmka_ckn=2233... # 32 bytes hexadecimal}使用上一步中的值完成
wpa_supplicant.conf配置文件中的mka_cak和mka_ckn行。详情请查看
wpa_supplicant.conf(5)man page。假设您使用 wlp61s0 连接到您的网络,请使用以下命令启动 wpa_supplicant:
xxxxxxxxxx~]# wpa_supplicant -i wlp61s0 -Dmacsec_linux -c wpa_supplicant.conf
32.4. 相关信息
详情请查看 MACsec 中的新内容:使用 wpa_supplicant 设置 MACsec 和(可选)NetworkManager 文章。另外,请参阅 MACsec:有关 MACsec 网络架构、用例和配置示例的更多信息,加密网络流量文章的不同解决方案。
第 33 章 在不同域中使用不同的 DNS 服务器
默认情况下,Red Hat Enterprise Linux(RHEL)会将所有 DNS 请求发送到 /etc/resolv.conf 文件中指定的第一个 DNS 服务器。如果这个服务器没有回复,RHEL 会使用这个文件中的下一个服务器。
在一个 DNS 服务器无法解析所有域的环境中,管理员可将 RHEL 配置为将特定域的 DNS 请求发送到所选 DNS 服务器。例如,您可以配置一个 DNS 服务器来解析对 example.com 的查询和另一个 DNS 服务器来解决 example.net查询。对于所有其他 DNS 请求,RHEL 使用与默认网关连接中配置的 DNS 服务器。
重要
在 RHEL 8 中,红帽提供 systemd-resolved 作为不受支持的技术预览。
33.1. 将特定域的 DNS 请求发送到所选 DNS 服务器
本节配置 systemd-resolved 服务和 NetworkManager,将特定域的 DNS 查询发送到所选 DNS 服务器。
如果您完成本节中的步骤,RHEL 将使用 /etc/resolv.conf 文件中的 systemd-resolved 提供的 DNS 服务。systemd-resolved 服务启动一个 DNS 服务,它侦听端口 53,IP 地址 127.0.0.53。该服务会动态将 DNS 请求路由到 NetworkManager 中指定的对应 DNS 服务器。
注意
127.0.0.53 地址只能从本地系统访问,而无法从网络访问。
先决条件
系统配置了多个网络管理器连接。
在负责解析特定域的 NetworkManager 连接中配置 DNS 服务器和搜索域
例如,如果 VPN 连接中指定的 DNS 服务器应该解析
example.com域的查询,VPN 连接配置集必须具有:- 配置可解析
example.com的 DNS 服务器 - 在
ipv4.dns-search和ipv6.dns-search参数中将搜索域配置为example.com
- 配置可解析
流程
启动并启用
systemd-resolved服务:xxxxxxxxxx# systemctl --now enable systemd-resolved编辑
/etc/NetworkManager/NetworkManager.conf文件,在[main]部分设置以下条目:xxxxxxxxxxdns=systemd-resolved重新载入
NetworkManager服务:xxxxxxxxxx# systemctl reload NetworkManager
验证步骤
验证
nameserver文件中的/etc/resolv.conf条目是否指向127.0.0.53:xxxxxxxxxx# cat /etc/resolv.confnameserver 127.0.0.53验证
systemd-resolved服务是否监听本地 IP 地址127.0.0.53的端口53:xxxxxxxxxx# netstat -tulpn | grep "127.0.0.53:53"tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 1050/systemd-resolvudp 0 0 127.0.0.53:53 0.0.0.0:* 1050/systemd-resolv
其它资源
- 详情请查看
dnsman page 中的NetworkManager.conf(5)参数描述。
第 34 章 开始使用 IPVLAN
本文档描述了 IPVLAN 驱动程序。
34.1. IPVLAN 概述
IPVLAN 是虚拟网络设备的驱动程序,可在容器环境中用于访问主机网络。IPVLAN 将单个 MAC 地址公开给外部网络,无论在主机网络中创建的 IPVLAN 设备数量如何。这意味着,用户可以在多个容器中有多个 IPVLAN 设备,相应的交换机会读取单个 MAC 地址。当本地交换机对其可管理的 MAC 地址总数强制限制时,IPVLAN 驱动程序很有用。
34.2. IPVLAN 模式
IPVLAN 有以下模式可用:
L2 模式
在 IPVLAN L2 模式 中,虚拟设备接收并响应地址解析协议(ARP)请求。
netfilter框架仅在拥有虚拟设备的容器中运行。容器化流量的默认命名空间中没有执行netfilter链。使用L2 模式会提供良好的性能,但对网络流量的控制要小。L3 模式
在 L3 模式 中,虚拟设备只处理 L3 以上的流量。虚拟设备不响应 ARP 请求,用户必须手动为相关点上的 IPVLAN IP 地址配置邻居条目。相关容器的出口流量会放在 default 命名空间的
netfilterPOSTROUTING 和 OUTPUT 链上,而入口流量会进程线程处理,方式与 L2 模式 相同。使用L3 模式会提供很好的控制,但可能会降低网络流量性能。L3S 模式
在 L3S 模式 中,虚拟设备处理方式与 L3 模式 相同,唯一的不同是,相关容器的出口和入站流量都在 default 命名空间的
netfilterchain 上采用。L3S 模式 的行为方式和 L3 模式 相似,但提供了对网络的更大控制。
注意
对于 L3 和 L3S modes,IPVLAN 虚拟设备不能接收广播和多播数据。
34.3. MACVLAN 概述
MACVLAN 驱动程序允许在一个 NIC 上创建多个虚拟网络设备,每个网卡都由其自身唯一的 MAC 地址标识。物理 NIC 上的数据包通过目的地的 MAC 地址与相关的 MACVLAN 设备进行多路复用。MACVLAN 设备不添加任何级别的封装。
34.4. IPVLAN 和 MACVLAN 的比较
下表显示了 MACVLAN 和 IPVLAN 的主要区别。
| MACVLAN | IPVLAN |
|---|---|
| 为每个 MACVLAN 设备使用 MAC 地址。交换中 MAC 表的 MAC 地址限制可能会导致连接丢失。 | 使用不限制 IPVLAN 设备数的单个 MAC 地址。 |
| 全局命名空间的 netfilter 规则不会影响子命名空间中到达或从 MACVLAN 设备的网络流量。 | 有可能在 L3 模式和 L3S 模式中控制到 IPVLAN 设备或者来自 IPVLAN 设备的网络流量。 |
请注意,IPVLAN 和 MACVLAN 不需要任何级别的阻塞。
34.5. 使用 iproute2 创建和配置 IPVLAN 设备
这个步骤演示了如何使用 iproute2 设置 IPVLAN 设备。
流程
要创建 IPVLAN 设备,请输入以下命令:
xxxxxxxxxx~]# ip link add link real_NIC_device name IPVLAN_device type ipvlan mode l2请注意:网络接口控制器(NIC)是将计算机连接到网络的一个硬件组件。
例 34.1. 创建 IPVLAN 设备
xxxxxxxxxx~]# ip link add link enp0s31f6 name my_ipvlan type ipvlan mode l2~]# ip link47: my_ipvlan@enp0s31f6: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether e8:6a:6e:8a:a2:44 brd ff:ff:ff:ff:ff:ff要为接口分配
IPv4或IPv6地址,请输入以下命令:xxxxxxxxxx~]# ip addr add dev IPVLAN_device IP_address/subnet_mask_prefix如果在 L3 模式或 L3S 模式中配置 IPVLAN 设备,请进行以下设置:
在远程主机上为远程 peer 配置邻居设置:
xxxxxxxxxx~]# ip neigh add dev peer_device IPVLAN_device_IP_address lladdr MAC_address其中 MAC_address 是 IPVLAN 设备所基于的实际网卡的 MAC 地址。
使用以下命令为 L3 模式 配置 IPVLAN 设备:
xxxxxxxxxx~]# ip neigh add dev real_NIC_device peer_IP_address lladdr peer_MAC_address对于 L3S 模式:
xxxxxxxxxx~]# ip route dev add real_NIC_device peer_IP_address/32其中 IP-address 代表远程 peer 的地址。
要设置活跃的 IPVLAN 设备,请输入以下命令:
xxxxxxxxxx~]# ip link set dev IPVLAN_device up要检查 IPVLAN 设备是否活跃,请在远程主机中执行以下命令:
xxxxxxxxxx~]# ping IP_address其中 IP_address 使用 IPVLAN 设备的 IP 地址。
第 35 章 配置虚拟路由和转发(VRF)
使用虚拟路由和转发(VRF),管理员可以在同一个主机上同时使用多个路由表。为此,VRF 将网络在第 3 层进行分区。这可让管理员使用每个 VRF 域的独立路由表隔离流量。这个技术与虚拟 LAN(虚拟 LAN)类似,后者在第二层为网络分区,其中操作系统使用不同的 VLAN 标签来隔离共享相同物理介质的流量。
VRF 优于在第二层上分区的好处是,路由会根据涉及的对等者数量进行更好地考虑。
Red Hat Enterprise Linux 为每个 VRF 域使用虚拟 vrt 设备,并通过为 VRF 设备保留现有网络设备添加至 VRF 域的路由。之前附加到 enslaved 设备的地址和路由将在 VRF 域中移动。
请注意,每个 VRF 域间都是相互隔离的。
35.1. 在不同接口上永久重复使用相同的 IP 地址
这个步骤描述了如何使用 VRF 功能在同一服务器的不同接口中永久使用相同的 IP 地址。
重要
要在重新使用相同的 IP 地址时让远程对等两个 VRF 接口都联系,网络接口必须属于不同的广播域。广播域是一组节点,它们接收由它们发送的广播流量。在大多数配置中,所有连接到同一交换机的节点都属于相同的域。
先决条件
- 您以
root用户身份登录。 - 没有配置网络接口。
流程
创建并配置第一个 VRF 设备:
为 VRF 设备创建连接并将其分配到路由表中。例如,要创建一个名为
vrf0的 VRF 设备,它将分配给1001路由表:xxxxxxxxxx# nmcli connection add type vrf ifname vrf0 con-name vrf0 table 1001 ipv4.method disabled ipv6.method disabled启用
vrf0设备:xxxxxxxxxx# nmcli connection up vrf0为刚刚创建的 VRF 分配网络设备。例如:要将
enp1s0以太网设备添加到vrf0VRF 设备,并为enp1s0分配一个 IP 地址和子网掩码:xxxxxxxxxx# nmcli connection add type ethernet con-name vrf.enp1s0 ifname enp1s0 master vrf0 ipv4.method manual ipv4.address 192.0.2.1/24激活
vrf.enp1s0连接:xxxxxxxxxx# nmcli connection up vrf.enp1s0
创建并配置下一个 VRF 设备:
创建 VRF 设备并将其分配到路由表中。例如,要创建一个名为
vrf1的 VRF 设备,它将分配给1002路由表,输入:xxxxxxxxxx# nmcli connection add type vrf ifname vrf1 con-name vrf1 table 1002 ipv4.method disabled ipv6.method disabled激活
vrf1设备:xxxxxxxxxx# nmcli connection up vrf1为刚刚创建的 VRF 分配网络设备。例如:要将
enp7s0以太网设备添加到vrf1VRF 设备,并为enp7s0分配一个 IP 地址和子网掩码:xxxxxxxxxx# nmcli connection add type ethernet con-name vrf.enp7s0 ifname enp7s0 master vrf1 ipv4.method manual ipv4.address 192.0.2.1/24激活
vrf.enp7s0设备:xxxxxxxxxx# nmcli connection up vrf.enp7s0
35.2. 在不同接口中临时重复使用相同的 IP 地址
本节中的步骤论述了如何使用虚拟路由和转发(VRF)功能在某个服务器的不同接口中临时使用相同的 IP 地址。这个过程仅用于测试目的,因为配置是临时的并在重启系统后会丢失。
重要
要在重新使用相同的 IP 地址时让远程对等两个 VRF 接口都联系,网络接口必须属于不同的广播域。广播域是一组节点,它们接收被其中任何一个发送的广播流量。在大多数配置中,所有连接到同一交换机的节点都属于相同的域。
先决条件
- 您以
root用户身份登录。 - 没有配置网络接口。
流程
创建并配置第一个 VRF 设备:
创建 VRF 设备并将其分配到路由表中。例如,要创建一个名为
blue的 VRF 设备,它将分配给1001路由表:xxxxxxxxxx# ip link add dev blue type vrf table 1001启用
blue设备:xxxxxxxxxx# ip link set dev blue up为 VRF 设备分配网络设备。例如:要将
enp1s0以太网设备添加到blueVRF 设备中:xxxxxxxxxx# ip link set dev enp1s0 master blue启用
enp1s0设备:xxxxxxxxxx# ip link set dev enp1s0 up为
enp1s0设备分配 IP 地址和子网掩码。例如,将其设置为192.0.2.1/24:xxxxxxxxxx# ip addr add dev enp1s0 192.0.2.1/24
创建并配置下一个 VRF 设备:
创建 VRF 设备并将其分配到路由表中。例如,要创建一个名为
red的 VRF 设备,它将分配给1002路由表:xxxxxxxxxx# ip link add dev red type vrf table 1002启用
red设备:xxxxxxxxxx# ip link set dev red up为 VRF 设备分配网络设备。例如:要将
enp7s0以太网设备添加到redVRF 设备中:xxxxxxxxxx# ip link set dev enp7s0 master red启用
enp7s0设备:xxxxxxxxxx# ip link set dev enp7s0 up为
enp7s0设备分配与blueVRF 域中的enp1s0使用相同的 IP 地址和子网:xxxxxxxxxx# ip addr add dev enp7s0 192.0.2.1/24
另外,还可按照上述步骤创建更多 VRF 设备。
35.3. 相关信息
第 36 章 为您的系统设置路由协议
这一段讲述了如何使用 自由范围路由 (FRRouting 或者 FRR)来启用和设置系统所需的路由协议。
36.1. FRRouting 介绍
Free Range Routing (FRRouting, FRRouting ,FRRouting)是一个路由协议栈,它由 AppStream 仓库里可用的 frr 软件包提供。
FRR 代替了以前的 RHEL 版本中使用的 Quagga。例如,FRR 提供基于 TCP/IP 的路由服务,并支持多个 IPv4 和 IPv6 路由协议。
支持的协议有:
- 边框网关协议(BGP)
- 中间系统到中间系统(IS-IS)
- Open Shortest Path First(OSPF)
- 独立协议多播(PIM)
- 路由信息协议(RIP)
- 下一代路由信息协议(RIPng)
- 加强的网关路由协议(EIGRP)
- 下一次 Hop 解析协议(NHRP)
- 双向转发检测(BFD)
- 基于策略的路由(PBR)
FRR 是下列服务的集合:
- zebra
- bgpd
- isisd
- ospfd
- ospf6d
- pimd
- ripd
- ripngd
- eigrpd
- nhrpd
- bfdd
- pbrd
- staticd
- fabricd
如果安装了 frr,系统可充当专用路由器,该路由器可使用路由协议与其它路由器在内部或外部网络中交换路由信息。
36.2. 设置 FRRouting
先决条件
- 请确定在您的系统中安装了
frr软件包:
xxxxxxxxxx# yum install frr
流程
编辑
/etc/frr/daemons配置文件,并为您的系统启用所需的守护进程。例如:要启用
ripd守护进程,请包含以下行:xxxxxxxxxxripd=yes警告
zebra守护进程必须总是被启用,所以必须设置zebra=yes来使用 FRR。重要
默认情况下,
/etc/frr/daemons包含所有守护进程的[daemon_name]=no条目。因此,所有守护进程都被禁用,在新的系统安装后启动 FRR 将无效。启动
frr服务:xxxxxxxxxx# systemctl start frr另外,您也可以在引导时自动启动 FRR:
xxxxxxxxxx# systemctl enable frr
36.3. 修改 FRR 的配置
本节描述:
- 设置 FRR后如何启用额外的守护进程
- 设置 FRR后如何禁用守护进程
启用附加守护进程
先决条件
- FRR 设置如 第 36.2 节 “设置 FRRouting” 所述。
流程
启用一个或多个附加守护进程:
编辑
/etc/frr/daemons配置文件,并将所需守护进程的行改为状态为yes,而不是no。例如,要启用
ripd守护进程:xxxxxxxxxxripd=yes重新载入
frr服务:xxxxxxxxxx# systemctl reload frr
禁用守护进程
先决条件
- FRR 设置如 第 36.2 节 “设置 FRRouting” 所述。
流程
禁用一个或多个守护进程:
编辑
/etc/frr/daemons配置文件,并将所需守护进程的行改为状态为no,而不是yes。例如:要禁用
ripd守护进程:xxxxxxxxxxripd=no重新载入
frr服务:xxxxxxxxxx# systemctl reload frr
36.4. 修改特定守护进程的配置
使用默认配置,FRR 里的每个路由守护进程只能充当普通路由器。
要进行守护进程的额外配置,请使用以下步骤。
流程
在
/etc/frr/目录中,为所需守护进程创建一个配置文件,如下:xxxxxxxxxx[daemon_name].conf例如,要进一步配置
eigrpd守护进程,请在上述目录中创建eigrpd.conf文件。使用所需内容填充新文件。
特定的 FRR 守护进程的配置示例请参考
/usr/share/doc/frr/目录。重新载入
frr服务:xxxxxxxxxx# systemctl reload frr
第 37 章 监控并调整 RX 环缓冲
接收(RX)环缓冲是在设备驱动程序和网络接口卡(NIC)间共享缓冲区,并存储传入的数据包,直到设备驱动程序可以处理这些缓冲。
如果数据包丢失率导致应用程序报告,您可以增大以太网设备 RX 环缓冲的大小:
- 数据丢失,
- 集群隔离,
- 性能较慢,
- 超时,以及
- 备份失败。
这部分论述了如何识别丢弃的数据包数量,增加 RX 环缓冲来降低高数据包的降低率。
37.1. 显示丢弃的数据包数量
ethtool 工具可让管理员查询、配置和控制网络驱动程序设置。
RX 环缓冲耗尽会导致计数器增加,如 ethtool -S *interface_name*的输出中 "discard" 或 "drop"。忽略的数据包表示可用缓冲的填充速度比内核处理数据包的速度要快。
这个步骤描述了如何使用 ethtool显示丢弃计数器。
流程
要显示
*enp1s0*接口的丢弃计数器,请输入:xxxxxxxxxx$ ethtool -S enp1s0
37.2. 增加 RX 环缓冲以降低数据包丢弃的比率
ethtool 工具有助于提高 RX 缓冲,以减少数据包的高丢弃率。
流程
查看 RX 环缓冲的最大值:
xxxxxxxxxx# ethtool -g enp1s0Ring parameters for enp1s0:Pre-set maximums:RX: 4080RX Mini: 0RX Jumbo: 16320TX: 255Current hardware settings:RX: 255RX Mini: 0RX Jumbo: 0TX: 255如果
Pre-set maximums部分中的值大于Current hardware settings部分,请提高 RX 环缓冲:要临时将
enp1s0设备的 RX 环缓冲改为4080,请输入:xxxxxxxxxx# ethtool -G enp1s0 rx 4080要永久更改 RX 环缓冲,请创建一个 NetworkManager 分配程序脚本。
详情请参阅 如何使 NIC ethtool 设置永久保留(在引导时自动应用) 并创建一个分配程序脚本。
重要
根据您的网卡使用的驱动,环缓冲的改变会很快中断网络连接。
其它资源
- 有关满足丢弃不需要数据包的原因的统计信息,请参阅 RHEL7 文章 ifconfig 和 ip 命令报告数据包丢弃。
- 我是否应该关注 0.05% 数据包的丢弃率?
ethtool(8)man page。
第 38 章 测试基本网络设置
这部分论述了如何执行基本网络测试。
38.1. 使用 ping 程序验证 IP 到其他主机的连接
ping 实用程序将 ICMP 数据包发送到远程主机。您可以使用此功能来测试 IP 与不同主机的连接是否正常工作。
流程
将主机的 IP 地址放在同一子网中,如您的默认网关:
xxxxxxxxxx# ping 192.0.2.3如果命令失败,请验证默认网关设置。
在远程子网中指定主机的 IP 地址:
xxxxxxxxxx# ping 198.162.3.1如果命令失败,请验证默认网关设置,并确保网关在连接的网络间转发数据包。
38.2. 使用 host 实用程序验证名称解析
这个步骤描述了如何在 Red Hat Enterprise Linux 8 中验证名称解析。
流程
使用
host实用程序验证名称解析是否正常工作。例如:要将client.example.com主机名解析为 IP 地址,请输入:xxxxxxxxxx# host client.example.com如果命令返回错误,如
connection timed out或no servers could be reached,请验证您的 DNS 设置。
第 39 章 网络管理器调试介绍
为所有或某些域增加日志级别有助于记录 NetworkManager 操作的详情。管理员可以使用这些信息排除问题。NetworkManager 提供不同的级别和域来生成日志信息。/etc/NetworkManager/NetworkManager.conf 文件是 NetworkManager 的主要配置文件。日志存储在日志中。
本节提供有关为 NetworkManager 启用调试日志以及使用不同日志级别和域配置日志量的信息。
39.1. 调试级别和域
您可以使用 levels 和 domains 参数来管理 NetworkManager 的调试。这个级别定义了详细程度,而域定义了记录给定的严重性日志的消息类别(level)。
| 日志级别 | 描述 |
|---|---|
OFF | 不记录任何有关 NetworkManager 的信息 |
ERR | 仅记录严重错误 |
WARN | 记录可以反映操作的警告信息 |
INFO | 记录各种有助于跟踪状态和操作的信息 |
DEBUG | 为调试启用详细日志记录 |
TRACE | 启用比 DEBUG 级更详细的日志 |
请注意,后续的级别记录来自以前级别的所有信息。例如,将日志级别设置为 INFO 也会记录 ERR 和 WARN 日志级别中包含的信息。
其它资源
- 有关
domains的详情,请参考NetworkManager.conf(5)man page。
39.2. 设置 NetworkManager 日志级别
默认情况下,所有日志域都被设置为记录 INFO 日志级别。在收集调试日志前禁用速率限制。使用速率限制时,如果短时间内太多,systemd-journald 会丢弃信息。这会在日志级别为 TRACE 时发生。
此流程禁用速率限制,并为所有(ALL)域启用记录调试日志。
流程
要禁用速率限制,请编辑
/etc/systemd/journald.conf文件,取消[Journal]部分中的RateLimitBurst参数的注释,并将它的值设置为0:xxxxxxxxxxRateLimitBurst=0重启
systemd-journald服务。xxxxxxxxxx# systemctl restart systemd-journald使用以下内容创建
/etc/NetworkManager/conf.d/95-nm-debug.conf文件:xxxxxxxxxx[logging]domains=ALL:DEBUGdomains参数可以包含多个用逗号分开的domain:level对。重启 NetworkManager 服务。
xxxxxxxxxx# systemctl restart NetworkManager
39.3. 在运行时使用 nmcli 临时设置日志级别
您可以使用 nmcli在运行时更改日志级别。但是,红帽建议使用配置文件启用调试并重启 NetworkManager。使用 .conf 文件更新调试 levels 和 domains 可以帮助调试引导问题并捕获初始状态的所有日志。
流程
可选:显示当前的日志设置:
xxxxxxxxxx# nmcli general loggingLEVEL DOMAINSINFO PLATFORM,RFKILL,ETHER,WIFI,BT,MB,DHCP4,DHCP6,PPP,WIFI_SCAN,IP4,IP6,AUTOIP4,DNS,VPN,SHARING,SUPPLICANT,AGENTS,SETTINGS,SUSPEND,CORE,DEVICE,OLPC,WIMAX,INFINIBAND,FIREWALL,ADSL,BOND,VLAN,BRIDGE,DBUS_PROPS,TEAM,CONCHECK,DCB,DISPATCH要修改日志级别和域,请使用以下选项:
要将所有域的日志级别设定为相同的
LEVEL,请输入:xxxxxxxxxx# nmcli general logging level LEVEL domains ALL要更改特定域的级别,请输入:
xxxxxxxxxx# nmcli general logging level LEVEL domains DOMAINS请注意,使用这个命令更新日志级别会禁用所有其他域的日志功能。
要更改特定域的级别并保持其它域的级别,请输入:
xxxxxxxxxx# nmcli general logging level KEEP domains DOMAIN:LEVEL,DOMAIN:LEVEL
39.4. 查看 NetworkManager 日志
您可以查看 NetworkManager 日志进行故障排除。
流程
要查看日志,请输入:
xxxxxxxxxx# journalctl -u NetworkManager -b
其它资源
NetworkManager.conf(5)man pagejournalctlman page
第 40 章 捕获网络数据包
要调试网络问题和通讯,您可以捕获网络数据包。以下部分提供有关捕获网络数据包的步骤和附加信息。
40.1. 使用 xdpdump 捕获包括 XDP 程序丢弃的数据包在内的网络数据包
xdpdump 工具捕获网络数据包。与 tcpdump 实用程序不同,xdpdump 为这个任务使用扩展的 Berkeley Packet Filter(eBPF)程序。这可让 xdpdump 同时捕获由 Express Data Path(XDP)程序丢弃的数据包。用户空间工具(如 tcpdump)无法捕获这些被丢弃的软件包,以及 XDP 程序修改的原始数据包。
您可以使用 xdpdump 来调试已经附加到接口中的 XDP 程序。因此,实用程序可以在 XDP 程序启动和完成后捕获数据包。在后者的情况下,xdpdump 也捕获了 XDP 操作。默认情况下,xdpdump 会在 XDP 程序条目中捕获传入的数据包。
重要
红帽提供了 xdpdump 作为不受支持的技术预览。
请注意,xdpdump 没有数据包过滤或解码功能。但是您可以将它与 tcpdump 结合使用来解码数据包。
这个步骤描述了如何捕获 enp1s0 接口中的所有数据包并将其写入 /root/capture.pcap 文件中。
先决条件
- 支持 XDP 程序的网络驱动程序。
- XDP 程序被加载到
enp1s0接口。如果没有载入程序,xdpdump会以类似tcpdump的方式捕获数据包,以向后兼容。
流程
要捕获
enp1s0接口上的数据包并将其写入/root/capture.pcap文件,请输入:xxxxxxxxxx# xdpdump -i enp1s0 -w /root/capture.pcap要停止捕获数据包,请按 Ctrl+C。
其它资源
- 有关
xdpdump的详情,请查看xdpdump(8)man page。 - 如果您是开发人员,并且您对
xdpdump的源代码有兴趣,请从红帽客户门户网站下载并安装相应的源 RPM(SRPM)。
40.2. 其它资源
- 如何使用 tcpdump 捕获网络数据包? 知识库解决方案。
第 41 章 在 RHEL 中使用特定内核版本
内核是 Linux 操作系统的一个核心组件,可管理系统资源,并提供硬件和软件应用程序间的接口。在某些情况下,内核可能会影响网络功能,因此建议您使用内核的最新版本。如果需要,也可以将内核版本降级到同一 x-stream 内核的早期版本,并在系统引导时选择特定版本进行故障排除。
这部分解释了当您升级或降级内核时,如何在 GRUB 引导装载程序中选择内核。
41.1. 使用以前的内核版本启动 RHEL
默认情况下,在更新后,系统会引导内核的最新版本。Red Hat Enterprise Linux 允许同时安装三个内核版本。这在 /etc/dnf/dnf.conf 文件(installonly_limit=3)中定义。
如果您在使用新内核载入系统时看到任何问题,您可以使用之前的内核重启并恢复产品机器。联系支持人员对此问题进行故障排除。
流程
- 启动系统。
- 在 GRUB 引导装载程序中,您会看到所安装的内核。使用 ↑ 和 ↓ 键选择一个内核,按 Enter 引导它。
其它资源
- 将默认内核改为使用
grubby工具引导。 - 有关安装和更新内核的详情,请参考使用 yum 更新内核。
第 42 章 提供 DHCP 服务
动态主机配置协议(DHCP)是自动为客户端分配 IP 信息的网络协议。
这部分解释了 dhcpd 服务的一般信息,以及如何设置 DHCP 服务器和 DHCP 转发。
如果 IPv4 和 IPv6 网络的步骤有所不同,本章会包含这两个协议的步骤。
42.1. 对 DHCPv4 和 DHCPv6 使用 dhcpd 时的不同
dhcpd 服务支持在一个服务器中提供 DHCPv4 和 DHCPv6。然而,您需要单独的 dhcpd 实例以及单独的配置文件来为每个协议提供 DHCP。
DHCPv4
配置文件:
/etc/dhcp/dhcpd.confsystemd 服务名称:dhcpdDHCPv6
配置文件:
/etc/dhcp/dhcpd6.confsystemd 服务名称:dhcpd6
42.2. dhcpd 服务的租期数据库
DHCP 租期是 dhcpd 服务为客户端分配网络地址的时间周期。dhcpd 服务将 DHCP 租期存储在以下数据库中:
- 对于 DHCPv4:
/var/lib/dhcpd/dhcpd.leases - 对于 DHCPv6:
/var/lib/dhcpd/dhcpd6.leases
警告
手动更新数据库文件可能会破坏数据库。
租期数据库包含有关分配的租期的信息,如分配给 MAC 地址的 IP 地址或租期到期的时间戳。请注意,租期数据库中的所有时间戳都是 UTC。
dhcpd 服务定期重新创建数据库:
该服务重命名现存文件:
/var/lib/dhcpd/dhcpd.leases至/var/lib/dhcpd/dhcpd.leases~/var/lib/dhcpd/dhcpd6.leases至/var/lib/dhcpd/dhcpd6.leases~
该服务将所有已知的租期写入新创建的
/var/lib/dhcpd/dhcpd.leases和/var/lib/dhcpd/dhcpd6.leases文件。
其它资源
- 有关在租期数据库中保存内容的详情,请查看
dhcpd.leases(5)man page。 - 第 42.10 节 “恢复损坏的租期数据库”
42.3. DHCPv6 和 radvd 的比较
在 IPv6 网络中,只有路由器广告信息在 IPv6 默认网关上提供信息。因此,如果您要在需要默认网关设置的子网中使用 DHCPv6,还必须配置路由器广告服务,如 Router Advertisement Daemon(radvd)。
radvd 服务使用路由器广告数据包中的标记声明 DHCPv6 服务器可用。
本节比较 DHCPv6 和 radvd,并提供了有关配置 radvd 的信息。
| DHCPv6 | radvd | |
|---|---|---|
| 提供默认网关的信息 | 否 | 是 |
| 保证随机地址以保护隐私 | 是 | 否 |
| 发送更多网络配置选项 | 是 | 否 |
| 将 MAC 地址映射到 IPv6 地址 | 是 | 否 |
42.4. 为 IPv6 路由器配置 radvd 服务
路由器广告守护进程(radvd)发送路由器公告信息,这是 IPv6 无状态自动配置所需的。这可让用户根据这些公告自动配置其地址、设置、路由和选择默认路由器。
本节中的步骤解释了如何配置 radvd。
先决条件
- 您以
root用户身份登录。
流程
安装
radvd软件包:xxxxxxxxxx# yum install radvd编辑
/etc/radvd.conf文件并添加以下配置:xxxxxxxxxxinterface enp1s0{AdvSendAdvert on;AdvManagedFlag on;AdvOtherConfigFlag on;prefix 2001:db8:0:1::/64 {};};这些设置将
radvd配置为为2001:db8:0:1::/64子网在enp1s0设备上发送路由器公告信息。AdvManagedFlag on设置定义客户端应该从 DHCP 服务器接收 IP 地址,把AdvOtherConfigFlag参数设置为on定义客户端也应该从 DHCP 服务器接收非地址信息。(可选)配置
radvd会在系统引导时自动启动:xxxxxxxxxx# systemctl enable radvd启动
radvd服务:xxxxxxxxxx# systemctl start radvd另外,还可以显示路由器广告软件包的内容和配置的值
radvd发送:xxxxxxxxxx# radvdump
其它资源
- 有关配置
radvd的详情,请查看radvd.conf(5)man page。 - 如需
radvd的示例配置,请参阅/usr/share/doc/radvd/radvd.conf.example文件。
42.5. 为 DHCP 服务器设置网络接口
默认情况下,dhcpd 服务仅在在服务的配置文件里定义的子网中有 IP 地址的网络接口中处理请求。
例如,在以下场景中,dhcpd 只侦听 enp0s1 网络接口:
- 在
/etc/dhcp/dhcpd.conf文件中,只有 192.0.2.0/24 网络的subnet定义。 enp0s1网络接口连接到 192.0.2.0/24 子网。enp7s0接口连接到不同的子网。
如果 DHCP 服务器包含多个网络接口,但该服务应该只侦听特定的接口,请只按照本小节中的步骤操作。
根据您要为 IPv4、IPv6 或两个协议提供 DHCP 的信息,请查看以下操作过程:
先决条件
- 您以
root用户身份登录。 - 已安装
dhcp-server软件包。
流程
对于 IPv4 网络:
将
/usr/lib/systemd/system/dhcpd.service文件复制到/etc/systemd/system/目录中:xxxxxxxxxx# cp /usr/lib/systemd/system/dhcpd.service /etc/systemd/system/不要编辑
/usr/lib/systemd/system/dhcpd.service文件。dhcp-server软件包将来的更新可能会覆盖这些更改。编辑
/etc/systemd/system/dhcpd.service文件,并附加接口的名称,dhcpd应该侦听到ExecStart参数中的命令中:xxxxxxxxxxExecStart=/usr/sbin/dhcpd -f -cf /etc/dhcp/dhcpd.conf -user dhcpd -group dhcpd --no-pid $DHCPDARGS enp0s1 enp7s0这个示例配置
dhcpd只侦听*enp0s1*和enp7s0接口。重新载入
systemd管理器配置:xxxxxxxxxx# systemctl daemon-reload重启
dhcpd服务:xxxxxxxxxx# systemctl restart dhcpd.service
对于 IPv6 网络:
将
/usr/lib/systemd/system/dhcpd6.service文件复制到/etc/systemd/system/目录中:xxxxxxxxxx# cp /usr/lib/systemd/system/dhcpd6.service /etc/systemd/system/不要编辑
/usr/lib/systemd/system/dhcpd6.service文件。dhcp-server软件包将来的更新可能会覆盖这些更改。编辑
/etc/systemd/system/dhcpd6.service文件,并附加接口的名称,dhcpd应该侦听到ExecStart参数中的命令中:xxxxxxxxxxExecStart=/usr/sbin/dhcpd -f -6 -cf /etc/dhcp/dhcpd6.conf -user dhcpd -group dhcpd --no-pid $DHCPDARGS enp0s1 enp7s0这个示例配置
dhcpd只侦听*enp0s1*和enp7s0接口。重新载入
systemd管理器配置:xxxxxxxxxx# systemctl daemon-reload重启
dhcpd6服务:xxxxxxxxxx# systemctl restart dhcpd6.service
42.6. 为直接连接到 DHCP 服务器的子网设置 DHCP 服务
如果 DHCP 服务器直接连接到该服务器应响应 DHCP 请求的子网,请使用以下步骤。如果服务器的网络接口有这个子网的 IP 地址,那么就会出现这种情况。
根据您要为 IPv4、IPv6 或两个协议提供 DHCP 的信息,请查看以下操作过程:
先决条件
- 您以
root用户身份登录。 - 已安装
dhcpd-server软件包。
流程
对于 IPv4 网络:
编辑
/etc/dhcp/dhcpd.conf文件:另外,如果其它指令没有包含这些设置,请添加
dhcpd作为默认设置的全局参数:xxxxxxxxxxoption domain-name "example.com";default-lease-time 86400;这个示例为连接
example.com设置默认域名,默认租期时间为86400秒(1 天)。在新行中添加
authoritative声明:xxxxxxxxxxauthoritative;重要
在没有
authoritative声明的情况下,如果客户端请求池外的地址,dhcpd服务不会在DHCPNAK信息中回答DHCPREQUEST信息。为每个直接连接到服务器接口的 IPv4 子网添加
subnet声明:xxxxxxxxxxsubnet 192.0.2.0 netmask 255.255.255.0 {range 192.0.2.20 192.0.2.100;option domain-name-servers 192.0.2.1;option routers 192.0.2.1;option broadcast-address 192.0.2.255;max-lease-time 172800;}这个示例为 192.0.2.0/24 网络添加了 subnet 声明。使用这个配置,DHCP 服务器会为发送这个子网的 DHCP 请求的客户端分配下列设置:
range参数中定义的范围内的可用 IPv4 地址- 此子网的 DNS 服务器的 IP:
192.0.2.1 - 这个子网的默认网关:
192.0.2.1 - 这个子网的广播地址:
192.0.2.255 - 此子网中的客户端发布 IP 并向服务器发送新请求:
172800秒(2 天)
另外,还可在系统引导时配置
dhcpd自动启动:xxxxxxxxxx# systemctl enable dhcpd启动
dhcpd服务:xxxxxxxxxx# systemctl start dhcpd
对于 IPv6 网络:
编辑
/etc/dhcp/dhcpd6.conf文件:另外,如果其它指令没有包含这些设置,请添加
dhcpd作为默认设置的全局参数:xxxxxxxxxxoption dhcp6.domain-search "example.com";default-lease-time 86400;这个示例为连接
example.com设置默认域名,默认租期时间为86400秒(1 天)。在新行中添加
authoritative声明:xxxxxxxxxxauthoritative;重要
在没有
authoritative声明的情况下,如果客户端请求池外的地址,dhcpd服务不会在DHCPNAK信息中回答DHCPREQUEST信息。为每个直接连接到服务器接口的 IPv6 子网添加
subnet声明:xxxxxxxxxxsubnet6 2001:db8:0:1::/64 {range6 2001:db8:0:1::20 2001:db8:0:1::100;option dhcp6.name-servers 2001:db8:0:1::1;max-lease-time 172800;}本例为 2001:db8:0:1::/64 网络添加了 subnet 声明。使用这个配置,DHCP 服务器会为发送这个子网的 DHCP 请求的客户端分配下列设置:
range6参数中定义的范围内的可用 IPv6 地址这个子网的 DNS 服务器的 IP 地址为
2001:db8:0:1::1。最长租期时间,在这个子网中的客户端发布 IP 并向服务器发送一个新的请求为
172800秒(2 天)。请注意: IPv6 需要使用路由器广告信息来识别默认网关。
另外,还可在系统引导时配置
dhcpd6自动启动:xxxxxxxxxx# systemctl enable dhcpd6启动
dhcpd6服务:xxxxxxxxxx# systemctl start dhcpd6
其它资源
- 有关您可以在
/etc/dhcp/dhcpd.conf和/etc/dhcp/dhcpd6.conf中设置的所有参数列表,请查看dhcp-options(5)man page。 - 有关
authoritative声明的详情,请查看dhcpd.conf(5)man page 中的The authoritative statement部分。 - 有关配置示例,请查看
/usr/share/doc/dhcp-server/dhcpd.conf.example和/usr/share/doc/dhcp-server/dhcpd6.conf.example文件。
42.7. 为没有直接连接到 DHCP 服务器的子网设置 DHCP 服务
如果 DHCP 服务器没有直接连接到该服务器应响应 DHCP 请求的子网,请使用以下步骤。如果 DHCP 转发代理将请求转发到 DHCP 服务器,所以这里的 DHCP 服务器接口都不会直接连接到服务器服务的子网。
根据您要为 IPv4、IPv6 或两个协议提供 DHCP 的信息,请查看以下操作过程:
先决条件
- 您以
root用户身份登录。 - 已安装
dhcpd-server软件包。
流程
对于 IPv4 网络:
编辑
/etc/dhcp/dhcpd.conf文件:另外,如果其它指令没有包含这些设置,请添加
dhcpd作为默认设置的全局参数:xxxxxxxxxxoption domain-name "example.com";default-lease-time 86400;这个示例为连接
example.com设置默认域名,默认租期时间为86400秒(1 天)。在新行中添加
authoritative声明:xxxxxxxxxxauthoritative;重要
在没有
authoritative声明的情况下,如果客户端请求池外的地址,dhcpd服务不会在DHCPNAK信息中回答DHCPREQUEST信息。为没有直接连接到服务器接口的 IPv4 子网添加
shared-network声明,比如以下:xxxxxxxxxxshared-network example {option domain-name-servers 192.0.2.1;...subnet 192.0.2.0 netmask 255.255.255.0 {range 192.0.2.20 192.0.2.100;option routers 192.0.2.1;}subnet 198.51.100.0 netmask 255.255.255.0 {range 198.51.100.20 198.51.100.100;option routers 198.51.100.1;}...}这个示例添加了一个共享网络声明,其中包含 192.0.2.0/24 和 198.51.100.0/24 网络的
subnet声明。使用这个配置,DHCP 服务器会为发送来自这些子网之一 DHCP 请求的客户端分配下列设置:- 两个子网的客户端的 DNS 服务器的 IP 是:
192.0.2.1。 range参数中定义的空闲的 IPv4 地址,具体要看客户端从哪个子网发送请求。- 默认网关根据客户端发送请求的子网是
192.0.2.1或者198.51.100.1。
- 两个子网的客户端的 DNS 服务器的 IP 是:
为服务器直接连接到的子网添加
subnet声明,用于访问上面shared-network中指定的远程子网:xxxxxxxxxxsubnet 203.0.113.0 netmask 255.255.255.0 {}注意
如果服务器不向这个子网提供 DHCP 服务,则
subnet声明必须为空,如示例所示。没有直接连接的子网声明,dhcpd就无法启动。
另外,还可在系统引导时配置
dhcpd自动启动:xxxxxxxxxx# systemctl enable dhcpd启动
dhcpd服务:xxxxxxxxxx# systemctl start dhcpd
对于 IPv6 网络:
编辑
/etc/dhcp/dhcpd6.conf文件:另外,如果其它指令没有包含这些设置,请添加
dhcpd作为默认设置的全局参数:xxxxxxxxxxoption dhcp6.domain-search "example.com";default-lease-time 86400;这个示例为连接
example.com设置默认域名,默认租期时间为86400秒(1 天)。在新行中添加
authoritative声明:xxxxxxxxxxauthoritative;重要
在没有
authoritative声明的情况下,如果客户端请求池外的地址,dhcpd服务不会在DHCPNAK信息中回答DHCPREQUEST信息。为没有直接连接到服务器接口的 IPv6 子网添加
shared-network声明,比如以下:xxxxxxxxxxshared-network example {option domain-name-servers 2001:db8:0:1::1:1...subnet6 2001:db8:0:1::1:0/120 {range6 2001:db8:0:1::1:20 2001:db8:0:1::1:100}subnet6 2001:db8:0:1::2:0/120 {range6 2001:db8:0:1::2:20 2001:db8:0:1::2:100}...}这个示例添加了一个共享网络声明,它包含 2001:db8:0:1::1:0/120 和 2001:db8:0:1::2:0/120 网络所需的
subnet6声明。使用这个配置,DHCP 服务器会为发送来自这些子网之一 DHCP 请求的客户端分配下列设置:两个子网的客户端的 DNS 服务器的 IP 是
2001:db8:0:1::1:1。range6参数中定义的空闲的 IPv6 地址,具体要看客户端从哪个子网发送请求。请注意: IPv6 需要使用路由器广告信息来识别默认网关。
为服务器直接连接到的子网添加
subnet6声明,用于访问上面shared-network中指定的远程子网:xxxxxxxxxxsubnet6 2001:db8:0:1::50:0/120 {}注意
如果服务器不向这个子网提供 DHCP 服务,则
subnet6声明必须为空,如示例所示。没有直接连接的子网声明,dhcpd就无法启动。
另外,还可在系统引导时配置
dhcpd6自动启动:xxxxxxxxxx# systemctl enable dhcpd6启动
dhcpd6服务:xxxxxxxxxx# systemctl start dhcpd6
其它资源
- 有关您可以在
/etc/dhcp/dhcpd.conf和/etc/dhcp/dhcpd6.conf中设置的所有参数列表,请查看dhcp-options(5)man page。 - 有关
authoritative声明的详情,请查看dhcpd.conf(5)man page 中的The authoritative statement部分。 - 有关配置示例,请查看
/usr/share/doc/dhcp-server/dhcpd.conf.example和/usr/share/doc/dhcp-server/dhcpd6.conf.example文件。 - 第 42.11 节 “设置 DHCP 转发代理”
42.8. 使用 DHCP 为主机分配静态地址
使用 host 声明,您可以配置 DHCP 服务器为主机的 MAC 地址分配固定的 IP 地址。例如:使用这个方法总是为服务器或者网络设备分配相同的 IP 地址。
重要
如果您为 MAC 地址配置固定 IP 地址,IP 地址必须是您在 fixed-address 和 fixed-address6 参数中指定的地址池之外。
根据您要为 IPv4、IPv6 或这两个协议配置固定地址,请查看以下操作过程:
先决条件
dhcpd服务已被配置并正在运行。- 您以
root用户身份登录。
流程
对于 IPv4 网络:
编辑
/etc/dhcp/dhcpd.conf文件:添加
host声明:xxxxxxxxxxhost server.example.com {hardware ethernet 52:54:00:72:2f:6e;fixed-address 192.0.2.130;}这个示例将 DHCP 服务器配置为,总是为 MAC 地址为
52:54:00:72:2f:6e的主机分配192.0.2.130IP 地址。dhcpd服务根据fixed-address参数中指定的 MAC 地址来识别系统,而不是host声明中的名称。因此,您可以将此名称设置为不匹配其他host声明的字符串。要为多个网络配置相同的系统,请使用不同的名称,否则dhcpd无法启动。另外,还可在针对此主机的
host声明中添加其他设置。
重启
dhcpd服务:xxxxxxxxxx# systemctl start dhcpd
对于 IPv6 网络:
编辑
/etc/dhcp/dhcpd6.conf文件:添加
host声明:xxxxxxxxxxhost server.example.com {hardware ethernet 52:54:00:72:2f:6e;fixed-address6 2001:db8:0:1::200;}这个示例将 DHCP 服务器配置为,总是为 MAC 地址为
52:54:00:72:2f:6e的主机分配2001:db8:0:1::20IP 地址。dhcpd服务根据fixed-address6参数中指定的 MAC 地址来识别系统,而不是host声明中的名称。因此,只要它只用于其他host声明,就可以将此名称设置为任意字符串。要为多个网络配置相同的系统,请使用不同的名称。否则dhcpd将无法启动。另外,还可在针对此主机的
host声明中添加其他设置。
重启
dhcpd6服务:xxxxxxxxxx# systemctl start dhcpd6
其它资源
- 有关您可以在
/etc/dhcp/dhcpd.conf和/etc/dhcp/dhcpd6.conf中设置的所有参数列表,请查看dhcp-options(5)man page。 - 有关配置示例,请查看
/usr/share/doc/dhcp-server/dhcpd.conf.example和/usr/share/doc/dhcp-server/dhcpd6.conf.example文件。
42.9. 使用 group 声明同时将参数应用到多个主机、子网和共享网络
使用 group 声明,您可以对多个主机、子网和共享网络应用相同的参数。
请注意,本节中的步骤描述了为主机使用 group 声明,但步骤与子网和共享网络相同。
根据您要为 IPv4、IPv6 或两个协议配置组,请查看以下操作过程:
先决条件
dhcpd服务已被配置并正在运行。- 您以
root用户身份登录。
流程
对于 IPv4 网络:
编辑
/etc/dhcp/dhcpd.conf文件:添加
group声明:xxxxxxxxxxgroup {option domain-name-servers 192.0.2.1;host server1.example.com {hardware ethernet 52:54:00:72:2f:6e;fixed-address 192.0.2.130;}host server2.example.com {hardware ethernet 52:54:00:1b:f3:cf;fixed-address 192.0.2.140;}}这个
group定义为两个host条目分组。dhcpd服务将option domain-name-servers参数中设置的值应用到组中的两个主机。另外,还可在这些主机的
group声明中添加其他设置。
重启
dhcpd服务:xxxxxxxxxx# systemctl start dhcpd
对于 IPv6 网络:
编辑
/etc/dhcp/dhcpd6.conf文件:添加
group声明:xxxxxxxxxxgroup {option dhcp6.domain-search "example.com";host server1.example.com {hardware ethernet 52:54:00:72:2f:6e;fixed-address 2001:db8:0:1::200;}host server2.example.com {hardware ethernet 52:54:00:1b:f3:cf;fixed-address 2001:db8:0:1::ba3;}}这个
group定义为两个host条目分组。dhcpd服务将option dhcp6.domain-search参数中设置的值应用到组中的两个主机。另外,还可在这些主机的
group声明中添加其他设置。
重启
dhcpd6服务:xxxxxxxxxx# systemctl start dhcpd6
其它资源
- 有关您可以在
/etc/dhcp/dhcpd.conf和/etc/dhcp/dhcpd6.conf中设置的所有参数列表,请查看dhcp-options(5)man page。 - 有关配置示例,请查看
/usr/share/doc/dhcp-server/dhcpd.conf.example和/usr/share/doc/dhcp-server/dhcpd6.conf.example文件。
42.10. 恢复损坏的租期数据库
如果 DHCP 服务器记录了一个与租期数据库相关的错误,如 Corrupt lease file - possible data loss!,您可以从创建的 dhcpd 服务中恢复租期数据库。请注意,这个副本可能没有反映数据库的最新状态。
警告
如果您删除了租期数据库而不是用备份替换它,则丢失了当前分配的租期的所有信息。因此,DHCP 服务器可以为之前分配给其它主机但还没有过期的客户端分配租期。这会导致 IP 冲突。
根据您要恢复 DHCPv4、DHCPv6 还是两个数据库,请查看:
先决条件
- 您以
root用户身份登录。 - 租期数据库被损坏。
流程
恢复 DHCPv4 租期数据库:
停止
dhcpd服务:xxxxxxxxxx# systemctl stop dhcpd重命名损坏租期数据库:
xxxxxxxxxx# mv /var/lib/dhcpd/dhcpd.leases /var/lib/dhcpd/dhcpd.leases.corrupt恢复
dhcp服务在刷新租期数据库时创建的租期数据库副本:xxxxxxxxxx# cp -p /var/lib/dhcpd/dhcpd.leases~ /var/lib/dhcpd/dhcpd.leases重要
如果您有租期数据库的最新备份,则恢复这个备份。
启动
dhcpd服务:xxxxxxxxxx# systemctl start dhcpd
恢复 DHCPv6 租期数据库:
停止
dhcpd6服务:xxxxxxxxxx# systemctl stop dhcpd6重命名损坏租期数据库:
xxxxxxxxxx# mv /var/lib/dhcpd/dhcpd6.leases /var/lib/dhcpd/dhcpd6.leases.corrupt恢复
dhcp服务在刷新租期数据库时创建的租期数据库副本:xxxxxxxxxx# cp -p /var/lib/dhcpd/dhcpd6.leases~ /var/lib/dhcpd/dhcpd6.leases重要
如果您有租期数据库的最新备份,则恢复这个备份。
启动
dhcpd6服务:xxxxxxxxxx# systemctl start dhcpd6
其它资源
42.11. 设置 DHCP 转发代理
DHCP 转发代理(dhcrelay)启用了从没有 DHCP 服务器的子网转发 DHCP 和 BOOTP 请求到其它子网的一个或多个 DHCP 服务器。当 DHCP 客户端请求信息时,DHCP 转发代理会将该请求转发到指定的 DHCP 服务器列表。当 DHCP 服务器返回一个回复时,DHCP 转发代理会将此请求转发给客户端。
根据您要为 IPv4、IPv6 或两个协议设置 DHCP 转发,请查看以下操作过程:
先决条件
- 您以
root用户身份登录。
流程
对于 IPv4 网络:
安装
dhcp-relay软件包:xxxxxxxxxx# yum install dhcp-relay将
/lib/systemd/system/dhcrelay.service文件复制到/etc/systemd/system/目录中:xxxxxxxxxx# cp /lib/systemd/system/dhcrelay.service /etc/systemd/system/不要编辑
/usr/lib/systemd/system/dhcrelay.service文件。dhcp-relay软件包将来的更新可能会覆盖这些更改。编辑
/etc/systemd/system/dhcrelay.service文件,并附加-i *interface*参数以及负责该子网的 DHCPv4 服务器的 IP 地址列表:xxxxxxxxxxExecStart=/usr/sbin/dhcrelay -d --no-pid -i enp1s0 192.0.2.1使用这些附加参数,
dhcrelay侦听enp1s0接口上的 DHCPv4 请求,并使用 IP192.0.2.1将它们转发到 DHCP 服务器。重新载入
systemd管理器配置:xxxxxxxxxx# systemctl daemon-reload另外,还可配置在系统引导时启动
dhcrelay服务:xxxxxxxxxx# systemctl enable dhcrelay.service启动
dhcrelay服务:xxxxxxxxxx# systemctl start dhcrelay.service
对于 IPv6 网络:
安装
dhcp-relay软件包:xxxxxxxxxx# yum install dhcp-relay将
/lib/systemd/system/dhcrelay.service文件复制到/etc/systemd/system/目录中并命名为dhcrelay6.service:xxxxxxxxxx# cp /lib/systemd/system/dhcrelay.service /etc/systemd/system/dhcrelay6.service不要编辑
/usr/lib/systemd/system/dhcrelay.service文件。dhcp-relay软件包将来的更新可能会覆盖这些更改。编辑
/etc/systemd/system/dhcrelay6.service文件,并附加-l *receiving_interface*和-u *outgoing_interface*参数:xxxxxxxxxxExecStart=/usr/sbin/dhcrelay -d --no-pid -l enp1s0 -u enp7s0使用这些额外参数,
dhcrelay侦听enp1s0接口上的 DHCPv6 请求并将其转发到连接到enp7s0接口的网络。重新载入
systemd管理器配置:xxxxxxxxxx# systemctl daemon-reload另外,还可配置在系统引导时启动
dhcrelay6服务:xxxxxxxxxx# systemctl enable dhcrelay6.service启动
dhcrelay6服务:xxxxxxxxxx# systemctl start dhcrelay6.service
其它资源
- 有关
dhcrelay的详情,请查看dhcrelay(8)man page。
其它资源
第 43 章 使用和配置 firewalld
防火墙是保护机器不受来自外部的、不需要的网络数据的一种方式。它允许用户通过定义一组防火墙规则 来控制主机上的入站网络流量。这些规则用于对进入的流量进行排序,并可以阻断或允许流量。
请注意,带有 nftables 后端的 firewalld 不支持使用 --direct 选项将自定义 nftables 规则传递给 firewalld。
43.1. 使用 firewalld、nftables 或者 iptables 时
以下是您应该使用以下工具之一的概述:
firewalld:使用firewalld实用程序在工作站中配置防火墙。该工具可轻松使用,并涵盖本情境的典型用例。nftables:使用nftables程序设置复杂的防火墙,比如为整个网络设置。iptables:Red Hat Enterprise Linux 8 中的iptables工具程序使用nf_tables内核 API 而不是legacy后端。nf_tablesAPI 提供向后兼容性,使用iptables命令的脚本仍然可用于 Red Hat Enterprise Linux 8。对于新的防火墙脚本,红帽建议使用nftables。
重要
要避免不同的防火墙服务相互影响,在 RHEL 主机中只有一个服务,并禁用其他服务。
43.2. 开始使用 firewalld
43.2.1. firewalld
firewalld 是一个防火墙服务守护进程,它为使用 D-Bus 接口提供动态可定制主机防火墙的防火墙服务守护进程。如果是动态的,它可在每次修改规则时启用、修改和删除规则,而不需要在每次修改规则时重启防火墙守护进程。
firewalld 使用 区(zone) 和 服务(service) 的概念来简化流量管理。zones 是预定义的规则集。网络接口和源可以分配给区。允许的流量取决于您计算机连接到的网络,并分配了这个网络的安全级别。防火墙服务是预定义的规则,覆盖了允许特定服务进入流量的所有必要设置,并在区中应用。
服务使用一个或多个 端口 或 地址 进行网络通信。防火墙会根据端口过滤通讯。要允许服务的网络流量,必须 打开 其端口。firewalld 阻断未明确设置为打开的端口上的所有流量。一些区(如 可信区(trusted) )默认允许所有流量。
其它资源
firewalld(1)man page
43.2.2. Zones
firewalld 可以根据用户决定放置在该网络中的接口和流量的信任级别将网络分成不同的区域。一个连接只能是一个区的一部分,但一个区可以被用来进行很多网络连接。
NetworkManager 通知一个接口区的 firewalld。您可以为接口分配区:
NetworkManagerfirewall-config工具firewall-cmd命令行工具- RHEL web 控制台
后三个只能编辑正确的 NetworkManager 配置文件。如果您使用 web 控制台 firewall-cmd 或 firewall-config 更改接口区域,则请求会转发到 NetworkManager 且不由 firewalld 处理。
预定义区域存储在 /usr/lib/firewalld/zones/ 目录中,并可立即应用于任意可用的网络接口。只有在修改后,这些文件才会复制到 /etc/firewalld/zones/ 目录中。预定义区的默认设置如下:
block任何带有 icmp-host-prohibited (
IPv4)或 icmp6-adm-prohibited(IPv6)的入站网络连接都会被拒绝。只有从系统启动的网络连接才能进行。dmz对于您的非企业化区里的计算机来说,这些计算机可以被公开访问,且有限访问您的内部网络。只接受所选的入站连接。
drop所有传入的网络数据包都会丢失,没有任何通知。只有外发网络连接也是可行的。
external适用于启用了伪装的外部网络,特别是路由器。您不信任网络中的其他计算机不会损害您的计算机。只接受所选的入站连接。
home当您主要信任网络中的其他计算机时在本地使用。只接受所选的入站连接。
internal当您主要信任网络中的其他计算机时,供内部网络使用。只接受所选的入站连接。
public可用于您不信任网络中其他计算机的公共区域。只接受所选的入站连接。
trusted所有网络连接都被接受。
work可用于您主要信任网络中其他计算机的工作。只接受所选的入站连接。
这些区中的一个被设置为 default 区。当接口连接添加到 NetworkManager 时,它们会被分配给默认区。安装时,firewalld 的默认区设置为 public 区。默认区可以被修改。
注意
网络区名称应该自我解释,并允许用户迅速做出合理的决定。要避免安全问题,请查看默认区配置并根据您的需要和风险禁用任何不必要的服务。
其它资源
firewalld.zone(5)man page
43.2.3. 预定义的服务
服务可以是本地端口、协议、源端口和目的地列表,并在启用了服务时自动载入防火墙帮助程序模块列表。使用服务可节省用户时间,因为它们可以完成一些任务,如打开端口、定义协议、启用数据包转发等等,而不必在另外的步骤中设置所有任务。
服务配置选项和通用文件信息请参考 firewalld.service(5) man page。服务使用单独的 XML 配置文件指定,这些文件使用以下格式命名: *service-name*.xml。协议名称优先于 firewalld 中的服务或者应用程序名称。
可使用图形 firewall-config 工具、firewall-cmd 和 firewall-offline-cmd添加和删除服务。
另外,您可以编辑 /etc/firewalld/services/ 目录中的 XML 文件。如果用户没有添加或更改服务,则在 /etc/firewalld/services/ 中没有找到对应的 XML 文件。如果要添加或更改服务,/usr/lib/firewalld/services/ 目录中的文件可作为模板使用。
其它资源
firewalld.service(5)man page
43.3. 安装 firewall-config GUI 配置工具
要使用 firewall-config GUI 配置工具,请安装 firewall-config 软件包。
流程
在
root中输入以下命令:xxxxxxxxxx# yum install firewall-config另外,在
GNOME, use the **Super** key and typeSoftware中启动Software Sources应用程序。在搜索框中输入firewall,在右上角选择搜索按钮后会出现。选择搜索结果中的Firewall` 项并点击 Install 按钮。要运行
firewall-config,请使用firewall-config命令或按 Super 键进入Activities Overview,输入firewall,然后按 Enter 键。
43.4. 查看当前状态和设置 firewalld
43.4.1. 查看当前状态 firewalld
防火墙服务 firewalld 被默认安装在系统中。使用 firewalld CLI 界面检查该服务是否正在运行。
流程
查看服务的状态:
xxxxxxxxxx# firewall-cmd --state有关服务状态的更多信息,请使用
systemctl status子命令:xxxxxxxxxx# systemctl status firewalldfirewalld.service - firewalld - dynamic firewall daemonLoaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor prActive: active (running) since Mon 2017-12-18 16:05:15 CET; 50min agoDocs: man:firewalld(1)Main PID: 705 (firewalld)Tasks: 2 (limit: 4915)CGroup: /system.slice/firewalld.service└─705 /usr/bin/python3 -Es /usr/sbin/firewalld --nofork --nopid
其它资源
了解如何在编辑设置前强制设置 firewalld 以及哪些规则非常重要。要显示防火墙设置,请查看 第 43.4.2 节 “查看当前的 firewalld 设置”
43.4.2. 查看当前的 firewalld 设置
43.4.2.1. 使用 GUI 查看允许的服务
要使用图形化的 firewall-config 工具查看服务列表,请按 Super 键进入" 活动概览",输入 firewall,然后按 Enter 键。firewall-config 工具会出现。现在您可以在 Services 选项卡中查看服务列表。
另外,要用命令行启动图形防火墙配置工具,请输入以下命令:
xxxxxxxxxx$ firewall-config
Firewall Configuration 窗口将打开。请注意,这个命令可以以普通用户身份运行,但偶尔会提示您输入管理员密码。
43.4.2.2. 使用 CLI 查看 firewalld 设置
使用 CLI 客户端,可以从当前防火墙设置获得不同视角。--list-all 选项显示 firewalld 设置的完整概述。
firewalld 使用 zone 管理流量。如果 --zone 选项没有指定区,该命令将在分配给活跃网络接口和连接的默认区里有效。
要列出默认区的所有相关信息:
xxxxxxxxxx# firewall-cmd --list-allpublictarget: defaulticmp-block-inversion: nointerfaces:sources:services: ssh dhcpv6-clientports:protocols:masquerade: noforward-ports:source-ports:icmp-blocks:rich rules:
要指定显示设置的区域,在 firewall-cmd --list-all 命令中添加 --zone=*zone-name* 参数,例如:
xxxxxxxxxx# firewall-cmd --list-all --zone=homehometarget: defaulticmp-block-inversion: nointerfaces:sources:services: ssh mdns samba-client dhcpv6-client... [trimmed for clarity]
要查看特定信息(如服务或端口)的设置,请使用特定选项。请查看 firewalld 手册页或使用命令帮助获得选项列表:
xxxxxxxxxx# firewall-cmd --helpUsage: firewall-cmd [OPTIONS...]General Options-h, --help Prints a short help text and exists-V, --version Print the version string of firewalld-q, --quiet Do not print status messagesStatus Options--state Return and print firewalld state--reload Reload firewall and keep state information... [trimmed for clarity]
例如:查看当前区中允许哪些服务:
xxxxxxxxxx# firewall-cmd --list-servicesssh dhcpv6-client
注意
使用 CLI 工具列出某个子部分的设置有时会比较困难。例如,允许 SSH 服务, firewalld 为该服务打开所需的端口(22)。之后,如果您列出允许的服务,列表会显示 SSH 服务,但如果列出了开放端口,则不会显示任何服务。因此,建议您使用 --list-all 选项确定您收到完整信息。
43.5. 启动 firewalld
流程
要启动
firewalld,请输入以下命令root:xxxxxxxxxx# systemctl unmask firewalld# systemctl start firewalld要确定
firewalld在系统启动时自动启动,请以root身份输入以下命令:xxxxxxxxxx# systemctl enable firewalld
43.6. 停止 firewalld
流程
要停止
firewalld,请输入以下命令root:xxxxxxxxxx# systemctl stop firewalld要防止
firewalld在系统启动时自动启动:xxxxxxxxxx# systemctl disable firewalld访问
firewalldD-Bus接口以及其它服务需要firewalld来确保 firewalld 没有启动:xxxxxxxxxx# systemctl mask firewalld
43.7. 运行时和持久设置
所有在 runtime 模式中的更改都仅在 firewalld 运行时应用。当 firewalld 重启时,设置会恢复到其永久值。
要使更改在重启后保留,请使用 --permanent 选项再次应用。另外,若要在 firewalld 运行时保留更改,请使用 --runtime-to-permanent firewall-cmd 选项。
如果您在 firewalld 运行时只使用 --permanent 选项运行规则,则在 firewalld 重启前它们不会生效。但是,重启 firewalld 会关闭所有打开的端口并停止网络流量。
使用 CLI 修改运行时和永久配置中的设置
使用 CLI,您不会同时修改这两种模式的防火墙设置。您只能修改运行时模式或永久模式。要在永久模式中修改防火墙设置,请使用 firewall-cmd 命令的 --permanent 选项。
xxxxxxxxxx# firewall-cmd --permanent <other options>
如果没有这个选项,命令将修改运行时模式。
要更改这两种模式的设置,您可以使用以下两种方法:
更改运行时设置,然后将其永久保留,如下:
xxxxxxxxxx# firewall-cmd <other options># firewall-cmd --runtime-to-permanent设置永久性设置并将设置重新载入运行时模式:
xxxxxxxxxx# firewall-cmd --permanent <other options># firewall-cmd --reload
第一种方法允许您在将设置应用到永久模式前测试这些设置。
注意
特别是在远程系统中,不正确的设置可能会导致用户锁定其自身的机器。要防止这种情况,使用 --timeout 选项。在指定时间后,任何更改都会恢复到之前的状态。使用此选项排除 --permanent 选项。
例如,将 SSH 服务添加 15 分钟:
xxxxxxxxxx# firewall-cmd --add-service=ssh --timeout 15m
43.8. 验证永久 firewalld 配置
在某些情况下,例如在手动编辑 firewalld 配置文件后,管理员要验证更改是否正确。本节论述了如何验证 firewalld 服务的永久配置。
先决条件
firewalld服务正在运行。
流程
验证
firewalld服务的永久配置:xxxxxxxxxx# firewall-cmd --check-configsuccess如果永久配置有效,命令会返回
success。在其他情况下,命令返回一个带有更多详情的错误,如下所示:xxxxxxxxxx# firewall-cmd --check-configError: INVALID_PROTOCOL: 'public.xml': 'tcpx' not from {'tcp'|'udp'|'sctp'|'dccp'}
43.9. 使用 firewalld
43.9.1. 使用 CLI 禁用紧急事件的所有流量
在一个紧急情况下,比如系统攻击,可以禁用所有网络流量并关闭攻击者。
流程
要立即禁用网络流量,请切换 panic 模式:
xxxxxxxxxx# firewall-cmd --panic-on
重要
启用 panic 模式可停止所有网络流量。因此,它应只在对机器有物理访问权限或者使用串口控制台登录时才使用。
关闭 panic 模式会使防火墙恢复到其永久设置。关闭 panic 模式:
xxxxxxxxxx# firewall-cmd --panic-off
要查看是否打开或关闭 panic 模式,请使用:
xxxxxxxxxx# firewall-cmd --query-panic
43.9.2. 使用 CLI 控制预定义服务的流量
控制流量的最简单方法是在 firewalld中添加预定义服务。这会打开所有必需的端口并根据 服务定义文件 修改其他设置。
流程
检查该服务是否还未被允许:
xxxxxxxxxx# firewall-cmd --list-servicesssh dhcpv6-client列出所有预定义的服务:
xxxxxxxxxx# firewall-cmd --get-servicesRH-Satellite-6 amanda-client amanda-k5-client bacula bacula-client bitcoin bitcoin-rpc bitcoin-testnet bitcoin-testnet-rpc ceph ceph-mon cfengine condor-collector ctdb dhcp dhcpv6 dhcpv6-client dns docker-registry ...[trimmed for clarity]在允许的服务中添加服务:
xxxxxxxxxx# firewall-cmd --add-service=<service-name>使新设置持久:
xxxxxxxxxx# firewall-cmd --runtime-to-permanent
43.9.3. 使用 GUI 使用预定义服务控制流量
启用或禁用预定义或自定义服务:
- 启动 firewall-config 工具并选择要配置的服务的网络区。
- 选择
Services标签。 - 选择您要信任的每种服务类型的复选框,或者清除要阻断服务的复选框。
编辑服务:
- 启动 firewall-config 工具。
- 从标记的
Configuration菜单中选择Permanent。其它图标和菜单按钮会出现在服务窗口底部。 - 选择您要配置的服务。
Ports、Protocols 和 Source Port 标签页启用了为所选服务启用、更改和删除端口、协议和源端口。modules 标签页是用来配置 Netfilter 帮助程序模块。Destination 标签支持将流量限制到特定目的地地址和互联网协议(IPv4 或者 IPv6)。
注意
在 Runtime 模式中无法更改服务设置。
43.9.4. 添加新服务
可使用图形化的 firewall-config 工具 firewall-cmd和 firewall-offline-cmd添加和删除服务。另外,您可以编辑 /etc/firewalld/services/ 中的 XML 文件。如果用户没有添加或更改服务,那么在 /etc/firewalld/services/ 中没有找到对应的 XML 文件。如果要添加或更改服务,请将 /usr/lib/firewalld/services/ 文件用作模板。
注意
服务名称必须是字母数字,以及 _(下划线)和 -(横线)字符。
流程
要在终端中添加新服务,请使用 firewall-cmd 或 firewall-offline-cmd (如果未激活 firewalld)。
运行以下命令以添加新和空服务:
xxxxxxxxxx$ firewall-cmd --new-service=service-name --permanent要使用本地文件添加新服务,请使用以下命令:
xxxxxxxxxx$ firewall-cmd --new-service-from-file=service-name.xml --permanent您可以使用附加
--name=*service-name*选项更改服务名称。更改服务设置后,就会将服务更新副本放入
/etc/firewalld/services/中。作为
root,您可以输入以下命令手动复制服务:xxxxxxxxxx# cp /usr/lib/firewalld/services/service-name.xml /etc/firewalld/services/service-name.xml
firewalld 第一次从 /usr/lib/firewalld/services 加载文件。如果文件放在 /etc/firewalld/services 中,且它们有效,就会覆盖 /usr/lib/firewalld/services 中匹配的文件。一旦删除了 /etc/firewalld/services 中的匹配文件,或者要求 firewalld 加载服务的默认值,则将使用 /usr/lib/firewalld/services 中的覆盖文件。这只适用于永久性环境。为了在运行时环境中获取这些回退,需要重新加载。
43.9.5. 使用 CLI 控制端口
端口是可让操作系统接收和区分网络流量并将其转发到系统服务的逻辑设备。它们通常由侦听端口的守护进程来表示,它会等待到达这个端口的任何流量。
通常,系统服务侦听为它们保留的标准端口。例如,httpd 守护进程侦听端口 80。但默认情况下,系统管理员会将守护进程配置为在不同端口上侦听以便增强安全性或出于其他原因。
43.9.5.1. 打开端口
通过打开端口,系统可从外部访问,这代表了安全风险。通常,让端口保持关闭,且只在某些服务需要时才打开。
流程
要获得当前区的打开端口列表:
列出所有允许的端口:
xxxxxxxxxx# firewall-cmd --list-ports在允许的端口中添加一个端口,以便为入站流量打开这个端口:
xxxxxxxxxx# firewall-cmd --add-port=port-number/port-type使新设置持久:
xxxxxxxxxx# firewall-cmd --runtime-to-permanent
端口类型可以是 tcp、udp、sctp或 dccp。这个类型必须与网络通信的类型匹配。
43.9.5.2. 关闭端口
当不再需要开放端口时,在 firewalld中闭该端口。强烈建议您尽快关闭所有不必要的端口,因为端口处于打开状态会存在安全隐患。
流程
要关闭某个端口,请将其从允许的端口列表中删除:
列出所有允许的端口:
xxxxxxxxxx# firewall-cmd --list-ports[WARNING]====This command will only give you a list of ports that have been opened as ports. You will not be able to see any open ports that have been opened as a service. Therefore, you should consider using the --list-all option instead of --list-ports.====从允许的端口中删除端口,以便对传入的流量关闭:
xxxxxxxxxx# firewall-cmd --remove-port=port-number/port-type使新设置持久:
xxxxxxxxxx# firewall-cmd --runtime-to-permanent
43.9.6. 使用 GUI 打开端口
允许通过防火墙到特定端口的流量:
- 启动 firewall-config 工具并选择要更改的网络区。
- 选择
Ports标签并点击右侧的添加按钮。Port and Protocol窗口将打开。 - 输入要允许的端口号或者端口范围。
- 从列表中选择
tcp或udp。
43.9.7. 使用 GUI 控制协议的流量
使用特定的协议允许通过防火墙的流量:
- 启动 firewall-config 工具并选择要更改的网络区。
- 选择
Protocols标签并点击右首的Add按钮。Protocol窗口将打开。 - 您可以从列表中选择一个协议,也可以选择
Other Protocol复选框并在字段中输入协议。
43.9.8. 使用 GUI 打开源端口
允许通过防火墙的流量来自特定端口:
- 启动 firewall-config 工具并选择要更改的网络区。
- 选择
Source Port标签并点击右首的Add按钮。Source Port窗口将打开。 - 输入要允许的端口号或者端口范围。从列表中选择
tcp或udp。
43.10. 使用 firewalld 区
zones 代表一种更透明管理传入流量的概念。这些区域连接到联网接口或者分配一系列源地址。您可以独立为每个区管理防火墙规则,这样就可以定义复杂的防火墙设置并将其应用到流量。
43.10.1. 列出区域
流程
查看系统中有哪些可用区:
xxxxxxxxxx# firewall-cmd --get-zonesfirewall-cmd --get-zones命令显示系统中所有可用的区域,但不显示具体区的详情。查看所有区的详细信息:
xxxxxxxxxx# firewall-cmd --list-all-zones查看特定区的详细信息:
xxxxxxxxxx# firewall-cmd --zone=zone-name --list-all
43.10.2. 更改特定区的 firewalld 设置
第 43.9.2 节 “使用 CLI 控制预定义服务的流量” 和 第 43.9.5 节 “使用 CLI 控制端口” 解释了如何在当前工作区范围内添加服务或修改端口。有时,需要在不同区内设置规则。
流程
- 要在不同的区工作,请使用
--zone=*zone-name*选项。例如,允许在区 public 中使用SSH服务:
xxxxxxxxxx# firewall-cmd --add-service=ssh --zone=public
43.10.3. 更改默认区
系统管理员在其配置文件中为网络接口分配区域。如果接口没有被分配给指定区,它将被分配给默认区。每次重启 firewalld 服务后, firewalld 加载默认区的设置并使其活跃。
流程
设置默认区:
显示当前的默认区:
xxxxxxxxxx# firewall-cmd --get-default-zone设置新的默认区:
xxxxxxxxxx# firewall-cmd --set-default-zone zone-name注意
经过这个过程之后,设置为永久设置,即使没有
--permanent选项。
43.10.4. 将网络接口分配给区
可以为不同区定义不同的规则集,然后通过更改所使用的接口的区来快速改变设置。使用多个接口,可以为每个具体区设置一个区来区分通过它们的网络流量。
流程
要将区分配给特定的接口:
列出活跃区以及分配给它们的接口:
xxxxxxxxxx# firewall-cmd --get-active-zones为不同的区分配接口:
xxxxxxxxxx# firewall-cmd --zone=zone_name --change-interface=interface_name --permanent
43.10.5. 使用 nmcli 为连接分配区域
这个步骤描述了如何使用 nmcli 实用程序将 firewalld 区添加到网络管理器(NetworkManager)连接中。
流程
为 NetworkManager 连接配置集分配区域:
xxxxxxxxxx# nmcli connection profile modify connection.zone zone_name重新加载连接:
xxxxxxxxxx# nmcli connection up profile
43.10.6. 在 ifcfg 文件中手动将区分配给网络连接
当连接由 网络管理器(NetworkManager)管理时,必须了解它使用的区域。为每个网络连接指定区域,根据计算机有可移植设备的位置提供各种防火墙设置的灵活性。因此,可以为不同的位置(如公司或家)指定区域和设置。
流程
要为连接设置区,编辑
/etc/sysconfig/network-scripts/ifcfg-*connection_name*文件并添加为这个连接分配区的行:xxxxxxxxxxZONE=zone_name
43.10.7. 创建一个新区
要使用自定义区,创建一个新的区并使用它像预定义区一样。新区需要 --permanent 选项,否则命令无法正常工作。
流程
要创建新区:
创建一个新区:
xxxxxxxxxx# firewall-cmd --new-zone=zone-name检查是否在您的永久设置中添加了新的区:
xxxxxxxxxx# firewall-cmd --get-zones使新设置持久:
xxxxxxxxxx# firewall-cmd --runtime-to-permanent
43.10.8. 区配置文件
区也可以通过区配置文件创建。如果您需要创建新区,但想从不同区重复使用设置,这种方法就很有用了。
firewalld 区配置文件包含区的信息。这些区描述、服务、端口、协议、icmp-blocks、masquerade、forward-ports 和丰富的语言规则采用 XML 文件格式。文件名必须是 *zone-name*.xml,其中 zone-name 的长度限制为 17 个字符。区配置文件位于 /usr/lib/firewalld/zones/ 和 /etc/firewalld/zones/ 目录中。
以下示例显示了允许一个服务(SSH)和一个端口范围的配置,适用于 TCP 和 UDP 协议:
xxxxxxxxxx<?xml version="1.0" encoding="utf-8"?><zone><short>My zone</short><description>Here you can describe the characteristic features of the zone.</description><service name="ssh"/><port port="1025-65535" protocol="tcp"/><port port="1025-65535" protocol="udp"/></zone>
要更改那个区的设置,请添加或者删除相关的部分来添加端口、转发端口、服务等等。
其它资源
- 如需更多信息,请参阅
firewalld.zone手册页。
43.10.9. 使用区目标设定传入流量的默认行为
对于每个区,您可以设置一种处理尚未进一步指定的传入流量的默认行为。这种行为是通过设置区目标来定义的。有四个选项 - default、ACCEPT、REJECT 和 DROP。通过将目标设置为 ACCEPT,您接受除特定规则禁用的数据包外的所有传入的数据包。如果将目标设置为 REJECT 或 DROP,您将禁用所有传入的数据包,除非您在特定规则中允许的数据包。拒绝数据包时,会通知源机器,但丢弃数据包时不会发送任何信息。
流程
为区设置目标:
列出特定区的信息以查看默认目标:
xxxxxxxxxx$ firewall-cmd --zone=zone-name --list-all在区中设置一个新目标:
xxxxxxxxxx# firewall-cmd --permanent --zone=zone-name --set-target=<default|ACCEPT|REJECT|DROP>
43.11. 根据源使用区管理传入流量
43.11.1. 根据源使用区管理传入流量
您可以使用区管理传入的流量,根据其源管理传入的流量。这可让您对进入的流量进行排序,并将其路由到不同的区,以允许或禁止该流量可访问的服务。
如果您给区添加一个源,区就会成为活跃的,来自该源的所有进入流量都会被定向到它。您可以为每个区指定不同的设置,这些设置相应地应用于来自给定源的网络流量。即使只有一个网络接口,您可以使用更多区域。
43.11.2. 添加源
要将传入的流量路由到特定源,请将源添加到那个区。源可以是 CIDR 格式的 IP 地址或 IP 掩码。
注意
如果您添加多个带有重叠网络范围的区域,则根据区名称排序,且只考虑第一个区。
在当前区中设置源:
xxxxxxxxxx# firewall-cmd --add-source=<source>要为特定区设置源 IP 地址:
xxxxxxxxxx# firewall-cmd --zone=zone-name --add-source=<source>
以下流程将在 trusted 区中允许来自 192.168.2.15 的流量:
流程
列出所有可用区:
xxxxxxxxxx# firewall-cmd --get-zones将源 IP 添加到持久性模式的信任区中:
xxxxxxxxxx# firewall-cmd --zone=trusted --add-source=192.168.2.15使新设置持久:
xxxxxxxxxx# firewall-cmd --runtime-to-permanent
43.11.3. 删除源
从区中删除源会关闭来自它的网络流量。
流程
列出所需区的允许源:
xxxxxxxxxx# firewall-cmd --zone=zone-name --list-sources从区永久删除源:
xxxxxxxxxx# firewall-cmd --zone=zone-name --remove-source=<source>使新设置持久:
xxxxxxxxxx# firewall-cmd --runtime-to-permanent
43.11.4. 添加源端口
要启用根据原始端口对流量排序,使用 --add-source-port 选项指定源端口。您还可以将此选项与 --add-source 选项合并,将流量限制为特定 IP 地址或 IP 范围。
流程
添加源端口:
xxxxxxxxxx# firewall-cmd --zone=zone-name --add-source-port=<port-name>/<tcp|udp|sctp|dccp>
43.11.5. 删除源端口
通过删除源端口,您可以根据原始端口禁用对流量排序。
流程
要删除源端口:
xxxxxxxxxx# firewall-cmd --zone=zone-name --remove-source-port=<port-name>/<tcp|udp|sctp|dccp>
43.11.6. 使用区和源来允许一个服务只适用于一个特定的域
要允许来自特定网络的流量使用机器上的服务,请使用 zone 和 source。以下流程允许来自 192.168.1.0/24 的流量可以访问 HTTP 服务,其他网络流量会被阻塞。
流程
列出所有可用区:
xxxxxxxxxx# firewall-cmd --get-zonesblock dmz drop external home internal public trusted work将源添加到可信区,将来自源的网络流量通过区路由:
xxxxxxxxxx# firewall-cmd --zone=trusted --add-source=192.168.1.0/24在可信区中添加 http 服务:
xxxxxxxxxx# firewall-cmd --zone=trusted --add-service=http使新设置持久:
xxxxxxxxxx# firewall-cmd --runtime-to-permanent检查可信区是否活跃,且该服务是否允许。
xxxxxxxxxx# firewall-cmd --zone=trusted --list-alltrusted (active)target: ACCEPTsources: 192.168.1.0/24services: http
43.11.7. 根据协议配置区接受的流量
您可以允许基于协议的区域接受传入的流量。所有使用指定协议的流量都会被区接受,您可以在其中应用进一步的规则和过滤。
43.11.7.1. 在区中添加协议
通过在某个区中添加协议,您可以允许这个区接受使用这个协议的所有流量。
流程
在区中添加协议:
xxxxxxxxxx# firewall-cmd --zone=zone-name --add-protocol=port-name/tcp|udp|sctp|dccp|igmp
注意
要接收多播流量,请使用带有 igmp 值的 --add-protocol 选项。
43.11.7.2. 从区中删除协议
从某个区中删除协议,您可以停止接受区基于这个协议的所有流量。
流程
从区中删除协议:
xxxxxxxxxx# firewall-cmd --zone=zone-name --remove-protocol=port-name/tcp|udp|sctp|dccp|igmp
43.12. 配置 IP 地址伪装
以下流程描述了如何在系统中启用 IP 伪装。IP 伪装会在访问互联网时隐藏网关后面的独立机器。
流程
要检查 IP 伪装是否已启用(例如,对于
external区),以root的身份输入以下命令:xxxxxxxxxx# firewall-cmd --zone=external --query-masquerade如果已启用,该命令会输出
yes,退出状态为0。否则,会输出no,退出状态为1。如果省略zone,将使用默认区。要启用 IP 伪装,以
root的身份输入以下命令:xxxxxxxxxx# firewall-cmd --zone=external --add-masquerade要让此设置持久,请重复添加
--permanent选项的命令。
要禁用 IP 伪装,以 root 身份输入以下命令:
xxxxxxxxxx# firewall-cmd --zone=external --remove-masquerade --permanent
43.13. 端口转发
使用此方法重定向端口只可用于基于 IPv4 的流量。对于 IPv6 重定向设置,您必须使用丰富的规则。
要重定向到外部系统,需要启用伪装。如需更多信息,请参阅配置 IP 地址伪装。
43.13.1. 添加一个端口来重定向
使用 firewalld,您可以设置端口重定向,以便将到达系统中特定端口的进入流量传送到您选择的其他内部端口或另一台机器上的外部端口。
先决条件
- 在您将从一个端口的流量重新指向另一个端口或另一个地址前,您必须了解 3 个信息:数据包到达哪个端口,使用什么协议,以及您要重定向它们的位置。
流程
将端口重新指向另一个端口:
xxxxxxxxxx# firewall-cmd --add-forward-port=port=port-number:proto=tcp|udp|sctp|dccp:toport=port-number
将端口重定向到不同 IP 地址的另一个端口:
添加要转发的端口:
xxxxxxxxxx# firewall-cmd --add-forward-port=port=port-number:proto=tcp|udp:toport=port-number:toaddr=IP启用伪装:
xxxxxxxxxx# firewall-cmd --add-masquerade
43.13.2. 将 TCP 端口 80 重定向到同一台机器中的 88 端口
按照以下步骤将 TCP 端口 80 重定向到端口 88。
流程
将端口 80 重定向到 TCP 流量的端口 88:
xxxxxxxxxx# firewall-cmd --add-forward-port=port=80:proto=tcp:toport=88使新设置持久:
xxxxxxxxxx# firewall-cmd --runtime-to-permanent检查是否重定向了端口:
xxxxxxxxxx# firewall-cmd --list-all
43.13.3. 删除重定向的端口
要删除重定向的端口:
xxxxxxxxxx# firewall-cmd --remove-forward-port=port=port-number:proto=<tcp|udp>:toport=port-number:toaddr=<IP>
要删除重定向到不同地址的转发端口,请使用以下步骤。
流程
删除转发的端口:
xxxxxxxxxx# firewall-cmd --remove-forward-port=port=port-number:proto=<tcp|udp>:toport=port-number:toaddr=<IP>禁用伪装:
xxxxxxxxxx# firewall-cmd --remove-masquerade
43.13.4. 在同一台机器上将 TCP 端口 80 转发到端口 88
删除端口重定向:
流程
列出重定向的端口:
xxxxxxxxxx~]# firewall-cmd --list-forward-portsport=80:proto=tcp:toport=88:toaddr=从防火墙中删除重定向的端口:
xxxxxxxxxx~]# firewall-cmd --remove-forward-port=port=80:proto=tcp:toport=88:toaddr=使新设置持久:
xxxxxxxxxx~]# firewall-cmd --runtime-to-permanent
43.14. 管理 ICMP 请求
Internet Control Message Protocol(ICMP)是一个支持协议,不同的网络设备使用它来发送错误信息和显示连接问题的操作信息,例如:请求的服务不可用。ICMP 与 TCP 和 UDP 等传输协议不同,因为它没有用来在系统间交换数据。
不幸的是,使用 ICMP 信息(特别是 echo-request 和 echo-reply)可能会公开您的网络信息,这些信息可能会被利用而造成安全隐患。因此,firewalld 启用阻止 ICMP 请求来保护您的网络信息。
43.14.1. 列出和阻塞 ICMP 请求
列出 ICMP 请求
ICMP 请求在位于 /usr/lib/firewalld/icmptypes/ 目录中的独立 XML 文件中描述。您可以阅读这些文件来查看请求的描述。firewall-cmd 命令控制 ICMP 请求操作。
列出所有可用的
ICMP类型:xxxxxxxxxx# firewall-cmd --get-icmptypesIPv4、IPv6 或两个协议都可以使用
ICMP请求。要查看哪些协议使用了ICMP请求:xxxxxxxxxx# firewall-cmd --info-icmptype=<icmptype>ICMP请求的状态会显示为yes(请求当前被阻塞)或no(请求当前没有被阻塞)。检查ICMP请求当前是否被阻断:xxxxxxxxxx# firewall-cmd --query-icmp-block=<icmptype>
阻塞或取消阻塞 ICMP 请求
当您的服务器阻断 ICMP 请求时,它不会提供通常会提供的信息。但这并不意味着根本不给出任何信息。客户端收到特定 ICMP 请求被阻断的信息(拒绝)。应仔细考虑阻塞 ICMP 请求,因为它可能会造成通信问题,特别是 IPv6 流量。
检查
ICMP请求当前是否被阻断:xxxxxxxxxx# firewall-cmd --query-icmp-block=<icmptype>阻止
ICMP请求:xxxxxxxxxx# firewall-cmd --add-icmp-block=<icmptype>删除
ICMP请求的块:xxxxxxxxxx# firewall-cmd --remove-icmp-block=<icmptype>
在不提供任何信息的情况下阻断 ICMP 请求
通常,如果您阻断 ICMP 请求,客户端会知道您正在阻断它。这样潜在的攻击者仍然可以看到您的 IP 地址在线。要完全隐藏这些信息,您必须删除所有 ICMP 请求。
- 阻塞和丢弃所有
ICMP请求:
将区的目标设置为
DROP:xxxxxxxxxx# firewall-cmd --permanent --set-target=DROP
现在,除您明确允许的流量外,所有流量(包括 ICMP 请求)将被丢弃。
- 阻塞或丢弃特定的
ICMP请求,并允许其他请求:
将区的目标设置为
DROP:xxxxxxxxxx# firewall-cmd --permanent --set-target=DROP添加 ICMP 块 inversion 以阻止所有
ICMP请求:xxxxxxxxxx# firewall-cmd --add-icmp-block-inversion为那些
ICMP请求添加 ICMP 块:xxxxxxxxxx# firewall-cmd --add-icmp-block=<icmptype>使新设置持久:
xxxxxxxxxx# firewall-cmd --runtime-to-permanent
block inversion 用来转换 ICMP 请求块的设置,因此所有之前没有阻断的请求都因为区的目标改变为 DROP 而被阻断。被阻断的请求不会被阻断。这意味着,如果您想要取消阻塞请求,则必须使用 blocking 命令。
- 将块 inversion 恢复到完全 permissive 设置:
将区的目标设置为
default或ACCEPT:xxxxxxxxxx# firewall-cmd --permanent --set-target=default删除
ICMP请求的所有添加的块:xxxxxxxxxx# firewall-cmd --remove-icmp-block=<icmptype>删除
ICMP块 inversion:xxxxxxxxxx# firewall-cmd --remove-icmp-block-inversion使新设置持久:
xxxxxxxxxx# firewall-cmd --runtime-to-permanent
43.14.2. 使用 GUI 配置 ICMP 过滤器
- 要启用或禁用
ICMP过滤器,启动 firewall-config 工具并选择过滤消息的网络区。选择ICMP Filter标签并选择您想要过滤的每种ICMP消息类型的复选框。清除复选框以禁用过滤器。这个设置按方向设置,默认允许所有操作。 - 要编辑
ICMP类型,启动 firewall-config 工具并在标记为Configuration的菜单中选择Permanent模式。在 Services 窗口的底部会显示附加图标。选择 Yes 启用伪装并转发到另一台机器工作。 - 要启用反转
ICMP Filter,请点击右侧的Invert Filter复选框。现在只接受标记为ICMP的类型,所有其他都被拒绝。在使用 DROP 目标的区域里它们会被丢弃。
43.15. 使用 firewalld
要查看 firewalld 支持的 IP 集合类型列表,以 root 用户身份输入以下命令。
xxxxxxxxxx~]# firewall-cmd --get-ipset-typeshash:ip hash:ip,mark hash:ip,port hash:ip,port,ip hash:ip,port,net hash:mac hash:net hash:net,iface hash:net,net hash:net,port hash:net,port,net
43.15.1. 使用 CLI 配置 IP 设置选项
IP 集合可以在 firewalld 区用作源,也可以作为源丰富的规则使用。在 Red Hat Enterprise Linux 中,首选的方法是使用在直接规则 firewalld 中创建的 IP 集合。
要列出永久环境中
firewalld已知的 IP 集,请使用以下命令root:xxxxxxxxxx# firewall-cmd --permanent --get-ipsets要添加新 IP 集,请使用以下命令,将永久环境用作
root:xxxxxxxxxx# firewall-cmd --permanent --new-ipset=test --type=hash:netsuccess以上命令为
IPv4创建了名称为 test 类型为hash:net的新 IP 设置。要创建用于IPv6的 IP 集,添加--option=family=inet6选项。要使新设置在运行时环境中有效,请重新载入firewalld。使用以下命令列出新 IP 设置:
rootxxxxxxxxxx# firewall-cmd --permanent --get-ipsetstest要获得有关 IP 集的更多信息,以
root用户身份运行以下命令:xxxxxxxxxx# firewall-cmd --permanent --info-ipset=testtesttype: hash:netoptions:entries:请注意,IP 集目前没有任何条目。
要在 test IP 集中添加一个项,以
root身份运行以下命令:xxxxxxxxxx# firewall-cmd --permanent --ipset=test --add-entry=192.168.0.1success前面的命令将 IP 地址 192.168.0.1 添加到 IP 集合中。
要获取 IP 集合中当前条目列表,以
root用户身份运行以下命令:xxxxxxxxxx# firewall-cmd --permanent --ipset=test --get-entries192.168.0.1生成包含 IP 地址列表的文件,例如:
xxxxxxxxxx# cat > iplist.txt <<EOL192.168.0.2192.168.0.3192.168.1.0/24192.168.2.254EOL包含 IP 集合 IP 地址列表的文件应该每行包含一个条目。以 hash、分号或空行开头的行将被忽略。
要添加 iplist.txt 文件中的地址,以
root身份运行以下命令:xxxxxxxxxx# firewall-cmd --permanent --ipset=test --add-entries-from-file=iplist.txtsuccess要查看 IP 集合的扩展条目列表,以
root身份运行以下命令:xxxxxxxxxx# firewall-cmd --permanent --ipset=test --get-entries192.168.0.1192.168.0.2192.168.0.3192.168.1.0/24192.168.2.254要从 IP 集合中删除地址并检查更新的条目列表,以
root身份运行以下命令:xxxxxxxxxx# firewall-cmd --permanent --ipset=test --remove-entries-from-file=iplist.txtsuccess# firewall-cmd --permanent --ipset=test --get-entries192.168.0.1您可以将 IP 集合作为一个源添加到区,以便处理所有来自 IP 集合中列出的任意地址的网络流量。例如:要将 test IP 集添加为 drop 区的一个源,以便丢弃所有来自在 test IP 集中列出的所有条目的所有数据包,以
root身份运行以下命令:xxxxxxxxxx# firewall-cmd --permanent --zone=drop --add-source=ipset:testsuccess源中的
ipset:前缀显示firewalld,源是一个 IP 集,而不是一个 IP 地址或地址范围。
只有创建和删除 IP 集限于永久环境,其它所有 IP 设置选项也可以在运行时环境中使用,即使没有 --permanent 选项。
警告
红帽不推荐使用不是通过 firewalld 管理的 IP 集。要使用这样的 IP 组,需要一个永久直接规则来引用集合,且必须添加自定义服务来创建这些 IP 组件。这个服务需要在 firewalld 启动前启动,否则 firewalld 无法使用这些组添加直接规则。您可以使用 /etc/firewalld/direct.xml 文件添加永久直接规则。
43.16. 丰富规则的优先级
默认情况下,丰富规则根据其规则操作进行组织。例如: deny 规则优先于 allow 规则。priority 参数丰富的规则可让管理员对丰富的规则及其执行顺序进行精细的控制。
43.16.1. priority 参数如何将规则组织为不同的链
您可以将 priority 参数设置为在 -32768 和 32767 之间的任意数量,较低值具有更高的优先级。
firewalld 服务根据优先级值在不同的链中组织规则:
- 优先级低于 0:规则被重定向到带有
_pre后缀的链中。 - 优先级高于 0:规则被重定向到使用
_post后缀的链中。 - 优先级等于 0:基于操作,规则会被重定向到带有
_log、_deny或_allow操作的链中。
在这些子链中,firewalld 会根据其优先级值对规则排序。
43.16.2. 设置丰富的规则的优先级
以下流程介绍了一个示例,它创建了一个丰富的规则,它使用 priority 参数记录被他规则不允许或拒绝的所有流量。您可以使用此规则标记意非预期的流量。
流程
添加一个带有非常低优先级的丰富规则来记录未由其他规则匹配的所有流量:
xxxxxxxxxx# firewall-cmd --add-rich-rule='rule priority=32767 log prefix="UNEXPECTED: " limit value="5/m"'这个命令还会将日志条目数限制为每分钟
5个。另外,显示上一步中命令创建的
nftables规则:xxxxxxxxxx# nft list chain inet firewalld filter_IN_public_posttable inet firewalld {chain filter_IN_public_post {log prefix "UNEXPECTED: " limit rate 5/minute}}
43.17. 配置防火墙锁定
如果本地应用程序或服务是作为 root 运行的,(例如: libvirt),则可以更改防火墙配置。使用这个特性,管理员可以锁定防火墙配置,从而达到没有应用程序或只有添加到锁定白名单中的应用程序可以请求防火墙更改的目的。锁定设置默认会被禁用。如果启用,用户就可以确定,防火墙没有被本地的应用程序或服务进行了不必要的配置更改。
43.17.1. 使用 CLI 配置锁定
要查询是否启用锁定,使用以下命令:
rootxxxxxxxxxx# firewall-cmd --query-lockdown如果启用了锁定,则命令会输出
yes,退出状态为0。否则,会输出no,退出状态为1。要启用锁定,以
root身份输入以下命令:xxxxxxxxxx# firewall-cmd --lockdown-on要禁用锁定,以
root身份使用以下命令:xxxxxxxxxx# firewall-cmd --lockdown-off
43.17.2. 使用 CLI 配置锁定白名单选项
锁定白名单中可以包含命令、安全上下文、用户和用户 ID。如果白名单中的某个命令条目以星号""结尾,则所有以该命令开头的命令行都匹配。如果没有 "",那么包括参数的绝对命令必须匹配。
上下文是正在运行的应用程序或服务的安全(SELinux)上下文。要获得正在运行的应用程序的上下文,请使用以下命令:
xxxxxxxxxx$ ps -e --context该命令返回所有正在运行的应用程序。通过 grep 工具管道输出以便获取您感兴趣的应用程序。例如:
xxxxxxxxxx$ ps -e --context | grep example_program要列出白名单中的所有命令行,输入以下命令:
rootxxxxxxxxxx# firewall-cmd --list-lockdown-whitelist-commands要在白名单中添加一个命令 command,以
root身份运行以下命令:xxxxxxxxxx# firewall-cmd --add-lockdown-whitelist-command='/usr/bin/python3 -Es /usr/bin/command'要从白名单中删除命令 command,以
root身份运行以下命令:xxxxxxxxxx# firewall-cmd --remove-lockdown-whitelist-command='/usr/bin/python3 -Es /usr/bin/command'要查询 command 命令是否位于白名单中,以
root身份输入以下命令:xxxxxxxxxx# firewall-cmd --query-lockdown-whitelist-command='/usr/bin/python3 -Es /usr/bin/command'如果为 true,该命令会输出
yes,且状态为0。否则,会输出no,退出状态为1。要列出白名单中的所有安全上下文,以
root身份输入以下命令:xxxxxxxxxx# firewall-cmd --list-lockdown-whitelist-contexts要在白名单中添加上下文 context,以
root身份输入以下命令:xxxxxxxxxx# firewall-cmd --add-lockdown-whitelist-context=context要从白名单中删除上下文 context,以
root身份输入以下命令:xxxxxxxxxx# firewall-cmd --remove-lockdown-whitelist-context=context要查询上下文 context 是否在白名单中,以
root身份输入以下命令:xxxxxxxxxx# firewall-cmd --query-lockdown-whitelist-context=context如果为 true,输出会显示
yes,退出状态为0,否则输出1,退出状态为no。要列出白名单中的所有用户 ID,以
root身份输入以下命令:xxxxxxxxxx# firewall-cmd --list-lockdown-whitelist-uids要在白名单中添加用户 ID uid,以
root身份输入以下命令:xxxxxxxxxx# firewall-cmd --add-lockdown-whitelist-uid=uid要从白名单中删除用户 ID uid,以
root身份输入以下命令:xxxxxxxxxx# firewall-cmd --remove-lockdown-whitelist-uid=uid要查询用户 ID uid 是否在白名单中,请输入以下命令:
xxxxxxxxxx$ firewall-cmd --query-lockdown-whitelist-uid=uid如果为 true,输出会显示
yes,退出状态为0,否则输出1,退出状态为no。要列出白名单中的所有用户名,以
root身份输入以下命令:xxxxxxxxxx# firewall-cmd --list-lockdown-whitelist-users要在白名单中添加用户名 user,以
root身份输入以下命令:xxxxxxxxxx# firewall-cmd --add-lockdown-whitelist-user=user要从白名单中删除用户名 user,以
root身份输入以下命令:xxxxxxxxxx# firewall-cmd --remove-lockdown-whitelist-user=user要查询用户名 user 是否在白名单中,请输入以下命令:
xxxxxxxxxx$ firewall-cmd --query-lockdown-whitelist-user=user如果为 true,输出会显示
yes,退出状态为0,否则输出1,退出状态为no。
43.17.3. 使用配置文件配置锁定白名单选项
默认白名单配置文件包含 NetworkManager 上下文和 libvirt 默认上下文。用户 ID 0 也位于列表中。
xxxxxxxxxx<?xml version="1.0" encoding="utf-8"?><whitelist><selinux context="system_u:system_r:NetworkManager_t:s0"/><selinux context="system_u:system_r:virtd_t:s0-s0:c0.c1023"/><user id="0"/></whitelist>
以下是一个白名单配置文件示例,为 firewall-cmd 工具程序启用所有命令,对于一个名为 user,用户 ID 为 815 的用户:
xxxxxxxxxx<?xml version="1.0" encoding="utf-8"?><whitelist><command name="/usr/libexec/platform-python -s /bin/firewall-cmd*"/><selinux context="system_u:system_r:NetworkManager_t:s0"/><user id="815"/><user name="user"/></whitelist>
这个示例显示 user id 和 user name,但只需要一个选项。Python 是程序解释器,它位于命令行的前面。您还可以使用特定的命令,例如:
xxxxxxxxxx/usr/bin/python3 /bin/firewall-cmd --lockdown-on
在这个示例中,只允许 --lockdown-on 命令。
在 Red Hat Enterprise Linux 中,所有工具都放置在 /usr/bin/ 目录中,/bin/ 目录被符号链接到 /usr/bin/ 目录。换句话说,虽然作为 root 输入 firewall-cmd 的路径时,可能会解析为 /bin/firewall-cmd,但现在可以使用 /usr/bin/firewall-cmd。所有新脚本都应该使用新位置。但请注意,如果以 root 身份运行的脚本被写入来使用 /bin/firewall-cmd 路径,在白名单中除了被非 root 用户的 /usr/bin/firewall-cmd 路径外,还需要添加命令的路径。
一个命令的 name 属性末尾的 * 意味着,所有以这个字符串开头的命令都匹配。如果没有 *,包括参数的绝对命令必须匹配。
43.18. 记录已拒绝数据包的日志
如果在 firewalld 中使用 LogDenied 选项,可以为拒绝的数据包添加一个简单的日志记录机制。这些是被拒绝或丢弃的数据包。要更改日志的设置,编辑 /etc/firewalld/firewalld.conf 文件或使用命令行或者 GUI 配置工具。
如果启用了 LogDenied,则会在 INPUT、FORWARD 和 OUTPUT 链中的拒绝和丢弃规则前添加日志规则,并在区中最终拒绝和丢弃规则。这个设置的可能值有: all、unicast、broadcast、multicast和 off。默认设置为 off。使用 unicast、broadcast 和 multicast 设置时, pkttype 匹配用于匹配 link-layer 数据包类型。使用 all 时会记录所有数据包。
要使用 firewall-cmd 列出实际的 LogDenied 设置,以 root 身份运行以下命令:
xxxxxxxxxx# firewall-cmd --get-log-deniedoff
要更改 LogDenied 设置,请使用以下命令 root:
xxxxxxxxxx# firewall-cmd --set-log-denied=allsuccess
要使用 firewalld GUI 配置工具更改 LogDenied 设置,启动 firewall-config,点 Options 菜单并选择 Change Log Denied。此时会出现 LogDenied 窗口。在菜单中选择新的 LogDenied 设置并点击确定。
43.19. 相关信息
以下资源提供了关于 firewalld 的更多信息。
安装的文档
firewalld(1)man page - 描述了firewalld的命令选项。firewalld.conf(5)man page - 包含配置firewalld的信息。firewall-cmd(1)man page - 描述firewalld命令行客户端的命令选项。firewall-config(1)man page - 描述了 firewall-config 工具的设置。firewall-offline-cmd(1)man page - 描述firewalld离线命令行客户端的命令选项。firewalld.icmptype(5)man page - 描述了用于ICMP过滤的 XML 配置文件。firewalld.ipset(5)man page - 描述了firewalldIP组件的 XML 配置文件。firewalld.service(5)man page - 描述了 firewalld 服务 的 XML 配置文件。firewalld.zone(5)man page - 描述了用于firewalld区配置的 XML 配置文件。firewalld.direct(5)man page - 描述了firewalld直接接口配置文件。firewalld.lockdown-whitelist(5)man page - 描述了firewalld锁定白名单配置文件。firewalld.richlanguage(5)man page - 描述了firewalld丰富的语言规则语法。firewalld.zones(5)man page - 介绍了区的一般信息以及如何配置它们。firewalld.dbus(5)man page - 描述了firewalld的D-Bus接口。
在线文档
- http://www.firewalld.org/ -
firewalld主页。
第 44 章 nftables 入门
nftables 框架提供数据包分类工具,它是 iptables、ip6tables、arptables 和 ebtables 工具的指定后台。与之前的数据包过滤工具相比,它在方便、特性和性能方面提供了大量改进,最重要的是:
- 查找表而不是线性处理
IPv4和IPv6协议都使用同一个框架- 规则会以一个整体被应用,而不是分为抓取、更新和存储完整的规则集的步骤
- 支持在规则集(
nftrace)中进行调试和追踪,并监控追踪事件(在nft工具中) - 更加一致和压缩的语法,没有特定协议的扩展
- 用于第三方应用程序的 Netlink API
和 iptables类似, nftables 使用表来存储链。链包含执行动作的独立规则。nft 工具替换了之前数据包过滤框架中的所有工具。libnftnl 库可用于通过 libmnl 库与 nftables Netlink API 进行底层交互。
可使用 nft list rule set 命令查看模块对 nftables 规则集的影响。这些工具将表、链、规则、集合和其他对象添加到 nftables 规则集中,请注意,nftables 规则集操作(如 nft flush ruleset 命令)可能会影响使用以前独立的旧命令安装的规则集。
44.1. 从 iptables 迁移到 nftables
如果您将服务器升级到 RHEL 8,或者防火墙配置仍然使用 iptables 规则,您可以将 iptables 规则迁移到 nftables。
44.1.1. 使用 firewalld、nftables 或者 iptables 时
以下是您应该使用以下工具之一的概述:
firewalld:使用firewalld实用程序在工作站中配置防火墙。该工具非常容易使用,并涵盖本情境的典型用例。nftables:使用nftables程序设置复杂的防火墙,比如为整个网络设置。iptables:Red Hat Enterprise Linux 8 中的iptables工具程序使用nf_tables内核 API 而不是legacy后端。nf_tablesAPI 提供向后兼容性,使用iptables命令的脚本仍然可用于 Red Hat Enterprise Linux 8。对于新的防火墙脚本,红帽建议使用nftables。
重要
要避免不同的防火墙服务相互影响,在 RHEL 主机中只有一个服务,并禁用其他服务。
44.1.2. 将 iptables 规则转换为 nftables 规则
Red Hat Enterprise Linux 8 提供 iptables-translate 和 ip6tables-translate 工具来将现有 iptables 或 ip6tables 规则转换为对等的 nftables 规则。
请注意,一些扩展可能缺少响应的转换支持。如果存在这种扩展,该工具会输出以 # 符号为前缀的未转换的规则。例如:
xxxxxxxxxx# iptables-translate -A INPUT -j CHECKSUM --checksum-fillnft # -A INPUT -j CHECKSUM --checksum-fill
另外,用户还可以使用 iptables-restore-translate 和 ip6tables-restore-translate 工具来翻译规则转储。请注意,在此之前,用户可以使用 iptables-save 或者 ip6tables-save 命令打印当前规则的转储。例如:
xxxxxxxxxx# iptables-save >/tmp/iptables.dump# iptables-restore-translate -f /tmp/iptables.dump# Translated by iptables-restore-translate v1.8.0 on Wed Oct 17 17:00:13 2018add table ip nat...
要获得更多信息以及可能的选项和值列表,请使用 iptables-translate --help 命令。
44.2. 编写和执行 nftables 脚本
nftables 框架提供了一个原生脚本环境,它比使用 shell 脚本维护防火墙规则得到主要优势:执行脚本是原子的(以一个整体运行)。这意味着,系统会应用整个脚本,或者在出现错误时防止执行。这样可保证防火墙始终处于一致状态。
另外,nftables 脚本环境使管理员能够:
- 添加评论
- 定义变量
- 包含其他规则集文件
本节介绍如何使用这些功能,以及创建和执行 nftables 脚本。
当您安装 nftables 软件包时,Red Hat Enterprise Linux 会在 /etc/nftables/ 目录中自动生成 *.nft 脚本。这些脚本包含为不同目的创建表和空链的命令。您可以扩展这些文件或编写脚本。
44.2.1. nftables 脚本中所需的脚本标头
和其它脚本类似,nftables 脚本在脚本的第一行中包括一个命令用来设定解释器指令。
nftables 脚本必须以以下行开头:
xxxxxxxxxx#!/usr/sbin/nft -f
重要
如果您省略 -f 参数,nft 实用程序不会读取脚本并显示 Error: syntax error, unexpected newline, expecting string。
44.2.2. 支持的 nftables 脚本格式
nftables 脚本环境支持以下格式的脚本:
您可以以与
nft list ruleset命令相同的格式编写脚本,显示规则集:xxxxxxxxxx#!/usr/sbin/nft -f# Flush the rule setflush rulesettable inet example_table {chain example_chain {# Chain for incoming packets that drops all packets that# are not explicitly allowed by any rule in this chaintype filter hook input priority 0; policy drop;# Accept connections to port 22 (ssh)tcp dport ssh accept}}您可以使用与
nft命令相同的语法:xxxxxxxxxx#!/usr/sbin/nft -f# Flush the rule setflush ruleset# Create a tableadd table inet example_table# Create a chain for incoming packets that drops all packets# that are not explicitly allowed by any rule in this chainadd chain inet example_table example_chain { type filter hook input priority 0 ; policy drop ; }# Add a rule that accepts connections to port 22 (ssh)add rule inet example_table example_chain tcp dport ssh accept
44.2.3. 运行 nftables 脚本
要运行 nftables 脚本,该脚本必须是可执行脚本。只有脚本包含在另一个脚本中时,它并不需要可执行。这个步骤描述了如何使脚本可执行并运行脚本。
先决条件
- 本节的步骤假设您在文件
/etc/nftables/example_firewall.nft中保存了nftables脚本。
流程
只需要执行一次的步骤:
另外,还可将脚本的所有者设置为
root:xxxxxxxxxx# chown root /etc/nftables/example_firewall.nft使脚本可以被其所有者执行:
xxxxxxxxxx# chmod u+x /etc/nftables/example_firewall.nft
运行脚本:
xxxxxxxxxx# /etc/nftables/example_firewall.nft如果没有输出结果,系统将成功执行该脚本。
重要
即使
nft成功执行脚本,在脚本中错误地放置规则、缺失的参数或其他问题都有可能导致防火墙的行为不如预期。
其它资源
- 有关设置文件所有者的详情,请参考
chown(1)man page。 - 有关设置文件权限的详情,请查看
chmod(1)man page。 - 第 44.2.7 节 “系统引导时自动载入 nftables 规则”
44.2.4. 使用 nftables 脚本中的注释
nftables 脚本环境将 # 字符右边的所有内容都作为注释来解释。
例 44.1. nftables 脚本中的注释
注释可在一行的开始,也可以在命令后:
xxxxxxxxxx...# Flush the rule setflush rulesetadd table inet example_table # Create a table...
44.2.5. 使用 nftables 脚本中的变量
要在 nftables 脚本中定义变量,请使用 define 关键字。您可以在变量中存储单个值和匿名集合。对于更复杂的场景,请使用 set 或 verdict 映射。
只有一个值的变量
以下示例定义了名为 INET_DEV 的变量,其值为 enp1s0:
xxxxxxxxxxdefine INET_DEV = enp1s0
您可以通过在脚本中写入 $ 符号后加上变量名称来使用脚本中的变量:
xxxxxxxxxx...add rule inet example_table example_chain iifname $INET_DEV tcp dport ssh accept...
包含匿名集合的变量
以下示例定义了一个包含匿名集合的变量:
xxxxxxxxxxdefine DNS_SERVERS = { 192.0.2.1, 192.0.2.2 }
您可以通过在脚本中写入 $ 符号后加上变量名称来使用脚本中的变量:
xxxxxxxxxxadd rule inet example_table example_chain ip daddr $DNS_SERVERS accept
注意
请注意,在规则中使用大括号时具有特殊的意义,因为它们表示变量代表一个集合。
其它资源
- 有关集合的详情,请参阅 第 44.5 节 “使用 nftables 命令中的设置”。
- 有关 ver 字典映射的详情,请参考 第 44.6 节 “在 nftables 命令中使用 verdict 映射”。
44.2.6. 在 nftables 脚本中包含文件
nftables 脚本环境可让管理员使用 include 说明包括其他脚本。
如果您只指定没有包括绝对路径或相对路径的文件名, nftables 包含默认搜索路径中的文件,在 Red Hat Enterprise Linux 中为 /etc。
例 44.2. 包含默认搜索目录中的文件
从默认搜索目录中包含一个文件:
xxxxxxxxxxinclude "example.nft"
例 44.3. 包含目录中的所有 *.nft 文件
包含以 *.nft 结尾的、存储在 /etc/nftables/rulesets/ 目录中的文件:
xxxxxxxxxxinclude "/etc/nftables/rulesets/*.nft"
请注意 include 语句不匹配与以点开头的文件。
其它资源
- 详情请查看
Include filesman page 中的nft(8)部分。
44.2.7. 系统引导时自动载入 nftables 规则
nftables systemd 服务加载包括在 /etc/sysconfig/nftables.conf 文件中的防火墙脚本。这部分论述了如何在系统引导时载入防火墙规则。
先决条件
nftables脚本存储在/etc/nftables/目录中。
流程
编辑
/etc/sysconfig/nftables.conf文件。如果您在安装
nftables软件包时增强了/etc/nftables/中创建的*.nft脚本,请取消对这些脚本的include状态的注释。如果您从头编写脚本,添加
include语句来包括这些脚本。例如,要在nftables服务启动时载入/etc/nftables/*example*.nft脚本,请添加:xxxxxxxxxxinclude "/etc/nftables/example.nft"
启用
nftables服务。xxxxxxxxxx# systemctl enable nftables(可选)启动
nftables服务在不重启系统的情况下加载防火墙规则:xxxxxxxxxx# systemctl start nftables
其它资源
44.3. 创建和管理 nftables 表、链和规则
本节介绍如何显示 nftables 规则集以及如何管理它们。
44.3.1. 标准链优先级值和文本名称
当您创建一个链时,priority 可以设置整数值或标准名称,用于指定具有相同 hook 值链的顺序。
名称和值根据 xtables 注册其默认链时使用什么优先级来定义。
注意
nft list chains 命令默认显示文本优先级值。您可以通过将 -y 选项传递给命令来查看数字值。
例 44.4. 使用文本值设定优先级
以下命令使用标准优先级值 50,在 example_table 中创建一个名为 example_chain 的链:
xxxxxxxxxx# nft add chain inet *example_table* *example_chain* { type *filter* hook *input* priority *50* \; policy accept \; }
因为优先级是一个标准值,您可以选择使用文本值:
xxxxxxxxxx# nft add chain inet *example_table* *example_chain* { type *filter* hook *input* priority *security* \; policy accept \; }
表 44.1. 标准优先级名称、系列和 hook 兼容性列表
| 名称 | 值 | 系列 | Hook |
|---|---|---|---|
raw | -300 | ip, ip6, inet | all |
mangle | -150 | ip, ip6, inet | all |
dstnat | -100 | ip, ip6, inet | prerouting |
filter | 0 | ip, ip6, inet, arp, netdev | all |
security | 50 | ip, ip6, inet | all |
srcnat | 100 | ip, ip6, inet | POSTROUTING |
所有系列都使用相同的值,但 bridge 家族采用以下数值:
表 44.2. 标准优先级名称,以及网桥线的 hook 兼容性
| 名称 | 值 | Hook |
|---|---|---|
dstnat | -300 | prerouting |
filter | -200 | all |
out | 100 | output |
srcnat | 300 | postrouting |
其它资源
- 有关您可以在链中运行的其他操作的详情,请查看
nft(8)man page 中的Chains部分。
44.3.2. 显示 nftables 规则集
nftables 的规则集合包含表、链和规则。本节介绍如何显示这些规则集。
流程
要显示所有规则集,请输入:
xxxxxxxxxx# nft list rulesettable inet example_table {chain example_chain {type filter hook input priority filter; policy accept;tcp dport http accepttcp dport ssh accept}}注意
默认情况下,
nftables不预先创建表。因此,在没有表的情况下显示主机上设置的规则,nft list ruleset命令不会显示输出。
44.3.3. 创建 nftables 表
nftables 中的表是包含链、规则、集合和其他对象集合的名称空间。本节介绍如何创建表。
每个表都必须定义一个地址系列。表的地址系列定义了表进程的类型。在创建表时,您可以设置以下地址系列之一:
ip:仅匹配 IPv4 数据包。如果没有指定地址系列,这是默认设置。ip6:只匹配 IPv6 数据包。inet:匹配 IPv4 和 IPv6 数据包。arp:匹配 IPv4 地址解析协议(ARP)数据包。bridge:与绕过桥接设备的数据包匹配。netdev:与来自 ingress 的数据包匹配。
流程
使用
nft add table命令创建新表格。例如,要创建一个名为example_table的表,用于处理 IPv4 和 IPv6 数据包:xxxxxxxxxx# nft add table inet example_table另外,还可列出规则集中的所有表:
xxxxxxxxxx# nft list tablestable inet example_table
其它资源
- 有关地址系列的详情,请查看
Address familiesman page 中的nft(8)部分。 - 有关您可以在表中运行的其他操作的详情,请查看
nft(8)man page 中的Tables部分。
44.3.4. 创建 nftables 链
chains 是规则的容器。存在以下两种规则类型:
- 基本链:您可以使用基础链作为来自网络堆栈的数据包的入口点。
- 常规链:您可以使用常规链作为
jump目标,并更好地组织规则。
这个步骤描述了如何在现有表中添加基本链。
先决条件
- 已存在您要添加新链的表。
流程
使用
nft add chain命令创建新链。例如,要在example_table中创建一个名为example_chain的链:xxxxxxxxxx# nft add chain inet example_table example_chain { type filter hook input priority 0 \; policy accept \; }重要
要避免 shell 认为分号作为命令结尾,您必须用反斜杠转义分号。
这个链过滤传入的数据包。
priority参数指定nftables进程使用相同 hook 值链的顺序。低优先级值在高优先级值的前面。policy参数为这个链中规则设置默认操作。请注意,如果您远程登录到服务器,并且将默认策略设置为drop,如果没有其他规则允许远程访问,则可以立即断开连接。另外,还可以显示所有链:
xxxxxxxxxx# nft list chainstable inet example_table {chain example_chain {type filter hook input priority filter; policy accept;}}
其它资源
- 有关地址系列的详情,请查看
Address familiesman page 中的nft(8)部分。 - 有关您可以在链中运行的其他操作的详情,请查看
nft(8)man page 中的Chains部分。
44.3.5. 在 nftables 链中添加规则
本节解释了如何在现有 nftables 链中添加规则。默认情况下,nftables add rule 命令会在链末尾附加一个新的规则。
如果您想在 chain 的开头插入规则,请参阅 第 44.3.6 节 “在 nftables 链中插入规则”。
先决条件
- 您要添加该规则的链已存在。
流程
要添加新规则,使用
nft add rule命令。例如,在example_table的example_chain中添加一条规则来允许端口 22 上的 TCP 流量:xxxxxxxxxx# nft add rule inet example_table example_chain tcp dport 22 accept您可以选择指定服务名称而不是端口号。在这个示例中,您可以使用
ssh而不是端口号22。请注意,服务名称根据在/etc/services文件中的条目解析为端口号。另外,还可在
example_table中显示所有链及其规则:xxxxxxxxxx# nft list table inet example_tabletable inet example_table {chain example_chain {type filter hook input priority filter; policy accept;...tcp dport ssh accept}}
其它资源
- 有关地址系列的详情,请查看
Address familiesman page 中的nft(8)部分。 - 有关您可以在规则中运行的其他操作的详情,请查看
nft(8)man page 中的Rules部分。
44.3.6. 在 nftables 链中插入规则
本节解释了如何使用 nftables insert rule 命令在现有 nftables chain 的开头插入规则。如果您想在链末尾添加一条规则,请参阅 第 44.3.5 节 “在 nftables 链中添加规则”。
先决条件
- 您要添加该规则的链已存在。
流程
要插入新规则,使用
nft insert rule命令。例如,要在example_chain的example_table中插入一个规则来允许端口 22 上的 TCP 流量:xxxxxxxxxx# nft insert rule inet example_table example_chain tcp dport 22 accept您还可以指定服务名称而不是端口号。在这个示例中,您可以使用
ssh而不是端口号22。请注意,服务名称根据在/etc/services文件中的条目解析为端口号。另外,还可在
example_table中显示所有链及其规则:xxxxxxxxxx# nft list table inet example_tabletable inet example_table {chain example_chain {type filter hook input priority filter; policy accept;tcp dport ssh accept...}}
其它资源
- 有关地址系列的详情,请查看
Address familiesman page 中的nft(8)部分。 - 有关您可以在规则中运行的其他操作的详情,请查看
nft(8)man page 中的Rules部分。
44.4. 使用 nftables 配置 NAT
使用 nftables,您可以配置以下网络地址转换(NAT)类型:
- 伪装
- 源 NAT(SNAT)
- 目标 NAT(DNAT)
44.4.1. 不同的 NAT 类型: masquerading、source NAT 和 destination NAT
这些是不同的网络地址转换(NAT)类型:
伪装和源 NAT(SNAT)
使用以上 NAT 类型之一更改数据包的源 IP 地址。例如:互联网供应商不会路由保留的 IP 范围,如
10.0.0.0/8。如果您在网络中使用保留的 IP 范围,而且用户可以访问互联网中的服务器,请将这些范围内的数据包源 IP 地址映射到一个公共 IP 地址。伪装和 SNAT 都非常相似。不同之处是:伪装自动使用传出接口的 IP 地址。因此,如果传出接口使用了动态 IP 地址,则使用伪装。SNAT 将数据包的源 IP 地址设置为指定的 IP 地址,且不会动态查找传出接口的 IP 地址。因此,SNAT 要比伪装更快。如果传出接口使用了固定 IP 地址,则使用 SNAT。目标 NAT(DNAT)
使用此 NAT 类型将传入的流量路由到不同主机。例如,如果您的网页服务器使用预留 IP 范围内的 IP 地址,因此无法直接从互联网访问,您可以在路由器上设置 DNAT 规则来重定向进入该服务器的流量。
44.4.2. 使用 nftables 配置伪装
伪装使路由器动态地更改通过接口到接口 IP 地址发送的数据包的源 IP。这意味着,如果接口被分配了新的 IP,nftables 会在替换源 IP 时自动使用新的 IP。
以下流程描述了如何将通过 ens3 接口离开主机的数据包源 IP 替换为 ens3中设置的 IP。
流程
创建一个表:
xxxxxxxxxx# nft add table nat在表中添加
prerouting和postrouting链:xxxxxxxxxx# nft -- add chain nat prerouting { type nat hook prerouting priority -100 \; }# nft add chain nat postrouting { type nat hook postrouting priority 100 \; }重要
即使您没有向
prerouting链添加规则,nftables框架也要求此链与传入的数据包回复匹配。请注意,您必须将
--选项传递给nft命令,以避免 shell 将负优先级值解析为nft命令的选项。为
postrouting链添加与ens3接口传出数据包匹配的规则:xxxxxxxxxx# nft add rule nat postrouting oifname "ens3" masquerade
44.4.3. 使用 nftables 配置源 NAT
在路由器中,源 NAT(SNAT)可让您将通过接口发送的数据包 IP 改为专门的 IP 地址。
以下流程描述了如何通过 ens3 接口将路由器离开路由器的数据包源 IP 替换为 192.0.2.1。
流程
创建一个表:
xxxxxxxxxx# nft add table nat在表中添加
prerouting和postrouting链:xxxxxxxxxx# nft -- add chain nat prerouting { type nat hook prerouting priority -100 \; }# nft add chain nat postrouting { type nat hook postrouting priority 100 \; }重要
即使您没有向
postrouting链添加规则,nftables框架也要求此链与外发数据包回复匹配。请注意,您必须将
--选项传递给nft命令,以避免 shell 将负优先级值解析为nft命令的选项。为
postroutingchain 添加一条规则,将通过ens3的外向数据包的源 IP 替换为192.0.2.1。xxxxxxxxxx# nft add rule nat postrouting oifname "ens3" snat to 192.0.2.1
其它资源
44.4.4. 使用 nftables 配置目标 NAT
目标 NAT 可让您将路由器中的流量重新指向无法直接从互联网访问的主机。
以下流程描述了如何将发送到路由器的端口 80 和 443 的流量重定向到使用 192.0.2.1 IP 地址的主机。
流程
创建一个表:
xxxxxxxxxx# nft add table nat在表中添加
prerouting和postrouting链:xxxxxxxxxx# nft -- add chain nat prerouting { type nat hook prerouting priority -100 \; }# nft add chain nat postrouting { type nat hook postrouting priority 100 \; }重要
即使您没有向
postrouting链添加规则,nftables框架也要求此链与外发数据包回复匹配。请注意,您必须将
--选项传递给nft命令,以避免 shell 将负优先级值解析为nft命令的选项。为
preroutingchain 添加一条规则,它将发送到端口80和443的ens3接口上进入的流量重定向到使用192.0.2.1IP 的主机:xxxxxxxxxx# nft add rule nat prerouting iifname ens3 tcp dport { 80, 443 } dnat to 192.0.2.1根据您的环境,添加 SNAT 或伪装规则以更改源地址:
如果
ens3接口使用了动态 IP 地址,请添加伪装规则:xxxxxxxxxx# nft add rule nat postrouting oifname "ens3" masquerade如果
ens3接口使用静态 IP 地址,请添加 SNAT 规则。例如,如果ens3使用198.51.100.1IP 地址:xxxxxxxxxxnft add rule nat postrouting oifname "ens3" snat to 198.51.100.1
其它资源
44.5. 使用 nftables 命令中的设置
nftables 框架原生支持集合。您可以使用一个集合,例如,规则匹配多个 IP 地址、端口号、接口或其他匹配标准。
44.5.1. 在 nftables 中使用匿名集合
匿名集合包含使用逗号分开的值,比如 { 22, 80, 443 },它们直接在规则中使用。您还可以将匿名集合用于 IP 地址或其他匹配标准。
匿名集合的缺陷是,如果要更改集合,则需要替换规则。对于动态解决方案,请使用命名的集合,如 第 44.5.2 节 “在 nftables 中使用命名集” 所述。
先决条件
example_chain链和example_table表在inet系统中存在。
流程
例如,在
example_table的example_chain中添加一条规则,允许进入的流量进入端口22、80和443:xxxxxxxxxx# nft add rule inet example_table example_chain tcp dport { 22, 80, 443 } accept另外,还可在
example_table中显示所有链及其规则:xxxxxxxxxx# nft list table inet example_tabletable inet example_table {chain example_chain {type filter hook input priority filter; policy accept;tcp dport { ssh, http, https } accept}}
44.5.2. 在 nftables 中使用命名集
nftables 框架支持 mutable 命名集。命名集是一个列表或一组元素,您可以在表中的多个规则中使用。匿名集合的另外一个好处在于,您可以更新命名的集合而不必替换使用集合的规则。
当您创建一个命名集时,必须指定集合包含的元素类型。您可以设置以下类型:
- 对于包含 IPv4 地址或范围的集合的
ipv4_addr,如192.0.2.1或192.0.2.0/24。 - 对于包含 IPv6 地址或范围的
ipv6_addr(如2001:db8:1::1或2001:db8:1::1/64)的集合。 - 对于包含介质访问控制(MAC)地址列表集合的
ether_addr,如52:54:00:6b:66:42。 - 包含互联网协议类型列表集合的
inet_proto,如tcp。 - 包含互联网服务列表集合的
inet_service,如ssh。 - 包含数据包标记列表集合的
mark。数据包标记可以是任意 32 位整数值(0到2147483647]。
先决条件
example_chainchain 和example_table表存在。
流程
创建一个空集。以下示例为 IPv4 地址创建了一个集合:
要创建可存储多个独立 IPv4 地址的集合:
xxxxxxxxxx# nft add set inet example_table example_set { type ipv4_addr \; }要创建可存储 IPv4 地址范围的集合:
xxxxxxxxxx# nft add set inet example_table example_set { type ipv4_addr \; flags interval \; }
重要
要避免 shell 认为分号作为命令结尾,您必须用反斜杠转义分号。
另外,还可创建使用该集合的规则。例如,以下命令为
example_table的example_chain添加了一个规则,该规则将丢弃来自example_set中的 IPv4 地址的所有数据包。xxxxxxxxxx# nft add rule inet example_table example_chain ip saddr @example_set drop因为
example_set仍为空,所以该规则目前无效。为
example_set添加 IPv4 地址:如果您创建存储单个 IPv4 地址的集合,请输入:
xxxxxxxxxx# nft add element inet example_table example_set { 192.0.2.1, 192.0.2.2 }如果您创建存储 IPv4 范围的集合,请输入:
xxxxxxxxxx# nft add element inet example_table example_set { 192.0.2.0-192.0.2.255 }当您指定 IP 地址范围时,可以使用无类别域间路由(CIDR)标记,如上例中的
192.0.2.0/24。
44.5.3. 相关信息
- 有关集合的详情,请查看
Setsman page 中的nft(8)部分。
44.6. 在 nftables 命令中使用 verdict 映射
ver 字典映射(也称为字典)使 nft 通过映射匹配条件到操作来基于数据包信息执行操作。
44.6.1. 在 nftables 中使用字面映射
字面映射(literal map)是一个直接在规则中使用的 { *match_criteria* : *action* } 语句。这个语句可以包含多个用逗号分开的映射。
字面映射的缺陷在于,如果要更改映射,则必须替换规则。对于动态解析,使用如所述命名的 verdiction 映射 第 44.6.2 节 “在 nftables 中使用 mutable verdiction 映射”。
这个示例论述了如何使用字面映射将 IPv4 和 IPv6 协议的 TCP 和 UDP 数据包路由到不同的链以分别计数传入 TCP 和 UDP 数据包。
流程
创建
example_table:xxxxxxxxxx# nft add table inet example_table在
example_table中创建tcp_packets链:xxxxxxxxxx# nft add chain inet example_table tcp_packets为
tcp_packets添加一条计算此链中流量的规则:xxxxxxxxxx# nft add rule inet example_table tcp_packets counter在
example_table中创建udp_packets链xxxxxxxxxx# nft add chain inet example_table udp_packets为
udp_packets添加一条计算此链中流量的规则:xxxxxxxxxx# nft add rule inet example_table udp_packets counter为传入的流量创建一个链。例如,在
example_table中创建一个名为incoming_traffic的链,它会过滤传入的流量:xxxxxxxxxx# nft add chain inet example_table incoming_traffic { type filter hook input priority 0 \; }添加一个带有字面映射的规则
incoming_traffic。xxxxxxxxxx# nft add rule inet example_table incoming_traffic ip protocol vmap { tcp : jump tcp_packets, udp : jump udp_packets }字面映射可以区分数据包,并根据它们的协议将数据包发送到不同的计数链。
要列出流量计数器,显示
example_table:xxxxxxxxxx# nft list table inet example_tabletable inet example_table {chain tcp_packets {counter packets 36379 bytes 2103816}chain udp_packets {counter packets 10 bytes 1559}chain incoming_traffic {type filter hook input priority filter; policy accept;ip protocol vmap { tcp : jump tcp_packets, udp : jump udp_packets }}}tcp_packets和udp_packetschain 中的计数器会显示接收的数据包和字节数。
44.6.2. 在 nftables 中使用 mutable verdiction 映射
nftables 框架支持 mutable verdiction 映射。您可以在表中的多个规则中使用这些映射。字面映射的另一个优点是,您可以更新可更改的映射而不替换使用该映射的规则。
当您创建 mutable verdiction map 时,您必须指定元素类型
- 对于匹配部分包含 IPv4 地址的映射的
ipv4_addr,比如192.0.2.1。 - 对于匹配部分包含 IPv6 地址的映射的
ipv6_addr,比如2001:db8:1::1。 - 对于匹配部分包含介质访问控制(MAC)地址的映射的
ether_addr,比如52:54:00:6b:66:42。 - 对于匹配部分包含互联网协议类型的映射的
inet_proto,比如tcp。 - 对于匹配部分包含互联网服务名称端口号的映射的
inet_service,比如ssh或者22。 - 对于匹配部分包含数据包标记的映射的
mark。数据包标记可以是任意正 32 位整数值(0到2147483647。 - 对于匹配部分包含计数器值的映射的
counter。计数器值可以是任意正 64 位整数值。 - 对于部分匹配包含配额值的映射的
quota。配额值可以是任意正 64 位整数值。
这个示例论述了如何根据源 IP 地址允许或丢弃传入的数据包。使用可变平均字典映射,当 IP 地址和操作是动态存储在映射中时,您只需要一条规则就可以配置这个场景。此流程还描述了如何从映射中添加和删除条目。
流程
创建表。例如,要创建一个名为
example_table的表,用于处理 IPv4 数据包:xxxxxxxxxx# nft add table ip example_table创建链。例如,要在
example_table中创建一个名为example_chain的链:xxxxxxxxxx# nft add chain ip example_table example_chain { type filter hook input priority 0 \; }重要
要避免 shell 认为分号作为命令结尾,您必须用反斜杠转义分号。
创建一个空的映射。例如,要为 IPv4 地址创建映射:
xxxxxxxxxx# nft add map ip example_table example_map { type ipv4_addr : verdict \; }创建使用该映射的规则。例如,以下命令为
example_table的example_chain中添加了一个规则,它被应用于example_map中定义的 IPv4 地址的操作:xxxxxxxxxx# nft add rule example_table example_chain ip saddr vmap @example_map为
example_map添加 IPv4 地址和对应操作:xxxxxxxxxx# nft add element ip example_table example_map { 192.0.2.1 : accept, 192.0.2.2 : drop }这个示例定义了 IPv4 地址到操作的映射。根据以上规则,防火墙接受来自
192.0.2.1的数据包并丢弃来自192.0.2.2的数据包。另外,还可添加另一个 IP 地址和 action 语句来增强映射:
xxxxxxxxxx# nft add element ip example_table example_map { 192.0.2.3 : accept }(可选)从映射中删除条目:
xxxxxxxxxx# nft delete element ip example_table example_map { 192.0.2.1 }另外,还可显示规则集:
xxxxxxxxxx# nft list rulesettable ip example_table {map example_map {type ipv4_addr : verdictelements = { 192.0.2.2 : drop, 192.0.2.3 : accept }}chain example_chain {type filter hook input priority filter; policy accept;ip saddr vmap @example_map}}
44.6.3. 相关信息
- 有关验证映射的详情,请查看
Mapsman page 中的nft(8)部分。
44.7. 使用 nftables 配置端口转发
端口转发可让管理员将发送到特定目的端口的数据包转发到不同的本地或者远程端口。
例如:如果您的网页服务器没有公共 IP 地址,您可以在防火墙中设置端口转发规则,该规则可在防火墙 80 和 443 将传入的数据包转发到网页服务器。使用这个防火墙规则,互联网中的用户可以使用防火墙的 IP 或主机名访问网页服务器。
44.7.1. 将传入的数据包转发到不同的本地端口
这部分论述了如何在端口 8022 中转发进入的 IPv4 数据包到本地系统的端口 22 的示例。
流程
使用
ip地址系列创建一个名为nat的表:xxxxxxxxxx# nft add table ip nat在表中添加
prerouting和postrouting链:xxxxxxxxxx# nft -- add chain ip nat prerouting { type nat hook prerouting priority -100 \; }注意
将
--选项传递给nft命令,以避免 shell 将负优先级值解析为nft命令的选项。为
prerouting链添加一条规则,将端口8022中传入的数据包重新指向本地端口22:xxxxxxxxxx# nft add rule ip nat prerouting tcp dport 8022 redirect to :22
44.7.2. 将特定本地端口上传入的数据包转发到不同主机
您可以使用目标网络地址转换(DNAT)规则将本地端口上传入的数据包转发到远程主机。这可让互联网中的用户访问使用专用 IP 地址在主机上运行的服务。
这个步骤描述了如何在本地端口 443 中转发传入的 IPv4 数据包到使用 192.0.2.1 IP 地址的远程系统中的同一端口号。
先决条件
- 您以
root用户身份登录登陆到应该转发数据包的系统。
流程
使用
ip地址系列创建一个名为nat的表:xxxxxxxxxx# nft add table ip nat在表中添加
prerouting和postrouting链:xxxxxxxxxx# nft -- add chain ip nat prerouting { type nat hook prerouting priority -100 \; }# nft add chain ip nat postrouting { type nat hook postrouting priority 100 \; }注意
将
--选项传递给nft命令,以避免 shell 将负优先级值解析为nft命令的选项。为
prerouting链添加一条规则,该规则将端口443中传入的数据包重新指向192.0.2.1上的同一端口:xxxxxxxxxx# nft add rule ip nat prerouting tcp dport 443 dnat to 192.0.2.1为
postrouting链添加一条规则伪装出站流量:xxxxxxxxxx# nft add rule ip daddr 192.0.2.1 masquerade启用数据包转发:
xxxxxxxxxx# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf# sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
44.8. 使用 nftables 来限制连接数量
您可以使用 nftables 来限制连接数量或阻止试图建立给定数量的连接以防止使用太多系统资源。
44.8.1. 使用 nftables 限制连接数量
ct count 实用程序中的 nft 参数可让管理员限制连接数量。这个步骤描述了如何限制进入的连接的基本示例。
先决条件
- 存在
example_table中的基础example_chain。
流程
添加一条规则,该规则只允许从 IPv4 地址同时连接到 SSH 端口(22),并从同一 IP 拒绝所有后续连接:
xxxxxxxxxx# nft add rule ip example_table example_chain tcp dport ssh meter example_meter { ip saddr ct count over 2 } counter reject另外,还可以显示上一步中创建的 meter:
xxxxxxxxxx# nft list meter ip example_table example_metertable ip example_table {meter example_meter {type ipv4_addrsize 65535elements = { 192.0.2.1 : ct count over 2 , 192.0.2.2 : ct count over 2 }}}elements条目显示目前与该规则匹配的地址。在这个示例中,elements列出了已连接到 SSH 端口的 IP 地址。请注意,输出不会显示活跃连接的数量,或者连接是否被拒绝。
44.8.2. 在一分钟内阻止尝试十个新进入 TCP 连接的 IP 地址
nftables 框架可让管理员动态更新设置。本节解释了如何使用这个功能临时阻止在一分钟内建立十个 IPv4 TCP 连接的主机。五分钟后,nftables 会自动从黑名单中删除 IP 地址。
流程
使用
ip地址系列创建filter表:xxxxxxxxxx# nft add table ip filter将
input链添加到filter表:xxxxxxxxxx# nft add chain ip filter input { type filter hook input priority 0 \; }在
filter表中添加名为blacklist的集合:xxxxxxxxxx# nft add set ip filter blacklist { type ipv4_addr \; flags dynamic, timeout \; timeout 5m \; }这个命令为 IPv4 地址创建动态设置。
timeout 5m参数定义nftables在 5 分钟后自动删除条目。添加一条规则,将在一分钟内试图建立十个新的 TCP 连接的主机源 IP 地址添加到
blacklist集:xxxxxxxxxx# nft add rule ip filter input ip protocol tcp ct state new, untracked limit rate over 10/minute add @blacklist { ip saddr }添加一条规则,丢弃来自在
blacklist集中列出的 IP 地址的所有连接:xxxxxxxxxx# nft add rule ip filter input ip saddr @blacklist drop
其它资源
44.9. 调试 nftables 规则
nftables 框架为管理员提供了不同的选项来调试规则,并在数据包匹配时提供不同的选项。本节描述了这些选项。
44.9.1. 创建带有计数器的规则
在识别规则是否匹配时,可以使用计数器。本节描述了如何创建带有计数器的新规则。
有关在现有规则中添加计数器的步骤,请参阅 第 44.9.2 节 “在现有规则中添加计数器”。
先决条件
- 您要添加该规则的链已存在。
流程
在链中添加使用
counter参数的新规则。以下示例添加一个带有计数器的规则,它允许端口 22 上的 TCP 流量,并计算与这个规则匹配的数据包和网络数据的数量:xxxxxxxxxx# nft add rule inet example_table example_chain tcp dport 22 counter accept显示计数器值:
xxxxxxxxxx# nft list rulesettable inet example_table {chain example_chain {type filter hook input priority filter; policy accept;tcp dport ssh counter packets 6872 bytes 105448565 accept}}
44.9.2. 在现有规则中添加计数器
在识别规则是否匹配时,可以使用计数器。本节论述了如何在现有规则中添加计数器。
有关使用计数器添加新规则的步骤,请参阅 第 44.9.1 节 “创建带有计数器的规则”。
先决条件
- 您要添加计数器的规则已存在。
流程
在链中显示规则及其句柄:
xxxxxxxxxx# nft --handle list chain inet example_table example_chaintable inet example_table {chain example_chain { # handle 1type filter hook input priority filter; policy accept;tcp dport ssh accept # handle 4}}通过替换规则而不是使用
counter参数来添加计数器。以下示例替换了上一步中显示的规则并添加计数器:xxxxxxxxxx# nft replace rule inet example_table example_chain handle 4 tcp dport 22 counter accept显示计数器值:
xxxxxxxxxx# nft list rulesettable inet example_table {chain example_chain {type filter hook input priority filter; policy accept;tcp dport ssh counter packets 6872 bytes 105448565 accept}}
44.9.3. 监控与现有规则匹配的数据包
nftables 中的追踪功能与 nft monitor 命令相结合,可让管理员显示与规则匹配的数据包。该流程描述了如何为规则启用追踪以及与本规则匹配的监控数据包。
先决条件
- 您要添加计数器的规则已存在。
流程
在链中显示规则及其句柄:
xxxxxxxxxx# nft --handle list chain inet example_table example_chaintable inet example_table {chain example_chain { # handle 1type filter hook input priority filter; policy accept;tcp dport ssh accept # handle 4}}通过替换规则而不是使用
meta nftrace set 1参数来添加追踪功能。以下示例替换了上一步中显示的规则并启用追踪:xxxxxxxxxx# nft replace rule inet example_table example_chain handle 4 tcp dport 22 meta nftrace set 1 accept使用
nft monitor命令显示追踪。以下示例过滤命令的输出,仅显示包含inet example_table example_chain的条目:xxxxxxxxxx# nft monitor | grep "inet example_table example_chain"trace id 3c5eb15e inet example_table example_chain packet: iif "enp1s0" ether saddr 52:54:00:17:ff:e4 ether daddr 52:54:00:72:2f:6e ip saddr 192.0.2.1 ip daddr 192.0.2.2 ip dscp cs0 ip ecn not-ect ip ttl 64 ip id 49710 ip protocol tcp ip length 60 tcp sport 56728 tcp dport ssh tcp flags == syn tcp window 64240trace id 3c5eb15e inet example_table example_chain rule tcp dport ssh nftrace set 1 accept (verdict accept)...警告
根据启用追踪的规则数量以及匹配的流量数量,
nft monitor命令可能会产生大量输出。使用grep或者其他实用程序过滤输出。
44.10. 备份和恢复 nftables 规则集
这部分论述了如何将 nftables 规则备份到文件,以及从文件中恢复规则。
管理员可以使用具有规则的文件将规则传送到不同的服务器。
44.10.1. 将 nftables 规则设置为一个文件
本节论述了如何将 nftables 规则集备份到文件。
流程
备份
nftables规则:nft list ruleset格式:xxxxxxxxxx# nft list ruleset > file.nftJSON 格式:
xxxxxxxxxx# nft -j list ruleset > file.json
44.10.2. 从文件恢复 nftables 规则集
本节论述了如何恢复 nftables 规则集。
流程
恢复
nftables规则:如果要恢复的文件为
nft list ruleset格式或包含nft命令:xxxxxxxxxx# nft -f file.nft如果要恢复的文件采用 JSON 格式:
xxxxxxxxxx# nft -j -f file.json
44.11. 相关信息
- 在 Red Hat Enterprise Linux 8 中使用 nftables博客页面提供了使用
nftables功能的概述。 - What comes after iptables?Its successor, of course: nftables 文章解释了为什么用
nftables替换iptables。 - Firewalld: The Future is nftables 提供了关于使用
nftables替换firewalld作为默认后端的信息。
第 45 章 使用 xdp-filter 进行高性能流量过滤以防止 DDoS 攻击
与数据包过滤器(如 nftables)相比,Express Data Path(XDP)在网络接口上处理并丢弃网络数据包。因此,XDP 在到达防火墙或其他应用程序前决定了软件包的下一步。因此,XDP 过滤器需要较少的资源,并可处理比传统数据包过滤器更高的网络数据包,从而防止分布式服务(DDoS)攻击。例如,在测试过程中,红帽在单一内核中每秒丢弃了两千六百万(26 million)网络数据包,这比同一硬件中 nftables 的丢弃率要高得多。
xdp-filter 实用程序允许或丢弃使用 XDP 进入的网络数据包。您可以创建规则来过滤与特定对象或特定命令的流量:
- IP 地址
- MAC 地址
- 端口
请注意,即使 xdp-filter 的数据包处理率要高得多,它并没有和 nftables 相同的功能。xdp-filter 是一个概念性的工具,用来演示使用 XDP 进行数据包过滤。另外,您可以使用工具代码来更好地了解如何编写您自己的 XDP 应用程序。
重要
红帽提供 xdp-filter 工具,作为一个不受支持的技术预览。
45.1. 释放与 xdp-filter 规则匹配的网络数据包
这部分论述了如何使用 xdp-filter 丢弃网络数据包:
- 到特定目的地端口
- 从一个指定的 IP 地址
- 从一个指定的 MAC 地址
xdp-filter 的 allow 策略定义允许所有流量,过滤器只丢弃与特定规则匹配的网络数据包。例如,如果您知道要丢弃的数据包的源 IP 地址,请使用这个方法。
先决条件
- 已安装
xdp-tools软件包。 - 支持 XDP 程序的网络驱动程序。
流程
加载
xdp-filter来处理特定接口上传入的数据包,如enp1s0:xxxxxxxxxx# xdp-filter load enp1s0默认情况下,
xdp-filter使用allow策略,实用程序只丢弃与任何规则匹配的流量。另外,使用
-f *feature*选项只启用特定功能,如tcp、ipv4或ethernet。只载入所需功能而不是全部都提高了软件包处理的速度。要启用多个功能,使用逗号分隔它们。如果该命令出错,则网络驱动程序不支持 XDP 程序。
添加规则来丢弃与它们匹配的数据包。例如:
要将传入的数据包放到端口
22,请输入:xxxxxxxxxx# xdp-filter port 22这个命令添加一个匹配 TCP 和 UDP 流量的规则。要只匹配特定的协议,使用
-p *protocol*选项。要丢弃来自
192.0.2.1的数据包,输入:xxxxxxxxxx# xdp-filter ip 192.0.2.1 -m src请注意,
xdp-filter不支持 IP 范围。要丢弃来自 MAC 地址
00:53:00:AA:07:BE的数据包,请输入:xxxxxxxxxx# xdp-filter ether 00:53:00:AA:07:BE -m src
验证步骤
使用以下命令显示丢弃和允许的数据包统计信息:
xxxxxxxxxx# xdp-filter status
其它资源
- 有关
xdp-filter的详情,请查看xdp-filter(8)man page。 - 如果您是开发人员,并且您对
xdp-filter代码有兴趣,请从红帽客户门户网站下载并安装相应的源 RPM(SRPM)。
45.2. 丢弃所有与 xdp-filter 规则匹配的网络数据包
这部分论述了如何使用 xdp-filter 来只允许网络伪装:
- 来自和到一个特定目的地端口
- 来自和到一个特定 IP 地址
- 来自和到特定的 MAC 地址
要做到这一点,使用 xdp-filter 的 deny 策略来定义该过滤器丢弃所有的网络数据包,但与特定规则匹配的除外。例如,如果您不知道要丢弃的数据包的源 IP 地址,请使用这个方法。
警告
如果您在一个接口上加载 xdp-filter 时将默认策略设置为 deny,则内核会立即从这个接口丢弃所有数据包,直到您创建允许某些流量的规则。要避免从系统中锁定,在本地输入命令或者通过不同的网络接口连接到主机。
先决条件
- 已安装
xdp-tools软件包。 - 您登录到本地主机,或使用您不计划过滤流量的网络接口。
- 支持 XDP 程序的网络驱动程序。
流程
加载
xdp-filter来处理特定接口上的数据包,如enp1s0:xxxxxxxxxx# xdp-filter load enp1s0 -p deny另外,使用
-f *feature*选项只启用特定功能,如tcp、ipv4或ethernet。只载入所需功能而不是全部都提高了软件包处理的速度。要启用多个功能,使用逗号分隔它们。如果该命令出错,则网络驱动程序不支持 XDP 程序。
添加规则以允许匹配它们的数据包。例如:
要允许来自和端口
22的数据包,请输入:xxxxxxxxxx# xdp-filter port 22这个命令添加一个匹配 TCP 和 UDP 流量的规则。要只匹配特定的协议,将
-p *protocol*选项传递给命令。要允许来自和
192.0.2.1的数据包,请输入:xxxxxxxxxx# xdp-filter ip 192.0.2.1请注意,
xdp-filter不支持 IP 范围。要允许来自和到 MAC 地址
00:53:00:AA:07:BE的数据包,请输入:xxxxxxxxxx# xdp-filter ether 00:53:00:AA:07:BE
重要
xdp-filter实用程序不支持有状态数据包检查。这要求您不使用-m *mode*选项设置模式,或者您添加显式规则以允许机器接收的接收流量响应。
验证步骤
使用以下命令显示丢弃和允许的数据包统计信息:
xxxxxxxxxx# xdp-filter status
其它资源
- 有关
xdp-filter的详情,请查看xdp-filter(8)man page。 - 如果您是开发人员,并且您对
xdp-filter代码有兴趣,请从红帽客户门户网站下载并安装相应的源 RPM(SRPM)。
第 46 章 DPDK 入门
Data Plane Development Kit(DPDK)提供库和网络驱动来加快用户空间中的软件包处理速度。
管理员使用 DPDK,例如,在虚拟机中使用单一根 I/O 虚拟化(SR-IOV)来减少延迟并增加 I/O 吞吐量。
注意
红帽不支持实验性的 DPDK API。
46.1. 安装 dpdk 软件包
这部分论述了如何安装 dpdk 软件包。
先决条件
- 安装了红帽企业版 Linux。
- 为主机分配了有效的订阅。
流程
使用
yum实用程序安装dpdk软件包:xxxxxxxxxx# yum install dpdk
46.2. 相关信息
- 有关在 Red Hat Enterprise Linux 8 上支持 SR-IOV 的网络适配器列表,请参考网络适配器 Fast Datapath 功能支持列表。
第 47 章 了解 RHEL 中的 eBPF 网络功能
扩展的 Berkeley Packet 过滤器(eBPF)是一个内核中的虚拟机,允许在内核空间中执行代码。此代码运行在一个受限的沙箱环境中,仅可访问有限功能集。
在网络中,您可以使用 eBPF 来补充或替换内核数据包处理。根据您使用的 hook,eBPF 程序有:
- 对元数据的读和写的访问权限
- 可以查找套接字和路由
- 可以设置套接字选项
- 可以重定向数据包
47.1. RHEL 中网络 eBPF 功能概述
您可以将扩展的 Berkeley Paket Filter(eBPF)联网程序附加到 RHEL 中的以下 hook:
- eXpress Data Path (XDP):在内核联网堆栈处理之前提供对接收的数据包的早期访问。
tc带有 direct-action 标志的 eBPF 类器:在入口和出口上提供强大的数据包处理。- Control Groups version 2 (cgroup v2):启用过滤并覆盖控制组群中程序执行的基于套接字的操作。
- 套接字过滤:启用对从套接字接收的数据包进行过滤。这个功能也可用于经典 Berkeley Packet Filter(cBPF),但已扩展为支持 eBPF 程序。
- 流解析器:启用将流分成单独的消息、过滤并将其重定向到套接字。
SO_REUSEPORT套接字选择:提供可从reuseport套接字组接收套接字的可编程选择。- Flow dissector:启用内核在某些情况下解析数据包标头的方式。
- TCP 阻塞控制回调:启用实现自定义 TCP 阻塞控制算法。
- 带有封装的路由: 允许创建自定义隧道封装。
请注意,红帽并不支持 RHEL 中的所有 eBPF 功能,如下所述。如需了解更多与每个 hook 相关的信息,请参阅 RHEL 8 发行注记和以下概述。
XDP
您可以将 BPF_PROG_TYPE_XDP 类型的程序附加到网络接口。然后,在内核网络堆栈开始处理之前,内核会在接收的数据包上执行该程序。这在某些情况下允许快速数据包转发,如实现快速数据包丢弃,以防止分布式服务(DDoS)攻击,并为负载平衡场景快速数据包重定向。
您还可以使用 XDP 进行不同类型的数据包监控和抽样。内核允许 XDP 程序修改数据包,并将其传送到内核网络堆栈进行进一步处理。
以下的 XDP 模式可用:
- Native (driver) XDP:内核在数据包接收时从最早的点执行该程序。目前,内核无法解析数据包,因此无法使用内核提供的元数据。这个模式要求网络接口驱动程序支持 XDP,但并非所有驱动程序都支持这种原生模式。
- 通用 XDP:内核网络栈在进程早期执行 XDP 程序。此时内核数据结构已被分配,数据包已被预先处理。如果数据包被丢弃或重定向,与原生模式相比,这需要大量开销。但是,通用模式不需要支持网络接口驱动,它可适用于所有网络接口。
- Offloaded XDP:内核在网络接口而不是主机 CPU 上执行 XDP 程序。请注意,这需要特定的硬件,这个模式中只有某些 eBPF 功能可用。
在 RHEL 上,使用 libxdp 库载入所有 XDP 程序。这个程序库启用系统控制的 XDP 使用。
注意
目前,XDP 程序有一些系统配置限制。例如:您必须禁用接收接口中某些硬件卸载功能。另外,并非所有功能都可用于支持原生模式的所有驱动程序。
在 RHEL 8.3 中,红帽仅在满足以下条件时支持 XDP 功能:
- 您可以在 AMD 或者 Intel 64 位构架中载入 XDP 程序。
- 用
libxdp库来把程序加载到内核中。 - XDP 程序使用以下返回代码之一:
XDP_ABORTED、XDP_DROP或XDP_PASS。 - XDP 程序不使用 XDP 硬件卸载。
另外,红帽还提供以下使用 XDP 功能作为不受支持的技术预览:
- 在 AMD 和 Intel 64 位以外的构架中载入 XDP 程序。请注意:
libxdp库不适用于 AMD 和 Intel 64 位以外的构架。 XDP_TX和XDP_REDIRECT返回代码。- XDP 硬件卸载。
AF_XDP
使用过滤并将数据包重定向到给定 AF_XDP 套接字的 XDP 程序,您可以使用 AF_XDP 协议系列中的一个或者多个套接字快速从内核复制到用户空间。
在 RHEL 8.3 中,红帽将这个功能作为不受支持的技术预览提供。
流量控制
流量控制(tc)子系统提供以下 eBPF 程序类型:
BPF_PROG_TYPE_SCHED_CLSBPF_PROG_TYPE_SCHED_ACT
这些类型允许您在 eBPF 中编写自定义 tc 分类器和 tc 操作。这与 tc 生态系统的部分一起,提供了强大的数据包处理能力,也是一些容器联网编配解决方案的核心部分。
在大多数情况下,只有类符被使用,与 direct-action 标记一样,eBPF 分类器可以直接从同一 eBPF 程序执行操作。clsact Queueing Discipline(qdisc)已设计在入口端启用此功能。
请注意,使用一个流 Unsector eBPF 程序可能会影响其他 qdiscs 和 tc 类器(如 flower)的操作。
RHEL 8.2 及更新的版本完全支持 tc 功能的 eBPF。
套接字过滤器
一些实用程序会使用或在过去使用了 classic Berkeley Packet Filter(cBPF)过滤套接字上接收到的数据包。例如,tcpdump 实用程序允许用户指定表达式,tcpdump 然后会把它转换为 cBPF 代码。
作为 cBPF 的替代方案,内核允许 BPF_PROG_TYPE_SOCKET_FILTER 类型的 eBPF 程序达到同样目的。
在 RHEL 8.3 中,红帽将这个功能作为不受支持的技术预览提供。
控制组群
在 RHEL 中,您可以使用多种 eBPF 程序,供您附加到 cgroup。当给定 cgroup 中的某个程序执行某个操作时,内核会执行这些程序。请注意,您只能使用 cgroups 版本 2。
RHEL 中提供以下与网络相关的 cgroup eBPF 程序:
BPF_PROG_TYPE_SOCK_OPS:内核在 TCPconnect中调用该程序,并允许在每个套接字设置 TCP 操作。BPF_PROG_TYPE_CGROUP_SOCK_ADDR:内核在connect、bind、sendto和recvmsg操作中调用该程序。该程序允许更改 IP 地址和端口。BPF_PROG_TYPE_CGROUP_SOCKOPT:内核在setsockopt和getsockopt操作中调用这个程序并允许修改选项。BPF_PROG_TYPE_CGROUP_SOCK:内核在套接字创建和绑定到地址时调用这个程序。您可以使用这些程序来允许或拒绝操作,或者只检查套接字创建统计信息。BPF_PROG_TYPE_CGROUP_SKB:此程序在入口和出口中过滤独立的数据包,并可以接受或拒绝数据包。BPF_PROG_TYPE_CGROUP_SYSCTL:该程序允许过滤系统控制(sysctl)的访问。
在 RHEL 8.3 中,红帽将这个功能作为不受支持的技术预览提供。
流解析器(Stream Parser)
流解析器在添加到特殊 eBPF 映射的一组套接字上运行。然后 eBPF 程序处理内核接收的数据包或者在那些套接字上发送。
RHEL 中提供了以下流解析程序 eBPF 程序:
BPF_PROG_TYPE_SK_SKB:eBPF 程序将从套接字接收的数据包解析到单个消息中,并指示内核丢弃这些信息,或者将其发送到组中的另一套接字。BPF_PROG_TYPE_SK_MSG:此程序过滤出口信息。eBPF 程序将数据包解析到单个信息中,并批准或拒绝它们。
在 RHEL 8.3 中,红帽将这个功能作为不受支持的技术预览提供。
SO_REUSEPORT 套接字选择
使用这个套接字选项,您可以绑定多个套接字到相同的 IP 地址和端口。如果没有 eBPF,内核会根据连接散列选择接收套接字。使用 BPF_PROG_TYPE_SK_REUSEPORT 程序,选择接收套接字可以完全被编程。
在 RHEL 8.3 中,红帽将这个功能作为不受支持的技术预览提供。
dissector 流程
当内核需要在不处理全部协议解码的情况下处理数据包标头时,就会出现 dissected。例如:这会在 tc 子系统、多路径路由、绑定或者计算数据包散列时发生。在这种情况下,内核解析数据包的标头,并使用数据包标头中的信息填充内部结构。您可以使用 BPF_PROG_TYPE_FLOW_DISSECTOR 程序替换这个内部解析。请注意,您只能在 RHEL 的 eBPF 的 IPv4 和 IPv6 上分离 TCP 和 UDP。
在 RHEL 8.3 中,红帽将这个功能作为不受支持的技术预览提供。
TCP 阻塞控制
您可以使用实现了 struct tcp_congestion_oops 回调的 BPF_PROG_TYPE_STRUCT_OPS 程序中的一个自定义 TCP 阻塞控制算法编写自定义 TCP 阻塞控制算法。采用这种方式的算法在系统中和内置的内核算法一起可用。
在 RHEL 8.3 中,红帽将这个功能作为不受支持的技术预览提供。
带有封装的路由
您可以将以下 eBPF 程序类型之一附加到路由表中作为隧道封装属性的路由:
BPF_PROG_TYPE_LWT_INBPF_PROG_TYPE_LWT_OUTBPF_PROG_TYPE_LWT_XMIT
这样的 eBPF 程序的功能仅限于特定的隧道配置,它不允许创建通用封装或封装解决方案。
在 RHEL 8.3 中,红帽将这个功能作为不受支持的技术预览提供。
第 48 章 使用 BPF 编译器集合进行网络追踪
本节介绍 BPF Compiler Collection(BCC)是什么,如何安装 BCC,以及如何使用 bcc-tools 软件包提供的预创建脚本执行不同的网络追踪操作。所有这些脚本均支持 --ebpf 参数显示实用程序上传到内核的 eBPF 代码。您可以使用这些代码了解更多有关编写 eBPF 脚本的信息。
48.1. BCC 介绍
BPF Compiler Collection(BCC)是一个库,可帮助创建扩展的 Berkeley Packet Filter(eBPF)程序。eBPF 程序的主要工具是在不需要额外的开销或存在安全问题的情况下,分析操作系统性能和网络性能。
BCC 不再需要用户了解 eBPF 的技术详情,并提供了许多开箱即用的功能,如带有预创建的 eBPF 程序的 bcc-tools 软件包。
注意
eBPF 程序在事件中触发,如磁盘 I/O、TCP 连接以及进程创建。程序不太可能导致内核崩溃、循环或者变得无响应,因为它们在内核的安全性虚拟机中运行。
48.2. 安装 bcc-tools 软件包
本节论述了如何安装 bcc-tools 软件包,该软件包还会将 BPF Compiler Collection(BCC)库作为依赖性安装。
先决条件
- 有效的 Red Hat Enterprise Linux 订阅
- 包含
bcc-tools软件包的 已用软件仓库 - 更新的内核
- root 权限。
流程
安装
bcc-tools:xxxxxxxxxx# yum install bcc-toolsBCC 工具安装在
/usr/share/bcc/tools/目录中。另外,检查工具:
xxxxxxxxxx# ll /usr/share/bcc/tools/...-rwxr-xr-x. 1 root root 4198 Dec 14 17:53 dcsnoop-rwxr-xr-x. 1 root root 3931 Dec 14 17:53 dcstat-rwxr-xr-x. 1 root root 20040 Dec 14 17:53 deadlock_detector-rw-r--r--. 1 root root 7105 Dec 14 17:53 deadlock_detector.cdrwxr-xr-x. 3 root root 8192 Mar 11 10:28 doc-rwxr-xr-x. 1 root root 7588 Dec 14 17:53 execsnoop-rwxr-xr-x. 1 root root 6373 Dec 14 17:53 ext4dist-rwxr-xr-x. 1 root root 10401 Dec 14 17:53 ext4slower...上面列表中的
doc目录包括了每个工具的文档。
48.3. 显示添加到内核的接受队列中的 TCP 连接
内核在 TCP 3 通道握手中接收 ACK 数据包后,内核会在连接的状态变为 ESTABLISHED后,将连接从 SYN 队列移到 accept 队列。因此,只有成功的 TCP 连接才能在此队列中看到。
tcpaccept 实用程序使用 eBPF 功能显示所有内核添加到 accept 队列的连接。这个程序是轻量级的,因为它跟踪了内核的 accept() 功能,而不是捕获数据包并过滤它们。例如:一般故障排除请使用 tcpaccept 来显示服务器接受的新连接。
流程
输入以下命令启动追踪内核
accept队列:xxxxxxxxxx# /usr/share/bcc/tools/tcpacceptPID COMM IP RADDR RPORT LADDR LPORT843 sshd 4 192.0.2.17 50598 192.0.2.1 221107 ns-slapd 4 198.51.100.6 38772 192.0.2.1 3891107 ns-slapd 4 203.0.113.85 38774 192.0.2.1 389...每次内核接受连接时,
tcpaccept显示连接详情。按 Ctrl+C 停止追踪过程。
其它资源
- 详情请查看
tcpaccept(8)man page。 - 有关
tcpaccept和示例的详情,请查看/usr/share/bcc/tools/doc/tcpaccept_example.txt文件。 - 要显示 eBPF 脚本
tcpaccept8)上传到内核,请使用/usr/share/bcc/tools/tcpaccept --ebpf命令。
48.4. 追踪传出 TCP 连接尝试
tcpconnect 实用程序使用 eBPF 功能跟踪 TCP 连接尝试。该工具的输出还包括失败的连接。
tcpconnect 程序是轻量级的,因为它跟踪了内核的 connect() 函数,而不是捕获数据包并过滤它们。
流程
输入以下命令启动显示所有传出连接的追踪过程:
xxxxxxxxxx# /usr/share/bcc/tools/tcpconnectPID COMM IP SADDR DADDR DPORT31346 curl 4 192.0.2.1 198.51.100.16 8031348 telnet 4 192.0.2.1 203.0.113.231 2331361 isc-worker00 4 192.0.2.1 192.0.2.254 53...每次内核处理传出连接时,
tcpconnect会显示连接详情。按 Ctrl+C 停止追踪过程。
其它资源
- 详情请查看
tcpconnect(8)man page。 - 有关
tcpconnect和示例的详情,请查看/usr/share/bcc/tools/doc/tcpconnect_example.txt文件。 - 要显示 eBPF 脚本
tcpconnect(8)上传到内核,请使用/usr/share/bcc/tools/tcpconnect --ebpf命令。
48.5. 测量出站 TCP 连接的延迟
TCP 连接延迟是建立连接所需的时间。这通常涉及内核 TCP/IP 处理和网络往返时间,而不是应用程序运行时。
tcpconnlat 工具使用 eBPF 功能来测量发送的 SYN 数据包和接收的响应数据包之间的时间。
流程
开始测量出站连接的延迟:
xxxxxxxxxx# /usr/share/bcc/tools/tcpconnlatPID COMM IP SADDR DADDR DPORT LAT(ms)32151 isc-worker00 4 192.0.2.1 192.0.2.254 53 0.6032155 ssh 4 192.0.2.1 203.0.113.190 22 26.3432319 curl 4 192.0.2.1 198.51.100.59 443 188.96...每次内核处理传出连接时,
tcpconnlat会在内核接收响应数据包后显示连接详情。按 Ctrl+C 停止追踪过程。
其它资源
- 详情请查看
tcpconnlat(8)man page。 - 有关
tcpconnlat和示例的详情,请查看/usr/share/bcc/tools/doc/tcpconnlat_example.txt文件。 - 要显示 eBPF 脚本
tcpconnlat(8)上传到内核,请使用/usr/share/bcc/tools/tcpconnlat --ebpf命令。
48.6. 显示被内核丢弃的 TCP 数据包和片段详情
tcpdrop 工具可让管理员显示内核丢弃的 TCP 数据包和片段详情。使用这个实用程序调试丢弃数据包的高速率,以便远程系统发送基于计时器的重新传输。释放数据包和片段的高速率可能会影响服务器的性能。
tcpdrop 实用程序使用 eBPF 功能直接从内核检索信息,而不是捕获和过滤数据包。
流程
输入以下命令来显示丢弃 TCP 数据包和片段详情:
xxxxxxxxxx# /usr/share/bcc/tools/tcpdropTIME PID IP SADDR:SPORT > DADDR:DPORT STATE (FLAGS)13:28:39 32253 4 192.0.2.85:51616 > 192.0.2.1:22 CLOSE_WAIT (FIN|ACK)b'tcp_drop+0x1'b'tcp_data_queue+0x2b9'...13:28:39 1 4 192.0.2.85:51616 > 192.0.2.1:22 CLOSE (ACK)b'tcp_drop+0x1'b'tcp_rcv_state_process+0xe2'...每次内核丢弃 TCP 数据包和网段时,
tcpdrop会显示连接的详情,包括导致丢弃软件包的内核堆栈追踪。按 Ctrl+C 停止追踪过程。
其它资源
- 详情请查看
tcpdrop(8)man page。 - 有关
tcpdrop和示例的详情,请查看/usr/share/bcc/tools/doc/tcpdrop_example.txt文件。 - 要显示 eBPF 脚本
tcpdrop(8)上传到内核,请使用/usr/share/bcc/tools/tcpdrop --ebpf命令。
48.7. 追踪 TCP 会话
tcplife 实用程序使用 eBPF 跟踪打开和关闭的 TCP 会话,并输出一行总结信息。管理员可以使用 tcplife 来识别连接以及传输的流量数量。
本节中的示例论述了如何显示连接到端口 22(SSH)来检索以下信息:
- 本地进程 ID(PID)
- 本地进程名称
- 本地 IP 地址和端口号
- 远程 IP 地址和端口号
- 接收和传输的流量的数量(以 KB 为单位)。
- 连接处于活跃状态的时间(毫秒)
流程
输入以下命令开始追踪到本地端口
22的连接:xxxxxxxxxx/usr/share/bcc/tools/tcplife -L 22PID COMM LADDR LPORT RADDR RPORT TX_KB RX_KB MS19392 sshd 192.0.2.1 22 192.0.2.17 43892 53 52 6681.9519431 sshd 192.0.2.1 22 192.0.2.245 43902 81 249381 7585.0919487 sshd 192.0.2.1 22 192.0.2.121 43970 6998 7 16740.35...每次连接关闭时,
tcplife会显示连接详情。按 Ctrl+C 停止追踪过程。
其它资源
- 详情请查看
tcplife(8)man page。 - 有关
tcplife和示例的详情,请查看/usr/share/bcc/tools/doc/tcplife_example.txt文件。 - 要显示 eBPF 脚本
tcplife(8)上传到内核,请使用/usr/share/bcc/tools/tcplife --ebpf命令。
48.8. 追踪 TCP 重新传输
tcpretrans 工具显示 TCP 重传输的详情,如本地和远程 IP 地址和端口号,以及重新传输时的 TCP 状态。
该工具使用 eBPF 功能,因此开销非常低。
流程
使用以下命令来显示 TCP 重新传输详情:
xxxxxxxxxx# /usr/share/bcc/tools/tcpretransTIME PID IP LADDR:LPORT T> RADDR:RPORT STATE00:23:02 0 4 192.0.2.1:22 R> 198.51.100.0:26788 ESTABLISHED00:23:02 0 4 192.0.2.1:22 R> 198.51.100.0:26788 ESTABLISHED00:45:43 0 4 192.0.2.1:22 R> 198.51.100.0:17634 ESTABLISHED...每当内核调用 TCP 重新传输功能时,
tcpretrans就会显示连接详情。按 Ctrl+C 停止追踪过程。
其它资源
- 详情请查看
tcpretrans(8)man page。 - 有关
tcpretrans和示例的详情,请查看/usr/share/bcc/tools/doc/tcpretrans_example.txt文件。 - 要显示 eBPF 脚本
tcpretrans(8)上传到内核,请使用/usr/share/bcc/tools/tcpretrans --ebpf命令。
48.9. 显示 TCP 状态更改信息
在 TCP 会话中,TCP 状态会改变。tcpstates 工具使用 eBPF 功能跟踪这些状态更改,并打印包括每个状态持续时间的详细信息。例如:使用 tcpstates 来确定连接是否在初始化状态花费了太多时间。
流程
使用以下命令开始追踪 TCP 状态更改:
xxxxxxxxxx# /usr/share/bcc/tools/tcpstatesSKADDR C-PID C-COMM LADDR LPORT RADDR RPORT OLDSTATE -> NEWSTATE MSffff9cd377b3af80 0 swapper/1 0.0.0.0 22 0.0.0.0 0 LISTEN -> SYN_RECV 0.000ffff9cd377b3af80 0 swapper/1 192.0.2.1 22 192.0.2.45 53152 SYN_RECV -> ESTABLISHED 0.067ffff9cd377b3af80 818 sssd_nss 192.0.2.1 22 192.0.2.45 53152 ESTABLISHED -> CLOSE_WAIT 65636.773ffff9cd377b3af80 1432 sshd 192.0.2.1 22 192.0.2.45 53152 CLOSE_WAIT -> LAST_ACK 24.409ffff9cd377b3af80 1267 pulseaudio 192.0.2.1 22 192.0.2.45 53152 LAST_ACK -> CLOSE 0.376...每次连接改变其状态时,
tcpstates会显示一个新的行,其中包含更新的连接详情。如果多个连接同时更改其状态,使用第一列(
SKADDR)中的套接字地址来确定哪些条目属于同一连接。按 Ctrl+C 停止追踪过程。
其它资源
- 详情请查看
tcpstates(8)man page。 - 有关
tcpstates和示例的详情,请查看/usr/share/bcc/tools/doc/tcpstates_example.txt文件。 - 要显示 eBPF 脚本
tcpstates(8)上传到内核,请使用/usr/share/bcc/tools/tcpstates --ebpf命令。
48.10. 聚合发送到特定子网的 TCP 流量
tcpsubnet 实用程序总结了并聚合本地主机发送到子网的 IPv4 TCP 流量,并显示在一个固定的时间段内的输出。该工具使用 eBPF 功能来收集并总结数据,以减少开销。
默认情况下,tcpsubnet 总结了以下子网的流量:
127.0.0.1/3210.0.0.0/8172.16.0.0/12192.0.2.0/24/160.0.0.0/0
请注意,最后一个子网(0.0.0.0/0)会捕获所有(catch-all)数据。tcpsubnet 实用程序计算与这个 catch-all 条目中前 4 个不同的子网的所有流量。
按照以下步骤计算 192.0.2.0/24 和 198.51.100.0/24 子网的流量。所有子网的流量都会在 0.0.0.0/0 catch-all 子网条目中跟踪。
流程
开始监控发送到
192.0.2.0/24、198.51.100.0/24和其他子网的流量数量:xxxxxxxxxx# /usr/share/bcc/tools/tcpsubnet 192.0.2.0/24,198.51.100.0/24,0.0.0.0/0Tracing... Output every 1 secs. Hit Ctrl-C to end[02/21/20 10:04:50]192.0.2.0/24 856198.51.100.0/24 7467[02/21/20 10:04:51]192.0.2.0/24 1200198.51.100.0/24 87630.0.0.0/0 673...这个命令以字节为单位显示指定子网每秒一次的流量。
按 Ctrl+C 停止追踪过程。
其它资源
- 详情请查看
tcpsubnet(8)man page。 - 有关
tcpsubnet和示例的详情,请查看/usr/share/bcc/tools/doc/tcpsubnet.txt文件。 - 要显示 eBPF 脚本
tcpsubnet(8)上传到内核,请使用/usr/share/bcc/tools/tcpsubnet --ebpf命令。
48.11. 通过 IP 地址和端口显示网络吞吐量
tcptop 程序以 KB 为单位显示主机发送并接收的 TCP 流量。这个报告会自动刷新并只包含活跃的 TCP 连接。该工具使用 eBPF 功能,因此开销非常低。
流程
要监控发送和接收的流量,请输入:
xxxxxxxxxx# /usr/share/bcc/tools/tcptop13:46:29 loadavg: 0.10 0.03 0.01 1/215 3875PID COMM LADDR RADDR RX_KB TX_KB3853 3853 192.0.2.1:22 192.0.2.165:41838 32 1026261285 sshd 192.0.2.1:22 192.0.2.45:39240 0 0...命令的输出只包括活跃的 TCP 连接。如果本地或者远程系统关闭了连接,则该连接在输出中不再可见。
按 Ctrl+C 停止追踪过程。
其它资源
- 详情请查看
tcptop(8)man page。 - 有关
tcptop和示例的详情,请查看/usr/share/bcc/tools/doc/tcptop.txt文件。 - 要显示 eBPF 脚本
tcptop(8)上传到内核,请使用/usr/share/bcc/tools/tcptop --ebpf命令。
48.12. 追踪已建立的 TCP 连接
tcptracer 工具跟踪连接、接受和关闭 TCP 连接的内核功能。该工具使用 eBPF 功能,因此开销非常低。
流程
使用以下命令启动追踪过程:
xxxxxxxxxx# /usr/share/bcc/tools/tcptracerTracing TCP established connections. Ctrl-C to end.T PID COMM IP SADDR DADDR SPORT DPORTA 1088 ns-slapd 4 192.0.2.153 192.0.2.1 0 65535A 845 sshd 4 192.0.2.1 192.0.2.67 22 42302X 4502 sshd 4 192.0.2.1 192.0.2.67 22 42302...每当内核连接、接受、或关闭连接时,
tcptracer会显示连接详情。按 Ctrl+C 停止追踪过程。
其它资源
- 详情请查看
tcptracer(8)man page。 - 有关
tcptracer和示例的详情,请查看/usr/share/bcc/tools/doc/tcptracer_example.txt文件。 - 要显示 eBPF 脚本
tcptracer(8)上传到内核,请使用/usr/share/bcc/tools/tcptracer --ebpf命令。
48.13. 追踪 IPv4 和 IPv6 侦听尝试
solisten 实用程序跟踪所有 IPv4 和 IPv6 侦听尝试。它跟踪监听尝试,包括最终失败或者不接受连接的监听程序。当程序要侦听 TCP 连接时,程序会追踪内核调用的功能。
流程
输入以下命令启动显示所有监听 TCP 尝试的追踪过程:
xxxxxxxxxx# /usr/share/bcc/tools/solistenPID COMM PROTO BACKLOG PORT ADDR3643 nc TCPv4 1 4242 0.0.0.03659 nc TCPv6 1 4242 2001:db8:1::14221 redis-server TCPv6 128 6379 ::4221 redis-server TCPv4 128 6379 0.0.0.0....按 Ctrl+C 停止追踪过程。
其它资源
- 详情请查看
solistenman page。 - 有关
solisten和示例的详情,请查看/usr/share/bcc/tools/doc/solisten_example.txt文件。 - 要显示 eBPF 脚本
solisten上传到内核,请使用/usr/share/bcc/tools/solisten --ebpf命令。
48.14. 软中断的服务时间概述
softirqs 程序总结了服务软中断(soft IRQ)花费的时间,并将此时间显示为总发行版或者直方形分布。这个工具使用 irq:softirq_enter 和 irq:softirq_exit 内核追踪点,这是一个稳定的追踪机制。
流程
输入以下命令启动追踪
soft irq事件时间:xxxxxxxxxx# /usr/share/bcc/tools/softirqsTracing soft irq event time... Hit Ctrl-C to end.^CSOFTIRQ TOTAL_usecstasklet 166block 9152net_rx 12829rcu 53140sched 182360timer 306256按 Ctrl+C 停止追踪过程。
其它资源
- 详情请查看
softirqsman page。 - 有关
softirqs和示例的详情,请查看/usr/share/bcc/tools/doc/softirqs_example.txt文件。 - 要显示 eBPF 脚本
solisten上传到内核,请使用/usr/share/bcc/tools/softirqs --ebpf命令。 - 有关
mpstat如何使用此信息的详情,请查看mpstat(1)man page。
48.15. 其它资源
- 有关 BCC 的详情,请查看
/usr/share/doc/bcc/README.md文件。
第 49 章 TIPC 入门
透明进程间通信(TIPC),也称为 Cluster Domain Sockets,用于群集范围的操作的进程间通信(IPC)服务。
在高可用性和动态集群环境中运行的应用程序有特殊需要。集群中的节点数量可能会有所不同,路由器可能会失败,且出于负载均衡的考虑,功能也可以移到集群中的不同节点。TIPC 可最大程度降低应用程序开发人员处理此类问题的工作,并尽可能以正确和最佳的方式处理它们。另外,TIPC 比一般协议(如 TCP)提供效率更高且容错的通讯。
49.1. TIPC 的构架
TIPC 是使用 TIPC 和数据包传输服务(bearer)的应用程序之间的一层,跨越传输层、网络和信号链路层。然而,TIPC 可以使用不同的传输协议作为 bearer,这样 TCP 连接就可以充当 TIPC 信号连接的 bearer。
TIPC 支持以下 bearer:
- Ethernet
- Infiniband
- UDP 协议
TIPC 提供了在 TIPC 端口间可靠传送信息,这是所有 TIPC 通讯的端点。
以下是 TIPC 构架图:
49.2. 系统引导时载入 tipc 模块
在您使用 TIPC 协议前,载入 tipc 内核模块。本节介绍如何在系统引导时配置 RHEL 自动载入这个模块。
流程
使用以下内容创建
/etc/modules-load.d/tipc.conf文件:xxxxxxxxxxtipc重启
systemd-modules-load服务在不重启系统的情况下载入该模块:xxxxxxxxxx# systemctl start systemd-modules-load
验证步骤
使用以下命令验证 RHEL 是否已载入
tipc模块:xxxxxxxxxx# lsmod | grep tipctipc 311296 0如果命令没有显示
tipc模块的条目,RHEL 无法加载它。
其它资源
- 有关系统引导时载入模块的详情,请参考
modules-load.d(5)man page。
49.3. 创建 TIPC 网络
这部分论述了如何创建 TIPC 网络。
重要
这些命令只临时配置 TIPC 网络。要在节点上永久配置 TIPC,在脚本中使用此流程的命令,并将 RHEL 配置为在系统引导时执行该脚本。
先决条件
- 已载入
tipc模块。详情请查看 第 49.2 节 “系统引导时载入 tipc 模块”
流程
可选:设置一个唯一的节点身份,如 UUID 或节点的主机名:
xxxxxxxxxx# tipc node set identity host_name身份可以是任何由最多 16 个字母和数字组成的唯一字符串。
添加 bearer。例如:要将以太网用作介质,并将
enp0s1设备用作物理 bearer 设备,请输入:xxxxxxxxxx# tipc bearer enable media eth device enp1s0可选: 要获得冗余和更好的性能,请使用上一步中的命令附加更多 bearer。您可以配置最多三个 bearer,但在同一介质上不能超过两个。
在应该加入 TIPC 网络的每个节点中重复前面的所有步骤。
验证步骤
显示集群成员的链接状态:
xxxxxxxxxx# tipc link listbroadcast-link: up5254006b74be:enp1s0-525400df55d1:enp1s0: up此输出显示,节点
5254006b74be上的 bearerenp1s0和节点525400df55d1的 bearerenp1s0之间的链接是up。显示 TIPC 发布表:
xxxxxxxxxx# tipc nametable showType Lower Upper Scope Port Node0 1795222054 1795222054 cluster 0 5254006b74be0 3741353223 3741353223 cluster 0 525400df55d11 1 1 node 2399405586 5254006b74be2 3741353223 3741353223 node 0 5254006b74be- 有两个服务类型为
0的条目表示两个节点是这个集群的成员。 - 服务类型为
1的条目代表内置拓扑服务跟踪服务。 - 服务类型为
2的条目显示在发布节点中看到的链接。范围限制3741353223代表 peer 端点的地址(基于节点身份的唯一 32 位哈希值),以十进制格式表示。
- 有两个服务类型为
其它资源
- 有关您可以使用的其它 bearer 以及对应的命令行参数的详情,请查看
tipc-bearer(8)man page。 - 有关
tipc namespace命令的详情请参考tipc-namespace(8)man page。
49.4. 其它资源
红帽建议使用其他 bearer 级别协议来根据传输介质加密节点之间的通信。例如:
- MACsec:详情请查看 第 32 章 配置 MACsec。
- IPsec:详情请参考
Securing networks指南中的使用 IPsec 配置 VPN 部分。
有关如何使用 TIPC 的示例,请使用
git clone git://git.code.sf.net/p/tipc/tipcutils命令克隆上游 GIT 存储库。该仓库包含使用 TIPC 功能的演示和测试程序的源代码。请注意,这个软件仓库不是由红帽提供的。有关 TIPC 协议的详情请参考 http://tipc.io/protocol.html。
有关 TIPC 编程的详情请参考 http://tipc.io/protocol.html。
法律通告
Copyright © 2020 Red Hat, Inc.
The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version.
Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law.
Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of Joyent. Red Hat is not formally related to or endorsed by the official Joyent Node.js open source or commercial project.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation's permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.
为了尽快向用户提供最新的信息,本文档可能会包括由机器自动从英文原文翻译的内容。如需更多信息,请参阅此说明。