| Storage System - 存取与性能 |
| 过程中转或输出持久化 |

常见存储子系统性能问题现象
- 业务感知性能慢
- 对比测试发现不同的设备的性能差距大
- 服务器设备的性能与应用软件、中间件基础软件、硬件等强相关。应用软件、中间件基础软件、硬件的一些细微差别,可能造成应用层面、软件测试层面的性能表现不一致。
介绍服务器存储子系统的基本概念,指导服务器存储子系统性能问题的定位定界,通过固化操作步骤和经验积累来提升问题的定位处理效率。
分析排查思路
业务感知性能慢问题的总体分析思路
在分析系统性能慢之前,必须首先做好如下准备:
- 熟悉整个系统的架构与业务特性
- 知道性能问题发生的现象与触发条件
- 熟练掌握各模块的性能监控工具
分析系统性能慢,主要思路在于找出性能瓶颈。
性能瓶颈分析可以按如下过程进行:
- 全面收集性能数据:按业务处理流程,对性能瓶颈发生前后系统各模块的性能数据进行分析对比,重点关注硬件资源是否出现性能瓶颈。
- 从架构到模块逐层分析:以各模块请求处理时间、请求队列深度、数据传输带宽、及发生瓶颈前后性能数据的最大差异点为判断依据,找出对性能影响最大的模块,然后深入其内部子模块进行分析,找出系统性能短板。
- 深入模块分析:分析工作向系统性能短板的上下游环节扩展,找出引发性能短板最直接的原因。
系统的性能是往往由系统中出现短板的环节决定的,性能短板更多表现在硬件资源上,特别是CPU、内存资源和传输通道。但短板环节并不一定是造成性能瓶颈的元凶, 系统业务流程上的处理机制,已经为短板的出现埋下了伏笔。性能瓶颈的出现往往是由系统架构和软件设计决定的。
如下图所示,逻辑模块为业务系统中的软件部分,而硬件资源为业务系统中的硬件部分。当用户请求下发时,业务系统按至上而下的顺序由各逻辑模块对IO请求进行响应和处理。硬件资源为各逻辑模块的正常工作提供支持。一旦逻辑模块在设计和配置上不合理,会直接引起硬件资源衰竭、响应缓慢或受到限制,导致性能问题的出现。在性能调优时,我们需要在明确性能需求的前提下,以系统IO流程为线索,确定具体哪种硬件资源成为瓶颈,是由什么原因导致的,再结合逻辑模块的设计与配置进行优化。
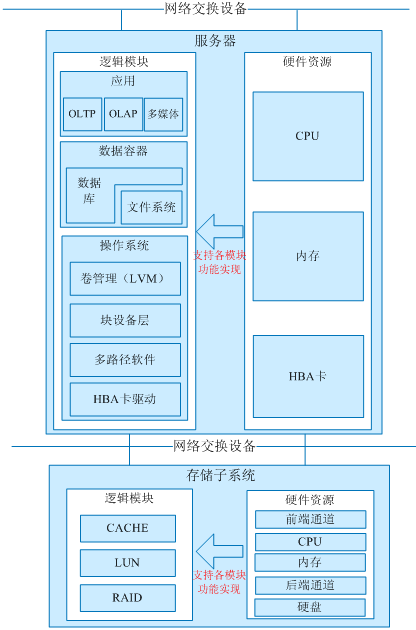
系统中硬件资源包括CPU、内存、磁盘、服务器前后端网络通道、存储设备前后段网络通道。对于CPU、内存、磁盘硬件资源来说,性能瓶颈分析主要关注资源利用率和相互争用状况。对于网络通道来说,主要关注通道带宽占用情况和I/O并发状况。
对比测试性能差距大问题的总体分析思路
针对这一类问题,详细对比不同的测试环境之间的差异:
部件 |
配置/参数 |
说明 |
|---|---|---|
CPU |
X86 or ARM |
如果CPU架构不一致,则无可比性 |
2P or 4P |
如果CPU个数不一致,则无可比性 |
|
主频 |
- |
|
Core数量 |
- |
|
L2 Cache |
- |
|
内存 |
8DIMM/12DIMM/16DIMM |
如果内存个数和通道不一致,则无可比性 |
容量 |
- |
|
工作频率 |
- |
|
BIOS配置 |
C state |
- |
P state |
- |
|
Turbo Mode |
- |
|
T-state |
调节T-state即调节占空比,占空比是指单位时间内CPU Clock On /(Clock On + Clock Off)的时间(也即Clock On工作占整个CPU工作时间的占空比),影响系统的功耗和温度。 |
|
POR+1/POR+2 |
- |
|
NUMA |
- |
|
TPH |
TPH(TLP Processor Hints)特性允许将PCIE请求的数据放到LLC中做数据预取。TLP的发送端可以使用TPH信息,通知接收端即将访问数据的特性,以便接收端合理地预读和管理数据,以提升访问速率,减少到内存读取数据的延时。TPH可覆盖DCA(Direct Cache Access)特性功能。 |
|
CurrentLimit |
该配置会限制电流大小,影响性能。 |
|
Page Policy |
影响内存访问时延 |
|
DDIO(Intel Data Direct I/O Technology) |
该特性允许PCIe EP直接将数据写到L3 cache。这个特性可以降低CPU core从PCIe获取数据的延迟。这个特性也允许PCIe直接直接从L3 cache获取数据,Intel建议默认是使能该特性,并且不允许修改。 |
|
SDDC/ADDDC |
SDDC指内存在单颗粒发生多bit错误时的数据纠错校正能力。 SDDC一旦使能后,SDDC功能不需要软件参与。Device Tagging指当某个RANK上的颗粒发生故障后,使用奇偶校验颗粒替换故障颗粒。发生替换后,该Rank将失去颗粒纠错能力(仍然有1bit错误纠正能力)。 ADDDC就是加强版的SDDC,SDDC只有一颗奇偶颗粒可以用来替换故障颗粒,而ADDDC则除了奇偶颗粒外还有单独的一颗备份颗粒。 RAS特性使能时,芯片运行指令时会增加一些逻辑算法进行校验,对性能会有稍微影响。 |
|
QPI COD |
选项用于选择处理器和QPI总线使用的监测模式。更改此选项会影响内存性能。 |
|
QPI Early Snoop |
选项用于选择处理器和QPI总线使用的监测模式。更改此选项会影响内存性能。 |
|
Clock Spread Spectrum |
影响CPU及PCIE设备的工作频率。 |
|
Power Policy |
这个选项是一个联动开关,修改该选项会导致多个能耗设置联动修改。 |
|
Monitor/Mwait |
该测试场景还会和P State有关系,静态turbo功能将PSS表注释掉,OS无法自动调频,该功能修改也会导致和mwait一样的现象; 说明:
vmware系统和linux系统不同,mwait不能关闭,电源管理策略较特殊,关闭后会导致集群无法加入。 |
|
EIST Support |
- |
|
Turbo Mode |
- |
|
Hyper-Threading |
- |
|
Isoc |
Isoc选项打开可以提高数据传输的可靠行,但是会占用内存带宽,降低内存性能。 |
|
RAPL |
开启RAPL时,如果内存功耗过大,会触发功耗限制功能,导致内存性能下降。 |
|
Core Prefetchers –>DCU IP |
- |
|
Core Prefetchers –>DCU Streamer |
- |
|
Core Prefetchers –>MLC Spatial |
- |
|
Core Prefetchers –>MLC Streamer |
- |
|
LLC prefetcher |
- |
|
X2APIC |
x2APIC关闭,比使能时虚拟化性能测试降低9% |
|
UFS(Uncore Frequency Scaling) |
影响CPU功耗和性能 |
|
OSB(Opportunistic Snoop Broadcast) |
影响CPU Cache一致性效率 |
|
D2K/D2C(direct-to-kti/direct-to-core) |
用于快速提供数据给UPI Port和Core,而不必将数据返回给CHA,减少时延。 D2K/D2C模式下,针对多Socket系统,DIR一定要使能,不然是非法的 |
|
SNC(Sub-NUMA Cluster) |
SNC 功能改善了访问 LLC 和内存数据的时延; SNC 取代了 V3、 V4 CPU 的 COD( Cluster On Die)功能,使能 SNC时,一个物理 CPU 可以模拟成两个 NUMA 节点。在多 socket 系统里面,所有的 SNC Cluster 都分配到单独的 NUMA 域。并不是所有的 Skylake-SP CPU 都支持 SNC 功能,只有当 LLCs 大于等于 12(即 LLC大于等于 16.5MB)的 CPU 才支持此功能, LLCs=LLC / 1.375MB。SNC 功能需要 IMC Interleaving 功能一起使用,当使能 SNC 功能时, IMC Interleaving 需要设置为 1-way,当关闭 SNC 功能时, IMC Interleaving 需要设置为 2-way。 |
|
DEMT |
DEMT是华为自研的调频技术,使OS处于低频率高占用率的状态,对SPEC Power这种测试能效比的情况会有所改善。 |
|
VTx/VTd/SRIOV |
在一些虚拟化场景下的性能测试,这三个选项均要求打开; 在非虚拟化场景下,如果有一些高性能、低延迟的测试,建议虚拟化关闭,降低硬件指令实行的路径 |
|
SAS HBA卡(PCIE—SAS/SATA) |
上行带宽(X4/X8/X16 PCIE2.0/3.0/4.0) |
- |
下行带宽(8 port/16 port) |
- |
|
Pdcache是否使能 |
打开时,性能更好 |
|
RAID卡 |
上行带宽(X4/X8/X16 PCIE2.0/3.0/4.0) |
- |
下行带宽(8 port/16 port) |
- |
|
是否有Cache |
针对机械盘场景,有Cache会提升读写性能 |
|
Cache容量大小 |
针对机械盘的小块随机写/小文件读写场景有较大影响 |
|
Cache是否使能(WB/WT/RA/NORA) |
针对机械盘场景,有Cache会提升读写性能 |
|
Cache Bypass是否使能 |
对特定场景的性能会产生影响 |
|
Pdcache是否使能 |
打开时,性能更好 |
|
perf mode(least latency/max iops) |
对特定场景的性能会产生影响 |
|
Stripe size(64K/128K/256K/512K/1M) |
对特定场景的性能会产生影响 |
|
背板 |
是否有Expander |
针对SSD场景有较大影响,有Expander时性能会下降。 |
HDD |
厂家型号 |
不同厂家型号的硬盘性能不一样 |
接口(SAS/SATA 6G/12G) |
接口需保持一致 |
|
碟片转速 |
碟片转速越快,性能越好 |
|
是否有Media Cache |
如果有Media Cache,随机写性能会相对较好 |
|
Media Cache代次 |
Media Cache不同代次对性能的影响不一致 |
|
是否有NAND Flash做写缓存 |
如果有NAND Flash做写缓存,则会提升写性能 |
|
是否有DRAM Cache |
打开了DRAM Cache,会提升写性能 |
|
DRAM Cache是否使能 |
打开了DRAM Cache,会提升写性能 |
|
固件版本 |
不同的固件版本,可能会表现出不一样的性能 |
|
SSD |
厂家型号 |
不同厂家型号的硬盘性能不一样 |
接口(SAS/SATA 6G/12G PCIE2.0/3.0/4.0) |
接口需保持一致 |
|
颗粒类型 |
颗粒类型不一致,会影响延时us级别 |
|
容量大小 |
容量不同,会影响性能 |
|
OP(Over provision)大小 |
影响随机写性能 |
|
Write Cache是否使能 |
Write Cache使能之后可以提升写性能 |
|
空盘状态/脏盘状态 |
空盘状态下写性能较好;脏盘状态下存在GC、稳态与非稳态等会影响性能。 |
上述硬件配置/参数不一致的,需先确保一致。在硬件配置/参数一致后,如果性能仍然差距较大的,则重点排查OS/测试工具,可以重新安装OS、部署测试工具,确保OS和测试工具一致。
存储子系统架构
下图通过一次磁盘 write 操作的过程(假设文件已经被从磁盘中读入了 page cache 中)来概述存储子系统的工作原理。
- 用户进程通过 write() 系统调用发起写请求
- 内核更新对应的 page cache
- pdflush 内核线程将 page cache 写入至磁盘中
- 文件系统层将每一个 block buffer 存放为一个 bio 结构体,并向块设备层提交一个写请求
- 块设备层从上层接受到请求,执行 IO 调度操作,并将请求放入IO 请求队列中
- 设备驱动(如 SCSI 或RAID卡驱动)完成写操作
- 磁盘设备固件执行对应的硬件操作,如磁盘的旋转,寻道等,数据被写入到磁盘扇区中
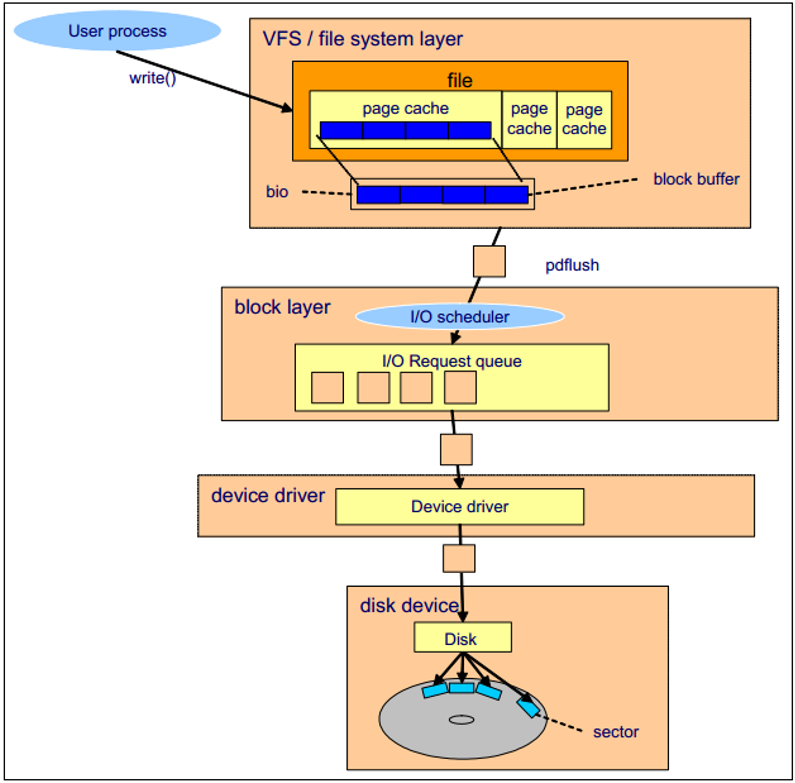
Block Layer
Block layer 处理所有和块设备相关的操作。block layer 最关键的是 bio 结构体。bio 结构体是 file system layer 到 block layer 的接口。 当执行一个写操作时,文件系统层将数据写入 page cache(由 block buffer 组成),将连续的块放到一起,组成 bio 结构体,然后将 bio 送至 block layer。
block layer 处理 bio 请求,并将这些请求链接成一个队列,称作 IO 请求队列,这个连接的操作就称作 IO 调度。
IO scheduler
IO 调度器的总体目标是减少磁盘的寻道时间(因此调度器都是针对机械硬盘进行优化的),IO 调度器通过两种方式来减少磁盘寻道:合并和排序。
合并即当两个或多个 IO 请求的是相邻的磁盘扇区,那么就将这些请求合并为一个请求。通过合并请求,多个 IO 请求只需要向磁盘发送一个请求指令,减少了磁盘的开销。
排序就是将不能合并的 IO 请求,根据请求磁盘扇区的顺序,在请求队列中进行排序,使得磁头可以按照磁盘的旋转顺序的完成 IO 操作,可以减小磁盘的寻道次数。
存储介质类型
接口类型
- SATA
- SAS
- NVMe
SATA
SATA的全称是Serial ATA,即串行传输ATA。相对于PATA模式的IDE接口来说,SATA是用串行线路传输数据,但是指令集不变,仍然是ATA指令集。SATA以它串行的数据发送方式得名。在数据传输的过程中,数据线和信号线独立使用,并且传输的时钟频率保持独立,因此同以往的PATA相比,SATA的传输速率可以达到并行的30倍。可以说SATA技术并不是简单意义上的PATA技术的改进,而是一种全新总线架构。
SATA以连续串行的方式传送数据,可以在较少的位宽下使用较高的工作频率来提高数据传输的带宽。SATA一次只会传送1位数据,这样能减少SATA接口的针脚数目,使连接电缆数目变少,效率也会更高。实际上,SATA 仅用四支针脚就能完成所有的工作,分别用于连接电缆、连接地线、发送数据和接收数据,同时这样的架构还能降低系统能耗和减小系统复杂性。
SATA是一种物理接口类型,执行的AHCI协议标准,是目前最为廉价和常见的硬盘接口,缺点便是有着6Gbps的极限读写限制,无法满足专业领域对于无延时、极致读写的要求。
SAS
SAS(Serial Attached SCSI)即串行SCSI技术,是一种磁盘连接技术,它综合了并行SCSI和串行连接技术(如FC、SSA、IEEE1394等)的优势,以串行通讯协议为协议基础架构,采用SCSI-3扩展指令集,并兼容SATA设备,是多层次的存储设备连接协议栈。
SAS的接口技术可以向下兼容SATA。具体来说,二者的兼容性主要体现在物理层和协议层的兼容。在物理层,SAS接口和SATA接口完全兼容,SATA硬盘可以直接使用在SAS的环境中,从接口标准上而言,SATA是SAS的一个子标准,因此SAS控制器可以直接操控SATA硬盘,但是SAS却不能直接使用在SATA的环境中,因为SATA控制器并不能对SAS硬盘进行控制;在协议层,SAS由3种类型协议组成,根据连接的不同设备使用相应的协议进行数据传输。其中串行SCSI协议(SSP)用于传输SCSI命令;SCSI管理协议(SMP)用于对连接设备的维护和管理;SATA通道协议(STP)用于SAS和SATA之间数据的传输。因此在这3种协议的配合下,SAS可以和SATA以及部分SCSI设备无缝结合。
SAS系统的背板(Backplane)既可以连接具有双端口、高性能的SAS驱动器,也可以连接高容量、低成本的SATA驱动器。所以SAS驱动器和SATA驱动器可以同时存在于一个存储系统之中。但需要注意的是,SATA系统并不兼容SAS,所以SAS驱动器不能连接到SATA背板上。由于SAS系统的兼容性,使用户能够运用不同接口的硬盘来满足各类应用在容量上或效能上的需求,因此在扩充存储系统时拥有更多的弹性,让存储设备发挥最大的投资效益。
NVMe
NVMe是一种基于非易失性存储器的传输规范,NVMe规范由包含90多家公司在内的工作小组所定制,Intel是主要领头人,小组成员包括美光、戴尔、三星、Marvell、NetAPP、EMC、IDT等公司。
此规范目的在于充分利用PCI-E通道的低延时以及并行性,还有当代处理器、平台与应用的并行性,在可控制的存储成本下,极大的提升固态硬盘的读写性能,降低由于AHCI接口带来的高延时,彻底解放SATA时代固态硬盘的极致性能。
就存储整个流程来说,NVMe不仅仅是逻辑上的协议接口,还是一种指令标准,一种指定协议,它的出现彻底颠覆了存储行业长期以来以ATA为核心底层的存储逻辑,掀起了一场实至名归的存储革命。
PCIe实际上是通道协议,在物理表现上就是主板上的PCIe接口。这些通道协议,属于总线协议,能够直接连接CPU,因而几乎没有延时,成为NVMe标准的绝佳伴侣。而在AHCI标准时代,受制于协议,几乎无法发挥PCIe的实际性能,同时根据传输速度不同,PCIe还可分为X2/X4/X8。、
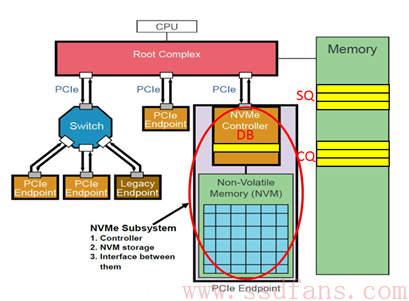
NVMe是一种Host与SSD之间通讯的协议,它在协议栈中隶属高层,NVMe在协议栈中处于应用层或者命令层。NVME的命令交由PCIe去完成,NVME与PCIe配合发挥出很好的性能。
NVMe制定了Host与SSD之间通讯的命令,以及命令如何执行的。NVMe有两种命令,一种叫Admin Command,用于Host管理和控制SSD;另外一种就是I/O Command,用于Host和SSD之间数据的传输。
NVMe协议中有三个主要部分:Submission Queue(SQ),Completion Queue(CQ)和Doorbell Register(DB)。SQ和CQ位于Host的内存中,DB则位于SSD的控制器内部。如下图所示:
介质类型
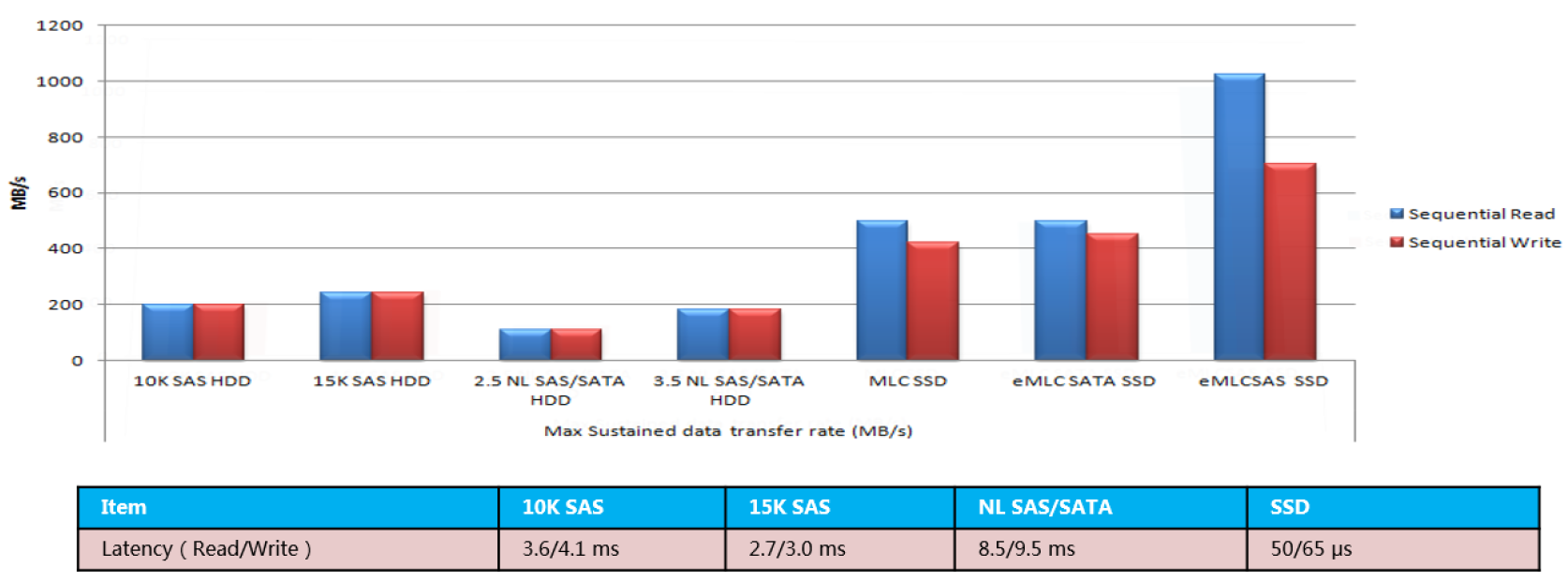
不同类型的磁盘介质,性能表现不同。可以概括为HDD转速越高,性能越好延迟越低;SSD的延迟远低于HDD。在低延迟和随机访问的应用场景下,SSD更适合。
HDD
机械硬盘利用特定的磁粒子的极性来记录数据,读操作时磁头将磁粒子的不同极性转换成不同的电脉冲信号,写操作则相反。
硬盘中还有一个存储缓冲区(write cache),这是为了协调硬盘与硬盘控制器在数据处理速度上的差异而设的。下图为机械硬盘的物理结构图。

磁盘从逻辑上被划分为磁道、柱面和扇区。每个盘片的每面都有一个读写磁头,磁头起初停在着陆区。
在最外圈,离主轴最远的地方是0磁道,磁盘数据的存放是从最外圈开始的。0磁道存放着用于操作系统启动所必须的程序代码。
磁盘在格式化时被划分为许多同心圆,这些同心圆的轨道叫做磁道。磁道从最外圈向内圈从0开始编号。磁道上的每段圆弧叫做一个扇区,扇区从1开始编号,扇区是磁盘读写的最小单位。划分磁道和扇区的过程,叫做低级格式化,通常在磁盘出厂的时候就已经格式化完毕了。数据的读写按照柱面进行,即磁头读写数据时首先在同一柱面内从0磁头开始操作。数据的读写按照柱面进行,而不是按照盘面进行。

机械磁盘扇区
Gap:用于标识不同扇区间隔。
Sync Mark:用于标识扇区数据区的开始。
Address Mark:用于标识数据的扇区号及位置。
Data:扇区可用的数据区。
ECC:错误检测及恢复代码,用于检测和恢复读写数据过程中产生的错误。
传统磁盘的扇区大小是512B,磁盘的高级格式使用4K作为扇区的大小,增大扇区可以提高空间的利用率。同时,因为操作系统的Page、文件系统的Block一般都是4KB大小,所以将扇区容量与上层的单位匹配,可以大大提高效率。需要注意:分区的开始位置和结束位置需要与4KB扇区的起始边界对齐,也就是说在分配分区扇区数时,必须是8的倍数。
影响HDD硬盘的性能主要有以下因素:
- 转速:转速是影响硬盘顺序IO时吞吐量性能的首要因素。转速越快,数据传输时间就越短。在连续IO情况下,磁头寻道次数少,转速就成了首要影响因素了。
- 寻道速度:寻道速度是影响磁盘随机IO性能的首要因素,随机IO时,磁盘更换磁道频繁,传输数据的时间和换道所消耗的时间根本不在一个数量级。
- 单盘容量:单盘容量越大,相同空间内存储的数据量就越大,也就是数据很密集,在相同的转速和寻道条件下,单盘容量大的会读出更多的数据。
- 接口速度:接口速度是影响硬盘性能的一个最不重要的因素,目前的接口速度在理论上可以满足硬盘所能达到的最高外部传输带宽。
- 内部传输速率:磁盘的内部传输速率是指磁头读写磁盘时的最高速率,这个速率不包括寻道以及等待扇区旋转到磁头下所耗费的时间的影响。然而这种情况是不可能出现的,只是一种理想情况,要读取数据,磁头很少是不需要换道的。
SSD
SSD(Solid State Drive,固态硬盘)是一种利用Flash芯片或者DRAM芯片作为数据永久存储的硬盘,其性能相对机械硬盘来说有很好的优势。
SSD没有机械寻道时间,对任何地址的访问开销都是相等的,所以随机IO性能很好。现在比较常见的SSD是基于Flash介质的SSD。
所有类型的ROM和Flash芯片使用一种叫做“浮动门场效应晶体管”的晶体管来保存数据,每个这样的晶体管叫做一个“Cell”,即单元。大量的Cell逻辑上形成一个Page,一般一个Page可以存放4KB的内容,Page是SSD的IO的最小单位。多个Page组成一个Block,Block size的大小一般有32KB,64KB,128KB和512KB等规格,视不同设计而定。
SSD主要由SSD控制器,FLASH存储阵列,板上DRAM(可选),以及跟HOST接口(诸如SATA,SAS, PCIe等)组成。
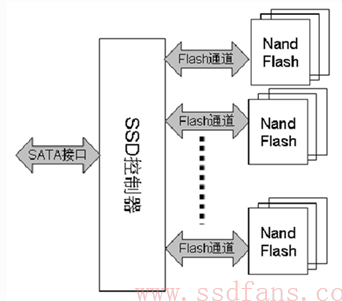
SSD主控通过若干个通道(channel)并行操作多块FLASH颗粒,类似RAID0,大大提高底层的带宽。
SSD硬盘在写入数据之前需要Erase掉这个Cell,这里的Erase动作就是将一大片连续的Cell全部放电,这片连续的Cell就是一个Block。但是,不能单独擦除某个或者某段Page,或者单独或多个Cell。这是因为对于Block中的所有Cell来讲,只有“全部在放电”或者“全部/部分在充电”这两个状态,不会产生干扰。SSD会以Page为单位进行写入操作,写完一个Page,再写下一个Page。每个Block中的Page必须被按照一个方向写入,SSD控制器可以先向Block中写入前10个Page,一段时间后可以再向这个Block中追加写入剩余的Page而不需要再次擦除这个Block。一般来讲,SSD控制器都是尽量一次写满整个Block的从而可以避免很多额外开销。
SSD内部维护了一张映射表(Map Table),HOST每写入一个Host Page,就会产生一个新的映射关系,这个映射关系会加入(第一次写)或者更改(覆盖写)Map Table。当读取某个Host Page时,SSD首先查找Map Table中该Host Page对应的Physical Page,然后再访问Flash读取相应的Host数据。一张Map Table有多大呢?这里假设我们有一个256GB的SSD,以4KB Host Page为例,那么一共有约64M(256GB/4KB)个Host Page,也就意味着SSD需要有64M大小的Map Table。Map Table中的每个Entry存储的就是物理地址(Physical Page Address),假设其为4Byte (32 bits) ,那么整个Map Table的大小为64M*4B = 256MB。
对绝大多数SSD,我们可以看到上面都有板载DRAM,其主要作用就是用来存储这张映射表。也有例外,比如基于Sandforce主控的SSD,它并不支持板载DRAM,那么它的映射表存在哪里呢?SSD工作时,它的绝大部分映射是存储在FLASH里面,还有一部分存储在片上RAM上。当HOST需要读取一笔数据时,对有板载DRAM的SSD来说,只要查找DRAM当中的映射表,获取到物理地址后访问FLASH从而得到HOST数据,这期间只需要访问一次FLASH。而对Sandforce的SSD来说,它首先看看该Host Page对应的映射关系是否在RAM内。如果在,那好办,直接根据映射关系读取FLASH;如果该映射关系不在RAM内,那么它首先需要把映射关系从FLASH里面读取出来,然后再根据这个映射关系读取Host数据。这就意味着相比有DRAM的SSD,它需要读取两次FLASH才能把HOST数据读取出来,底层有效带宽减半。对HOST随机读来说,由于片上RAM有限,映射关系Cache命中(映射关系在片上RAM)的概率很小,所以对它来说,基本每次读都需要访问两次FLASH,所以我们可以看到基于Sandforce主控的SSD随机读取性能是不太理想的。
继续回到之前的SSD写操作。当整个SSD写满后,从用户角度来看,如果想写入新的数据,则必须删除一些数据,然后腾出空间再写。用户在删除和写入数据的过程中,会导致一些Block里面的数据变无效或者变老。Block中的数据变老或者无效,是指没有任何映射关系指向它们,用户不会访问到这些FLASH空间,它们被新的映射关系所取代。比如有一个Host Page A,开始它存储在FLASH空间的X,映射关系为A->X。后来,HOST重写了该Host Page,由于FLASH不能覆盖写,SSD内部必须寻找一个没有写过的位置写入新的数据,假设为Y,这个时候新的映射关系建立:A->Y,之前的映射关系解除,位置X上的数据变老失效,我们把这些数据叫垃圾数据。
随着HOST的持续写入,FLASH存储空间慢慢变小,直到耗尽。如果不及时清除这些垃圾数据,HOST就无法写入。SSD内部都有垃圾回收机制,它的基本原理是把几个Block中的有效数据(非垃圾数据)集中搬到一个新的Block上面去,然后再把这几个Block擦除掉,这样就产生新的可用Block了。下一小节将要讲到的垃圾回收。
SSD写入数据时存在许多效率低下的问题:
写惩罚
向某个Block写入数据需要先Erase整个Block为1,然后再向Block中写入新数据。特别是需要修改Block中的某个Page时,需要将Block中的数据先读入SSD的RAM Buffer,然后Erase整个Block,再将待写入的数据覆盖到RAM中对应的Page,再更新整个Block。这种机制增加了写开销,形成了大规模的写惩罚。这也是SSD的缓存通常很大的原因。
预留空间(OP,Over Provisioning)
SSD内部需要预留空间,这部分空间HOST是看不到的。这部分预留空间,不仅仅用以做垃圾回收,事实上,SSD内部的一些系统数据,也需要预留空间来存储,比如前面说到的映射表(Map Table),比如SSD固件,以及其它的一些SSD系统管理数据。
OP的大小对硬盘的性能也有影响。显然,OP变大则用户能使用的SSD容量变小。OP变大的好处如下:我们知道一个Block上有效的数据越少(垃圾数据越多),则回收速度越快。OP越大,每个Block平均有效数据率越小,因此我们可以得出的结论:OP越大,垃圾回收越快,写放大越小。这就是OP大的好处。
SSD之垃圾回收GC
“垃圾回收”(Garbage Collection, 简称GC)
当在操作系统中删除文件时,操作系统只是在其内部文件表中做标记表示该文件已删除。由于NAND闪存设备不能覆盖现有数据,所以在固态硬盘SSD上,当前无效的数据仍然保留在硬盘上。这样的话就会产生大量的失效数据,也称为数据垃圾。为了提升SSD的利用效率,这时候就该“垃圾回收”(Garbage Collection, 简称GC)出手了。
GC过程简单来讲就是:固态硬盘控制器会先复制所有有效数据(仍在使用中的数据)并将其写入不同数据区的空白页,擦除当前数据区中的所有数据单元,然后开始将新数据写入刚刚擦除过的数据区。GC过程示例如下:
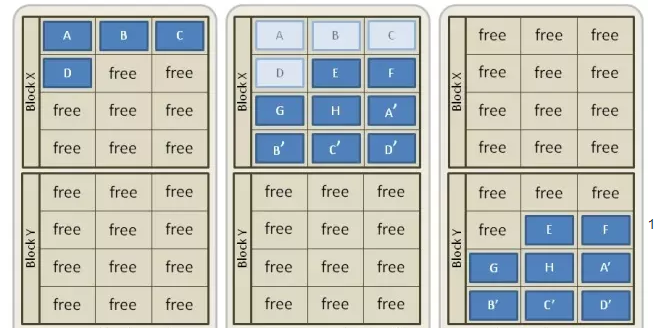
上图 SSD GC过程
- 假设SSD中有两个空的Block X和Block Y,每个Block有12个page;
- 首先在Block X中写入4个Pages(A, B, C, D);
- 接着再向Block X中写入新的4个pages(E, F, G, H),同时写入Page A-D的更新数据(A', B', C', D'),这时Page A-D变为失效数据(invalid);
- 为了向Page A-D的位置写入数据,需要将E, F, G, H, A', B', C', D' 这8个pages先搬到Block Y中, 之后再把Block X erase掉,这个过程就为GC。
当写入新数据时,如果SSD控制器找不到可以写入的Page时,会执行GC过程,然后GC机制会将一些Block中的有效数据合并写入其他的Block中,然后将这些Block的无效数据擦除,再将新数据写入到这些Block中,而在整个过程中除了要写入用户的数据之外,实际上SSD还写入了一些其他Block合并过来的数据,所以这就叫写入放大。
新的SSD,会发现写入速度很快,那是因为一开始总能找到可用的Block来进行写入。但是,随着对SSD的使用,会发现它会变慢。原因就在于SSD写满后,当需要写入新的数据,往往需要做上述的垃圾回收:把若干个Block上面的有效数据搬移到某个Block,然后擦掉原先的Block,然后再把你的Host数据写入。这比最初单纯的找个可用的Block来写耗时多了,所以速度变慢也就可以理解了。
SSD性能测试
HDD机械硬盘的性能稳定,几乎没有随机性能,所以测试时跑几个读写速度测试就可以了。但是SSD固态硬盘的情况复杂的多,读写过程不一样,随机性能也不一样,主控、NAND类型及OP空间的不同导致性能差异很大,而越用越慢的特性也让初始性能和日常使用性能泾渭分明。
存储网络行业协会(Storage Networking Industry Association ,简称SNIA) 的固态存储倡议小组(Solid State Storage Initiative ,简称SSSI)已经设计出了一套可用于测试固态硬盘性能的规范,包括测试固态硬盘的初始状态和持续运行时的性能。
固态硬盘在FOB状态(Fresh Of Box,刚拆封的状态)性能相对较高。而使用一段时间后,随着不断写数据/擦除数据,性能会降低。FOB状态下的性能测试结果与固态硬盘稳定使用后的性能测试结果可能会相差很大。 稳定状态下的写数据IOPS性能结果可能还不到FOB状态下性能测试结果的一半。
SSD的性能与写入历史有莫大关系。详细来说,FOB(Fresh Of Box,刚拆封的状态)状态下的SSD性能最高,然后随着使用其性能快速下降,这个阶段叫做转换阶段(Transition State),继续使用之后SSD的性能会固定下来,这个阶段叫做稳定阶段(Steady State)。基准性能测试中达到稳定状态很重要,也是可能的,只要对SSD全盘写入几次就可以了。
因此,测试SSD性能的时候,建议先做随机测试,再做顺序测试,因为顺序可能有cache的影响。先测试写,再测读,因为SSD的特性,写入量大之后性能会下降。
SSD硬盘虽然不像机械硬盘一样有磁头的机械寻道时间,但SSD的随机写和顺序写性能有差别。这是由SSD的底层闪存的基本属性决定的,对闪存来说,数据是以页为单位读写的,只有在一页所属的块整个被擦除后,才能随机写这一页(通常是指该块的所有位都被置1)。而且擦除Block需要相对较长的时间,1ms级的,比访问页所需时间要高一个多数量级。SSD以Page为单位进行读写,以Block为单位做垃圾回收,Page一般有16KB大小,Block一般有几十MB大小,SSD写数据的逻辑是:
1)将该块数据所在的Page读出;
2)修改该Page中该块数据的内容;
3)找出一个新的空闲Block将2)中的Page写入,并将1)中提到的Page所在的Block中的Page标志为脏
理解了写原理,也就明白了为什么顺序写的性能比随机写好了。四个字:垃圾回收!写相同数据量的情况下,顺序写产生更少的垃圾Block,所以比随机写有更高的性能。
当然,如果每次读写都以Block为单位,那么顺序写和随机写的性能相当。
存储冗余之RAID
RAID卡类型
RAID(Redundant Array of Independent Disks),简称磁盘阵列。其基本思想就是把多个相对便宜的硬盘组合起来,成为一个硬盘阵列组,使性能达到甚至超过一个价格昂贵、容量巨大的硬盘。RAID同时提供数据冗余机制,降低硬盘失效导致数据丢失风险。实现了RAID功能的卡(SCSI卡或者IDE扩展卡)就叫做RAID卡
RAID卡主要技术
RAID卡核心技术包含三部分内容:1、数据条带化;2、数据冗余;3、高速缓存。
数据条带化
当多个进程同时访问一个磁盘时,可能会出现磁盘冲突。大多数磁盘系统都对访问次数(每秒的I/O操作,IOPS)和数据传输率(每秒传输的数据量,TPS)有限制。当达到这些限制时,后面需要访问磁盘的进程就需要等待,这时就是所谓的磁盘冲突。避免磁盘冲突是优化 I/O性能的一个重要目标,而I/O性能的优化与其他资源(如CPU和内存)的优化有着很大的区别,I/O优化最有效的手段是将 I/O最大限度的进行平衡。
条带化技术就是一种自动的将I/O的负载均衡到多个物理磁盘上的技术,条带化技术将一块连续的数据分成很多小部分并把他们分别存储到不同磁盘上去。这就能使多个进程同时访问数据的多个不同部分而不会造成磁盘冲突,而且在需要对这种数据进行顺序访问时可以获得最大程度上的 I/O 并行能力,从而获得非常好的性能。下图是未经过条带化处理和经过条带化处理的连续数据的分布,可以发现图2中对连续数据的读写都有最大的并发能力。
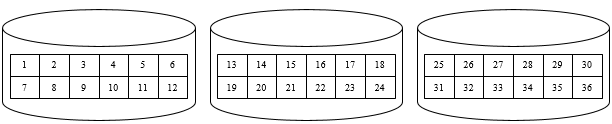
上图 未经条带化处理的数据,数据块线性顺序分布
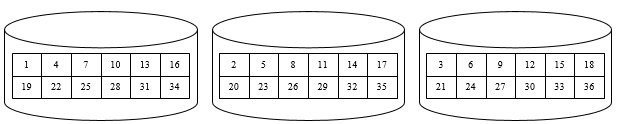
上图 经过条带化处理的数据,数据块分布式分布
- 当对数据做条带化时,数据被切成一块块的小数据块,各小数据块分布存储在不同的硬盘上。从这个描述中我们可以看出,影响条带化效果的因素有两个,一是条带大小(stripe size),即数据被切成的小数据块的大小,另一个条带宽度(stripe width),即数据被存储到多少块硬盘上。
- 条带大小(stripe size):有时也被叫做block size,chunk size,stripe length或者granularity。这个参数指的是写在每块磁盘上的条带数据块的大小。RAID的数据块大小一般在2KB到512KB之间(或者更大),其数值是2的次方,即2KB,4KB,8KB,16KB这样。
- 条带宽度(stripe width):是指同时可以并发读或写的条带数量。这个数量等于RAID中的物理硬盘数量。例如一个经过条带化的,具有4块物理硬盘的阵列的条带宽度就是4。增加条带宽度,可以增加阵列的读写性能。道理很明显,增加更多的硬盘,也就增加了可以同时并发读或写的条带数量。在其他条件一样的前提下,一个由8块18G硬盘组成的阵列相比一个由4块36G硬盘组成的阵列具有更高的传输性能。
条带大小对性能的影响比条带宽度难以度量的多:
- 减小条带大小:由于条带大小减小了,则文件被分成了更多个更小的数据块。这些数据块会被分散到更多的硬盘上存储,因此提高了传输的性能,但是由于要多次寻找不同的数据块,磁盘定位的性能就下降了。
- 增加条带大小: 与减小条带大小相反,会降低传输性能,提高定位性能。
根据上边的论述,我们会发现根据不同的应用类型,不同的性能需求,不同驱动器的不同特点(如SSD硬盘),不存在一个普遍适用的“最佳条带大小”。所以这也是存储厂家,文件系统编写者允许我们自己定义条带大小的原因。不同条带大小,对于文件如何存储有很大的影响,
对于大多数应用来说,可以参考这样的经验法则:大量的小文件读写时,采用较大的条带大小(定位效果好);少量的大文件的快速访问,采用比较小的条带(传输速率高);如果要平衡这两者,那么采用中间值。
数据冗余
数据冗余在出现磁盘错误或磁盘故障时,可以保证数据完整性和数据处理能力。RAID卡通过冗余的磁盘组在RAID 1、5、6、10、50、60上实现此功能。在RAID 1中,由于数据镜像存储于成对的磁盘上,因此在成对的磁盘中的一个产生错 误或故障时,不会造成数据丢失。同理,在RAID 5中,允许1个磁盘故障;在RAID 6中,允许2个磁盘故障。而对于包含多个子组的RAID,RAID 10、50允许故障盘的个数与子组数相同,但是要求每个子组只能包含1个故障盘。RAID 60允许故障盘的个数为子组数的2倍,要求每个子组多包含2个故障盘。
高速缓存
能够提供高速缓存回写是raid控制器卡的诸多优点之一。高速缓存回写通过在服务器使用高峰时间将数据保存到高性能缓存当中,来提高应用程序的运行性能。当服务器出现用户访问间隙的时,数据会从高速缓存写入到磁盘当中。对于上层的写I/O,raid控制器有两种手段来处理,Write Back和Write Through。
Write Back
上层发过来的数据,RAID控制器将其保存到缓存中之后,立即通知主机IO已经完成,从而主机可以不加等待地执行下一个IO,而此时数据正在RAID卡的缓存中,而没有真正写入磁盘,起到了一个缓冲作用,RAID控制器等待空闲时,或者一条一条地写入磁盘,或者批量写入磁盘,或者对这些IO进行排队等一些优化算法,以便高效写入磁盘。这样做有一个致命缺点,就是一旦意外掉电,RAID卡上缓存中的数据会全部丢失,而此时主机认为IO已经完成,这样上下层就产生了不一致,后果将非常严重。因此,中高端的RAID卡都需要用电池来保护缓存,从而在意外掉电的情况下,电池可以持续对缓存进行供电,保证数据不丢失。
Write Back可以提高写操作的性能。数据不是直接被写入磁盘;而是写入缓存。从应用程序的角度看,比等待完成磁盘写入操作要快的多。因此,可以提高写性能。由控制器将缓存内未写入磁盘的数据写入磁盘。表面上看,Write Back方式比Write Through方式的读、写性能都要好,但是也要看磁盘访问方式和磁盘负荷了。Write Back方式通常在磁盘负荷较轻时速度更快。负荷重时,每当数据被写入缓存后,就要马上再写入磁盘以释放缓存来保存将要写入的新数据,这时如果数据直接写入磁盘,控制器会以更快的速度运行。因此,负荷重时,将数据先写入缓存反而会降低吞吐量。
Write Through
写透模式,只有数据切切实实被RAID控制器写入磁盘之后,才会通知主机IO完成,这样做保证了高可靠性。此时,缓存的提速作用就没有了。Write Through意思是写操作根本不使用缓存,数据总是直接写入磁盘。关闭写缓存,可释放缓存用于读操作。(缓存被读写操作共用)。
除了写缓存之外,读缓存也是非常重要的。缓存中有一种算法叫做PreFetch,即预取。预取就是在主机还没有发出IO请求的时候,就将磁盘上可能被主机访问的数据先读入到缓存中。中高端的RAID卡一般具有256MB以上RAM作为缓存。
RAID卡物理结构
RAID卡就是一个小的计算机系统,有自己的CPU、内存、ROM、总线和IO接口,只不过这个小计算机是为大计算机服务的。RAID卡的架构示意图如下。
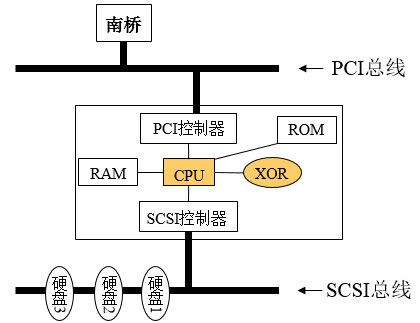
上图 RAID卡结构示意图
SCSI RAID卡上一定要包含SCSI控制器,因为其后端连接的依然是SCSI物理磁盘。其前端连接到主机的PCI总线上,所以一定要有一个PCI总线控制器来维护PCI总线的仲裁、数据发送接收等功能。还需要一个ROM,一般是用Flash芯片作为ROM,其中存放着初始化RAID卡必须的代码以及实现RAID功能所需的代码。
RAM的作用,首先是作为数据缓存,提高性能;其次作为RAID卡上的CPU执行RAID运算所需的内存空间。XOR芯片是专门用来做RAID 3、5、6这类校验型RAID的校验数据计算用的。如果让CPU来做校验计算,需要执行代码,将耗费许多周期。而如果直接使用专用的数字电路,一进一出就立即得到结果。所以为了解脱CPU,增加了这块专门用于XOR运算的电路模块,大大增加了数据校验计算的速度。
RAID卡的内存
RAID卡上的内存,有数据缓存和代码执行内存两种作用。RAID卡上的CPU执行代码,需要RAM的参与。如果直接从ROM中读取代码,速度会受到很大影响。所以RAID卡的RAM中有固定地址段用于存放CPU执行的代码。而大部分的空间都是用作了下文介绍数据缓存。
缓存,也就是缓冲内存。RAID控制器和磁盘通道控制器之间也要有一个缓存来适配,因为通常情况下RAID控制器的处理速度远远快于磁盘通道控制器所连接的磁盘传出的数据速度。缓存RAM除了适配不同速率的芯片通信之外,还有一个作用就是缓冲数据IO。RAID控制器可以将上层发起的IO请求放到缓存中排队,然后一条一条执行,或者优化这些IO,进行合并和并发操作。
RAID的初始化过程
对于校验型RAID,在RAID卡上设置完RAID参数并且应用RAID设置后,RAID阵列中的所有磁盘需要进行一个初始化过程,初始化过程需要的时间与磁盘的数量、大小有关。磁盘越大,数量越多,初始化需要的时间久越长。
如果初始化过程不对磁盘进行任何更改,直接拿来写数据,就会存在校验块的校验数据与一开始的数据块不一致,导致越算越错。所以RAID控制器在初始化的过程中需要将磁盘每个扇区都写成0或1,然后计算正确的校验位,或者不更改数据块的数据,直接用这些已经存在的数据,重新计算所有条带的校验块数据
RAID基本术语
- Drive Group:磁盘组,将硬盘加入磁盘组。
- Virtual Drive:逻辑磁盘,DG的一个分区,VD可以是DG的一部分,整个DG,也可以跨越多个DG。
- Fault Tolerance:故障容忍度,根据RAID组级别不同而不同,在保证系统数据完整业务正常的情况下最多允许损坏的硬盘数量。
- Consistency Check:一致性校验,后台执行,验证可冗余RAID组内的数据一致性,该功能会影响性能,但可以保证数据安全性。
- Copy back:回拷功能,当RAID组内硬盘故障后,热备硬盘会临时替代故障硬盘进行重构,重构完毕,当故障硬盘更换后,热备盘数据自动拷贝回新硬盘中。
- Background Initialization:后台初始化,RAID组建立后自动运行,检查虚拟卷的media error,类似于一致性校验。
- Patrol Read:读巡检,确定硬盘的健康状态,第一时间发现硬盘的状态异常,保证数据安全性。
- Disk Striping:硬盘条带,VD通过条带,可以将数据按照条带划分写入到不同的硬盘上,2308卡条带固定为64KB,2208条带8KB~1024KB可选。
- Disk Mirroring:硬盘镜像,在RAID1/RAID10上使用,数据同时写到两个硬盘上,两个硬盘都可以提供给业务系统读数据。
- Parity:奇偶校验,存在于RAID5,RAID6上,通过对条带上的数据进行奇偶校验计算,产生校验位,分散着写入到不同硬盘中。
- Hot Spares drive:热备硬盘是一个独立的空闲硬盘,其一般工作在standby状态,一旦冗余RAID组中的硬盘故障,其立刻替代故障硬盘。
- Disk Rebuilds:硬盘重构,当硬盘出现故障后,热备硬盘或者新插入的硬盘会替代故障硬盘,并进行数据重构,确保数据与原硬盘一致。
- Rebuild Rate:重构占比,硬盘重构在系统运行中的优先级,100表示优先级最高,0表示优先级最低。
- Hot Swap:系统在运行的情况下,更换故障硬盘为新硬盘之后,重构自动开始。
- Drive/Virtual Drive States:硬盘状态,online,UG,hot spare,failed,rebuild,UB,missing,offline。逻辑卷状态 optimal,Degraded,failed,offline。
- Write Back/Write Through:RAID卡上存在高速缓存,WB写入到RAID卡的Cache中,WT写的时候直接写入硬盘,不经过Cache。
- Read ahead:预读,每次读操作读出更多数据,并缓存到Cache中。
RAID级别
RAID 0
RAID 0以位或字节为单位分割数据,并行读/写于多个磁盘上,因此具有很高的数据传输率,但它没有数据冗余,因此并不能算是真正的RAID结构。RAID 0只是单纯地提高性能,并没有为数据的可靠性提供保证,而且其中的一个磁盘失效将影响到所有数据。因此,RAID 0不能应用于数据安全性要求高的场合。
上图 典型的RAID 0系统
RAID 1

对于RAID1的写IO,因为数据要同时向多块物理盘写,时间以最慢的为准,因此写IO速度没有提升,而且有下降。而对于RAID1的读IO请求,不但可以并发,而且就算在顺序IO的时候,控制器也可以像RAID0一样,从两块物理盘上同时读数据,提升速度。
RAID 5
至少3块盘,增加了校验,只用于节省磁盘使用量上,现在多使用RAID10
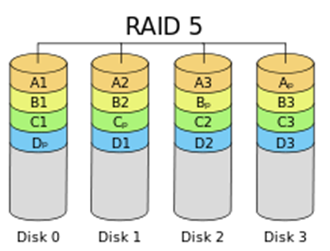
RAID 5中有这样几个概念:
- 整条写:需要修改奇偶校验群组中所有的条带单元,每个条带上的segment都更新,不需要额外的读写操作,写性能最好。
- 重构写:当需要写入的磁盘数目超过阵列磁盘的一半时采取该方式:从不需要修改的segment中读取原来的数据,再和本条带中所有需要修改的segment上的新数据一起计算XOR校验值;将新的segment数据和没有更新过的segment数据以及新的XOR校验值一起写入。例如:数据盘为8块,某个时刻一个IO只更新了一个条带的6个segment,剩余两个没有更新。在重构写模式下,会将没有更新的两个segment数据读出,和需要更行的前6个segment计算出校验数据,然后数据和校验信息一起写入磁盘。与整条写的比较,多出读segment数据操作和写校验数据操作。
- 读改写:当需要写入的磁盘数目不超过一半时采取:从需要修改的segment中读取旧数据,再从条带上读取旧的奇偶校验值(读);根据旧数据、旧校验值和需要修改的segment上的新数据计算这个条带上的新校验值(改);写入新的数据和校验值(写)。
写效率为:整条写>重构写>读改写。
RAID 10
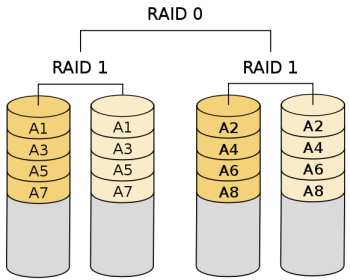
至少需要4快硬盘。raid10是2快硬盘组成raid1,2组raid1z组成raid0,所以必须需要4块硬盘。
其它
JBOD
硬盘直通,即“JBOD”功能,又称指令透传,是不经过传输设备处理,仅保证传输质量的一种数据传输方式。 打开硬盘直通功能后,RAID控制器可对所连接的硬盘进行指令透传,在不配置虚拟磁 盘的情况下,用户指令可以直接透传到硬盘,方便上层业务软件或管理软件访问控制 硬盘。例如,服务器操作系统安装过程中,可以直接找到挂载在RAID卡下的硬盘作为安装 盘;而不支持硬盘直通的RAID卡,在操作系统安装过程中,只能找到该RAID卡下已 经配置好的虚拟磁盘作为安装盘。
SAS Expander
SAS在SATA的串行点对点架构的基础上,通过引入相当于网络中交换机和路由器的Expander(扩展器),从而能够形成一个先进的交换式拓扑架构,伸缩性和灵活性远远超出并行SCSI及FC-AL(光纤通道仲裁环路)。如果要构建一个基于SAS技术的磁盘阵列或更大型的存储系统,Expander必不可少。与SAS控制芯片、HBA和硬盘驱动器相比,SAS Expander IC虽然端口数量较多,但对外的连接比较简单,需要考虑的标准只有SAS一种。SAS Expander的SAS端口不仅要连接硬盘驱动器等端设备,还要连接主机端设备。这些端口一般都能自动检测并协商6Gbps或12.0Gbps的连接速率,以及支持配置为一个宽端口(x2或x4)。
硬盘背板
SAS Expander通常位于硬盘背板上,磁盘背板也是典型的内部连接应用,一面接硬盘驱动器,另一面连HBA/RAID卡。在机架式服务器或硬盘驱动器槽位较多的塔式服务器中,SAS HBA/RAID卡一般不直接用SAS线缆与硬盘驱动器相连,而是会通过磁盘背板,以方便硬盘驱动器的插拔。根据有无SAS Expander芯片,硬盘背板的分类如下:
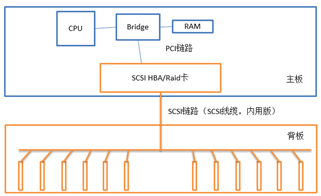
早期硬盘背板
最早期的SCSI硬盘的接入方式,由于采用总线结构,背板可以做成无源背板,而且走线十分方便,大部分导线被焊接到背板的PCB上,只留一个链接器连接到SCSI HBA/RAID卡即可。
上图 早期硬盘背板
SAS卡直连无源背板
这种连接方式下,SAS卡(不管是HBA还是带RAID功能的HBA)采用x4的线缆直接连接到背板上的连接器,背板上每4个硬盘接口被导入到一个x4的连接器上从而直接连接到SAS卡。也就是说,如果有16块盘,那么背板需要出4个x4连接器,分别连接到SAS卡一侧的一个x4连接器上,前提是SAS卡必须支持对应数量的直连设备。
上图 直连无源硬盘背板
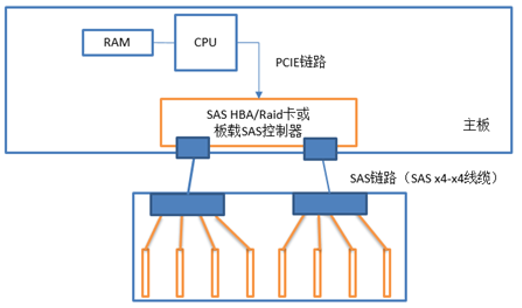
SAS卡连接带Expander的有源背板
有些型号的SAS卡最大只能直连8个设备,而有些服务器其前面板有12个硬盘槽位。此时,只能靠SAS Expander(简称EXP)了,12个槽位先连接到EXP。
上图 带expander有源硬盘背板
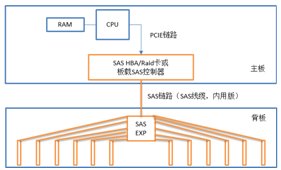
SAS卡连接Expander子板再连接无源背板
有些时候服务器厂商不想为了增加一个Expander而再制作一款背板,而是想利用现有的无源背板,比如支持16盘位的无源背板,再加上一小块子板,将Expander放在这个子板上,再将这个子板与SAS HBA及背板分别连接起来。
使用了expander芯片的背板为扩展背板,没有使用expander芯片的背板为非扩展背板。非扩展背板不存在硬盘兼容性问题,扩展背板由于扩展芯片的固件版本等问题会有兼容性问题。
Expander性能影响
SAS Expander是通过在背板上增加的一颗芯片,由该芯片来实现将有限的输入扩展到更多的输出:如主板、raid卡或者HBA卡最大只能支持8个SAS/SATA硬盘,通过扩展背板后,可以让服务器支持到24个SAS/SATA硬盘。
然而,expander也会带来性能的损耗,这是因为expander会增加一层软件处理和路由处理。带expander的配置,会在Raid卡和硬盘之间多一个expander芯片,这个芯片要运行软件,多出了一层硬件转发和软件处理,如下图所示:
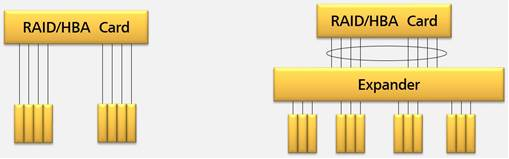
不带expander和带expander链路拓扑图
在开始每一个IO时,RAID卡的一个phy需要与目标硬盘建立连接。如果链路拓扑上有expander,那么过程是RAID卡向expander发出建立连接的请求帧,需要expander在接到这个请求帧后,根据其中的路由规则选择expander对应phy,再将这个请求帧转发到对应的phy,才能发给目标硬盘。如果没有expander,请求帧直接发给硬盘,可以省掉路由的过程。这个路由消耗在小数据块IO模型时影响较大。
另一方面,在连接建立后,如果硬盘是SATA盘,由于RAID卡与expander之间都是以SAS协议通信,交互的都是SAS命令,expander需要在RAID卡和SATA盘之间进行SAS命令和SATA命令的转换,这部分带来软件处理的开销,相对于直连会降低性能。
平时测试过程中大多忽略了expander固件版本的影响,带expander的背板测试中还要考虑固件版本影响。使用expanderTool工具对expander固件查询和升级。
影响存储子系统性能的因素
CPU性能
主机是IO的发起端,IO特性首先由主机的业务软件和硬件配置所决定。
在定位存储问题时,需要首先对主机性能进行排查。CPU和内存的性能都会影响主机下发业务的能力,导致性能降低。
大部分情况下,CPU不会成为存储性能的瓶颈。然而我们知道硬盘的数据读写都需要调用CPU线程来完成,特别是大量4KB小块文件寻址和读写需要消耗不小的CPU资源,所以SSD和NVME这些极速设备的存储性能就和CPU的执行能力构成了对应的关系。因此,我们需要关注CPU性能,不让CPU成为SSD和NVME性能发挥的瓶颈。
CPU频率与调节
CPU型号
不同型号CPU的基频和超频不一样,可以根据需要更换更高规格的CPU来提高存储性能。
OS调频
操作系统会根据当前CPU负载调整CPU的频率,以达到满足当前使用的前提下降低电量消耗。主要的调频策略有以下几种:
调节器 |
描述 |
|---|---|
ondemand |
按需快速动态调整CPU频率, 在有cpu计算量的任务时,就会立即达到最大频率运行,等执行完毕就立即回到最低频率(阙值为95%) |
performance |
运行于最大频率 |
conservative |
按需快速动态调整CPU频率, 在有cpu计算量的任务时,就会立即达到最大频率运行,等执行完毕就立即回到最低频率(阙值为75%) |
powersave |
运行于最小频率 |
userspace |
运行于用户指定频率 |
注意高频设置一般存在于物理机中,但也可以通过在编译内核模块参数时选择支持
cpufreq是一个动态调整cpu频率的模块,系统启动时生成一个文件夹/sys/devices/system/cpu/cpu0/cpufreq/,里面有几个文件,
其中scaling_min_freq代表最低频率,scaling_max_freq代表最高频率,scalin_governor代表cpu频率调整模式,用它来控制CPU频率 其中
- performance :顾名思义只注重效率,将CPU频率固定工作在其支持的最高运行频率上,而不动态调节。
- powersave:将CPU频率设置为最低的所谓“省电”模式,CPU会固定工作在其支持的最低运行频率上。因此这两种governors 都属于静态governor,即在使用它们时CPU 的运行频率不会根据系统运行时负载的变化动态作出调整。这两种governors 对应的是两种极端的应用场景,使用performance governor 是对系统高性能的最大追求,而使用powersave governor 则是对系统低功耗的最大追求。
- Userspace:最早的cpufreq 子系统通过userspace governor为用户提供了这种灵活性。系统将变频策略的决策权交给了用户态应用程序,并提供了相应的接口供用户态应用程序调节CPU 运行频率使用。也就是长期以来都在用的那个模式。可以通过手动编辑配置文件进行配置
- ondemand 按需快速动态调整CPU频率, 一有cpu计算量的任务,就会立即达到最大频率运行,等执行完毕就立即回到最低频率; ondemand:userspace是内核态的检测,用户态调整,效率低。而ondemand正是人们长期以来希望看到的一个完全在内核态下工作并且能够以更加细粒度的时间间隔对系统负载情况进行采样分析的governor。 在 ondemand governor 监测到系统负载超过 up_threshold 所设定的百分比时,说明用户当前需要 CPU 提供更强大的处理能力,因此 ondemand governor 会将CPU设置在最高频率上运行。但是当 ondemand governor 监测到系统负载下降,可以降低 CPU 的运行频率时,到底应该降低到哪个频率呢? ondemand governor 的最初实现是在可选的频率范围内调低至下一个可用频率,例如 CPU 支持三个可选频率,分别为 1.67GHz、 1.33GHz 和 1GHz ,如果 CPU 运行在 1.67GHz 时 ondemand governor 发现可以降低运行频率,那么 1.33GHz 将被选作降频的目标频率。
- conservative 与ondemand不同,平滑地调整CPU频率,频率的升降是渐变式的,会自动在频率上下限调整,和ondemand的区别 在于它会按需分配频率,而不是一味追求最高频率;
xxxxxxxxxx171#查看当前的调节器:2cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor3
4# 更改使用的调节器,需再更改scaling_governor文件:5echo conservative > /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor6
7#查看系统目前可用的调节器:8cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_available_governors9
10调频工具cpupower,可以对CPU频率进行调节和查看11查看当前频率:cpupower frequency-info -freq12
13查看当前支持的governor:cpupower frequency-info -governor14
15查看使用的CPUfreq driver:cpupower frequency-info -driver16
17设置CPU的调节策略:cpupower frequency-set --governor <governor>
BIOS调频
- 如果在系统压力不大的情况下,由于CPU的休眠机制,可能会造成IO处理时间较长,所以需要关闭EIST、C-state、Mwait等不让CPU进入休眠状态,使CPU稳定工作在最高频率。
- HT也是要关的,但是在NVME SSD测试中,需要绑定多核时可以按需打开HT。
- VT之类都是必须关的。
- NUMA在实际测试中对于存储性能没好处, BIOS能关就关,不能关闭的话可以用numactl来指定。
- CPU的超频最大值与开启的核心数相关,在某些需要发挥CPU最大频率的场景下可以激活指定个数的CPU。
在某些场景下会使用单线程测试NVMe或SSD的性能。单线程场景下,硬盘的测试性能不能达到最大值,这时候硬盘的性能就与单核的性能相关。一般情况下,CPU核心数越多,单核的性能就会越弱,SSD和NVMe盘的单线程测试性能就会低一些。
CPU利用率
Linux主机可以通过top命令进行查看,top命令能够实时显示系统中各个进程的资源占用情况。在对性能要求很高的应用场景,当查询到主机侧CPU使用率过高、主机内存不足时,可以通过更换更高性能的主机或者增加并行测试的主机数量来解决。
实际测试中还需要注意以下几点:
- 测试NVMe和SSD时,按需要进行绑核进行测试
- 在进行问题定位时,需要使用turbostat工具直观准确的检查CPU频率
CPU和中断平衡
硬件中断发生频繁会很消耗CPU的资源,在多核CPU条件下如果可以把大量硬件中断分配给不同CPU,则可以得到很好的平衡性能。现代服务器大多为多CPU、多核、多网卡和多硬盘配置,如果能让网卡中断独占1个CPU core,硬盘IO中断独占1个CPU core的话将会大大减轻CPU的负担,提升整理处理效率。
irqbalance是一个通过分配处理器硬件中断以提高系统性能的命令行工具,它可以根据CPU的压力情况,将各种IRQ重新指定到不同的CPU进行处理。irqbalance 用于优化中断分配,它会自动收集系统数据以分析使用模式,并依据系统负载状况将工作状态置于 Performance mode 或 Power-save mode。
处于 Performance mode 时,irqbalance 会将中断尽可能均匀地分发给各个 CPU core,以充分利用 CPU 多核,提升性能。
处于 Power-save mode 时,irqbalance 会将中断集中分配给第一个 CPU,以保证其它空闲 CPU 的睡眠时间,降低能耗。
xxxxxxxxxx31service irqbalance status2service irqbalance stop3chkconfig --level 123456 irqbalance off上面两种方法都可以马上停止irqbalance服务,并且也可以在以后系统启动的时候不会去启动irqbalance服务。这些修改无须重新启动机器。
通过编辑文件/etc/sysconfig/irqbalance可以设置irqbalance,例如:
xxxxxxxxxx11IRQBALANCE_ARGS="--policyscript=/etc/sysconfig/irqbalance.rules --hintpolicy=subset"也可将hintpolicy设为exact。
内存性能
在大流量磁盘IO读写时,会消耗大量的系统内存,如果此时内存性能成为瓶颈,将会影响整体的IO性能。
内存使用率监控
首先检查内存容量是否是瓶颈:执行free –g命令查看空闲内存是否很少
xxxxxxxxxx61[root@cvm-3jzm2xc25i225 ~]# free -m2total used free shared buff/cache available3Mem: 983 298 95 50 589 4834Swap: 2047 124 19235[root@cvm-3jzm2xc25i225 ~]#6通过sar命令检查
-r表示ram
-S表示Swap
xxxxxxxxxx381[root@cvm-3jzm2xc25i225 ~]# sar -r 12Linux 5.4.232-1.el7.elrepo.x86_64 (cvm-3jzm2xc25i225.novalocal) 05/03/2023 _x86_64_ (1 CPU)3410:59:05 AM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty510:59:06 AM 96196 910776 90.45 141404 410120 1218008 39.24 357864 421364 28610:59:07 AM 96196 910776 90.45 141404 410120 1218008 39.24 357868 421364 28710:59:08 AM 96196 910776 90.45 141404 410120 1218008 39.24 357868 421364 28810:59:09 AM 96196 910776 90.45 141404 410120 1218008 39.24 357868 421364 56910:59:10 AM 96196 910776 90.45 141404 410120 1218008 39.24 357868 421364 561010:59:11 AM 96132 910840 90.45 141404 410120 1218008 39.24 357868 421364 561110:59:12 AM 96132 910840 90.45 141404 410120 1218008 39.24 357868 421364 561210:59:13 AM 96132 910840 90.45 141404 410120 1218008 39.24 357868 421364 561310:59:14 AM 96132 910840 90.45 141404 410120 1218008 39.24 357868 421364 5614^C151610:59:14 AM 96132 910840 90.45 141404 410120 1218008 39.24 357868 421364 5617Average: 96164 910808 90.45 141404 410120 1218008 39.24 357868 421364 4818[root@cvm-3jzm2xc25i225 ~]#192021[root@cvm-3jzm2xc25i225 ~]# sar -S 122Linux 5.4.232-1.el7.elrepo.x86_64 (cvm-3jzm2xc25i225.novalocal) 05/03/2023 _x86_64_ (1 CPU)232411:01:13 AM kbswpfree kbswpused %swpused kbswpcad %swpcad2511:01:14 AM 1969916 127232 6.07 22112 17.382611:01:15 AM 1969916 127232 6.07 22112 17.382711:01:16 AM 1969916 127232 6.07 22112 17.382811:01:17 AM 1969916 127232 6.07 22112 17.382911:01:18 AM 1969916 127232 6.07 22112 17.383011:01:19 AM 1969916 127232 6.07 22112 17.383111:01:20 AM 1969916 127232 6.07 22112 17.383211:01:21 AM 1969916 127232 6.07 22112 17.383311:01:22 AM 1969916 127232 6.07 22112 17.3834^C353611:01:23 AM 1969916 127232 6.07 22112 17.3837Average: 1969916 127232 6.07 22112 17.3838如果业务层面内存占用太多则说明内存容量不足导致资源受限,需要对内存进行扩容。
内存硬件配置检查
影响内存性能的硬性因素包括:内存的数量、内存规格、内存的运行速率、内存通道分布、内存健康状态、内存的刷新频率。
- 内存类型的影响:RDIMM比LRDIMM性能要好10%以上,建议选用RDIMM类型内存。
- 运行速率的影响:不同的CPU支持不同的内存最大运行频率,CPU型号选择下来的时候,该值就固定下来了。内存条的额定频率不应低于CPU额定内存运行频率。
- 内存RANK数量的影响:2RANK的内存性能要好于1RANK的内存10%以上,故建议采用2RANK内存。
- 内存通道分配的影响:服务器每个内存通道放置两根内存条是最佳选择,这样能最大化CPU的内存访问速度。
- 内存刷新频率的影响:为提高内存安全性,BIOS默认设置为内存双倍刷新率,此设定在极限情况下会增加内存的开销影响内存带宽。建议在进行内存带宽极限值测试时关闭双倍刷新。
- 内存健康状态的影响:ECC(Error Checking and Correcting)是内存的错误检查和纠正的一种技术,通常ECC能够纠正一位的数据错误,能够检查到两位的数据错误。在ECC发生时可能不会引起宕机或数据异常,但是会影响内存的性能
内存配置总体原则为使服务器发挥最优性能,推荐使用平衡配置模式进行配置,即所配置的内存型号一样、所有通道都被使用、 所有的内存通道配置一样。多颗CPU配置时,保持各个CPU的内存配置一样。
链路通道性能
链路通道主要关注两个方面:
- 链路上是否有误码且误码在不断增长
- 从磁盘到RAID卡整个链路的通道带宽的瓶颈点
例如:2288H V5的24NVME机型中,CPU1和CPU2各出x16 PCIe到SW芯片PEX9797,对应的SW下各挂了12个NVMe SSD。理论上每个PCIE SW带4个NVME盘。如果每个PCIE SW多余4个NVME盘读写性能就会受PCIe SW 上行带宽限制达到带宽跑满。
RAID卡
在实际的现网问题定位以及存储测试调优中,许多案例是与Raid卡的性能相关的,Raid卡也是存储性能定位和调优的重点关注对象。
在定位于Raid卡相关问题时,安装相应的Raid工具可以帮助我们获得更加详细的raid卡信息。
LSI SAS3008:sas3ircu
LSI SAS3108、3408、3416和3508:MegaRAID Storcli
Raid卡型号、固件和驱动版本
- 检查Raid卡固件和驱动版本是否为最新版本,是否在兼容性配置范围内。
- 检查该型号的Raid卡是否带Cache,带Cache的Raid卡一般性能更好。
Raid卡配置
Raid组的级别
确认Raid级别和组成Raid的硬盘个数:JBOD、Raid0、Raid1、Raid5、Raid6、Raid10和Raid50等。
Raid条带大小
条带大小配置会影响存储性能。根据Raid性能调优指导书,Raid5和Raid10对条带的要求不同。对于RAID5,小包顺序读建议用128K条带,大包顺序读使用256K;随机读使用1M条带;顺序写使用512K或1M条带;随机写使用256K条带。对于RAID10,小包顺序读建议使用16K或64K条带,大包顺序读使用1M条带;随机读使用1M条带;顺序写使用512K或1M条带;随机写小包使用256K条带,大包使用1M条带。条带大小在创建Raid的时候就固定了,不能在线更改,需要根据实际测试模型设置条带大小。
Raid Cache
Raid卡的Cache的开关与存储介质以及Raid级别相关。对于机械盘,推荐使能Raid卡Cache。对于固态硬盘:Raid0时关闭Cache性能更好;Raid5和Raid10时,顺序IO推荐使能Cache,随机IO推荐关闭Cache。
Raid读写策略
Read:读策略可以选择Readahead和No Readahead
Write:Write Back with BBU、Write Through和Always Write Back
超级电容电量校准过程中,RAID卡写策略自动调整为“WT”模式以保证数据完整性,此时RAID卡性能会降低。若不使用超级电容,为了打开Raid卡的写Cache,则需要设置write policy为Always write back,而不是write back。
Cachecade & Direct
CacheCade允许RAID卡使用SSD硬盘创建一个CacheCade专用的虚拟磁盘作为二级Cache,为当前存在的RAID提供更好的IO性能。实际测试中我们一般选择Direct模式,cache模式会降低存储性能(cackecade需要进行数据预热)。
Raid状态
Raid初始化
创建VD后,需要初始化VD,初始化有以下三种方式:
快速初始化:前台初始化,Raid卡只是把逻辑盘的首尾10MB空间进行了全写0操作,就完成了初始化。
慢速初始化:前台初始化,Raid卡将逻辑盘全盘写0,整个逻辑盘初始化为0后才会结束初始化过程。这个初始化过程的时间与硬盘的容量相关,硬盘容量越大,初始化需要的时间越久。
后台初始化:目的是让具有冗余功能的VD中各成员盘的数据关系满足相应的Raid级别要求。后台初始化通常会对性能造成一定的损失,直到初始化操作完成。
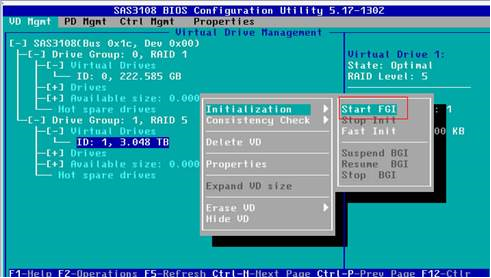
为了保证性能在创建Raid后,必须使用慢速初始化来完成硬盘的初始化操作。特别是对于Raid5、Raid6、Raid50和Raid60。因为具有校验盘的Raid组中,为了保证数据的一致性,需要进行初始化。后台初始化会占用部分硬盘IO,影响正常的业务IO。下图表示在BIOS中对一个Raid5硬盘进行前台慢速初始化操作:
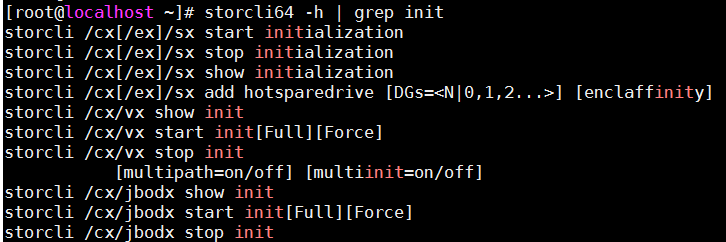
操作系统下硬盘初始化命令:
Patrol Read-巡检读
磁盘巡检功能设计为预防性措施,用于确保物理磁盘正常运行和数据完整性。巡检读取可以扫描并解决已配置的物理磁盘上的潜在问题。正常情况下,系统可以根据未完成的磁盘I/O调整专用于磁盘巡检操作的资源量。例如,如果系统正忙于处理I/O操作,则磁盘巡检将使用较少的资源,以使I/O获得更高的优先级。然而,如果Raid卡和硬盘的配合不当,巡检读则会影响硬盘的正常IO,造成上层业务IO阻塞。
Patrolread的相关命令:
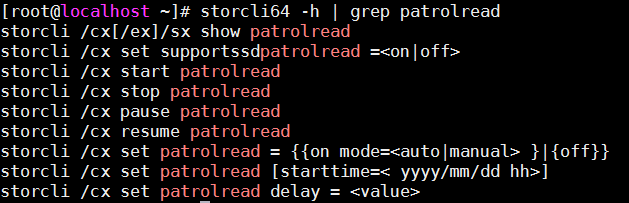
Patrolread的周期为7天,如果存储故障发生的时间具有周期性,则可以排查是否为Patrolread的周期性读造成性能异常。
Raid卡的回拷
具备冗余功能的RAID的一块成员盘故障之后,热备盘自动替换故障数据盘并开始同步。当更换新的数据盘之后,热备盘中的数据会回拷至新数据盘。在回拷完成之前,整个硬盘组的性能都会受到影响。因此,需要关注硬盘和Raid状态。
环境温度
注意测试环境温度,Raid卡的内部芯片温度如果过高会严重影响性能。根据Raid卡使用指导书,Raid卡的工作温度在5℃~45℃。
磁盘
硬盘性能的影响因素有很多,硬盘性能与硬盘本身的固有性能之外以及硬盘设置和环境因素相关。
硬盘基本特性
- 硬盘型号:硬盘的型号是否在兼容性配置范围内
- 硬盘固件版本:硬盘固件是否属于正常发布版本,是否存在已知问题
- 硬盘SMART健康状态:是否有坏块,是否有高温告警,是否有不可恢复读写错误计数统计的上升等
- 机械硬盘性能内圈和外圈差异大,外圈性能优于内圈
硬盘设置
- SSD的状态:需要检查当前SSD是否有很多的垃圾需要回收,磁盘空间利用率是否很高,SSD性能测试前需要进行全盘Erase操作,保证无垃圾
- SSD的性能标准测试方法是长时间取稳定段的性能数据,短期测试的数据与实际宣称值可能有一定差距
- 硬盘会定期进行Backgroud Media scan对性能有一定的影响,可以通过收集smart信息获取到当前是否处于BMS状态
- 如果反复查询硬盘相关信息,对硬盘性能有一定影响
- 硬盘Cache:是否开启写Cache,追求性能的场景下,可以开启硬盘的Cache,针对2308和3008等无Cache的RAID控制器,RAID创建后默认情况下都是关闭硬盘Cache的。在需要高读写性能的情况下,建议打开硬盘的读写cache。
- 硬盘是否进入节能状态:硬盘在无IO访问时进入节能状态,从节能状态唤醒时会导致IO等待时间变长,在需要稳定性能场景下,建议关闭硬盘的节能状态。
环境因素
- 硬盘拉手条:拉手条是否正确安装,特别是机械硬盘,拉手条会影响磁盘的震动继而影响硬盘的读写性能
- 硬盘温度:硬盘都具有一个正常工作的温度范围,注意环境温度是否合适
驱动兼容性
操作系统版本、驱动/firmware匹配关系是否符合软硬件兼容性列表
操作系统OS
调度算法
I/O调度算法在各个进程竞争磁盘I/O的时候担当了裁判的角色。它要求请求的次序和时机做最优化的处理,以求得尽可能最好的整体I/O性能。Linux内核2.6开始引入了全新的IO调度子系统。Linux内核提供了CFQ(默认),deadline和noop三种IO调度器。
CFQ(Completely Fair Queuing完全公平的排队)(elevator=cfq):
这是默认算法,对于通用服务器来说通常是最好的选择。它试图均匀地分布对I/O带宽的访问。在多媒体应用,总能保证audio、video及时从磁盘读取数据。但对于其他各类应用表现也很好。每个进程一个queue,每个queue按照上述规则进行merge和sort。进程之间round robin调度,每次执行一个进程的4个请求。可以调queued和quantum来优化。
Deadline(elevator=deadline):
该算法试图把每次请求的延迟降至最低。该算法重排了请求的顺序来提高性能。可以调队列的过期的读写过程,如read_expire和write_expire二个参数来控制多久内一定要读到数据,超时就放弃排序。比较合适小文件。还可以使用打开front_merges来进行合并邻近文件。deadline调度算法通过降低性能而获得更短的等待时间,它使用轮询的调度器,简洁小巧,提供了最小的读取延迟和尚佳的吞吐量,特别适合于读取较多的环境(比如数据库),非SSD卡的数据库应用建议系统设置为该调度算法。
NOOP(elevator=noop):
I/O请求被分配到队列,调度由硬件进行,只有当CPU时钟频率比较有限时进行。NOOP对于I/O不需要CPU调度,对所有的I/O请求都用FIFO队列形式处理,默认认为I/O不会存在性能问题。不过对于复杂一点的应用类型使用这个调度器,用户自己需要规划好。NOOP适用于SSD卡等IO性能较好的硬件设备。
对于OLTP数据库场景,建议配置为deadline。系统默认的磁盘队列数值较小,因为OLTP数据块较小,建议增大该数值,可以缓存更多的小IO,提升磁盘性能。
Linux系统的设置方法:
临时修改调度策略。
xxxxxxxxxx11echo deadline > /sys/block/sd*/queue/scheduler永久生效,在/boot/grub/menu.lst内核启动配置文件中的kernel行(RHEL7/SLES12是/boot/grub2/grub.cfg配置文件linux行)追加:elevator=deadline
动态调整HDD/SSD混合存储的io scheduler。
分辨设备是SSD还是HDD
设备是SSD还是HDD可以通过cat /sys/block/sd
/queue/rotational内容来区分,其中内容为1表示是传统磁盘HDD,如果内容是0则表示SSD 调整
一次性调整好所有符合要求的SSD的io scheduler为deadline,HDD的io scheduler为cfq (需要使用root权限调整)
xxxxxxxxxx11for i in `ls /sys/block/ | grep sd`;do ( if [[ `cat /sys/block/$i/queue/rotational` == 0 ]]; then echo deadline > /sys/block/$i/queue/scheduler;else echo cfq > /sys/block/$i/queue/scheduler;fi );done验证调整是否成功
xxxxxxxxxx11for i in `ls /sys/block/ | grep sd`;do ( echo $i; cat /sys/block/$i/queue/scheduler );done
磁盘队列优化,增大磁盘队列。
xxxxxxxxxx11echo 128 > /sys/block/sd*/device/queue_depthxxxxxxxxxx11echo 1024 > /sys/block/sd*/queue/nr_requests
IO相关的内核参数
/proc/sys/vm/dirty_ratio
这个参数控制文件系统的写缓冲区的大小,单位是百分比,表示系统内存的百分比。表示当写缓存使用到系统内存多少的时候,开始向磁盘写出数据。增大之会使用更多系统内存用于磁盘写缓冲,也可以极大提高系统的写性能。但是,当需要持续、恒定的写入场合时,应该降低其数值。一般启动上缺省是 10 (实际各个版本此参数都不同,线上环境更有不同差异)。
增大的方法:
xxxxxxxxxx11echo ’40’> /proc/sys/vm/dirty_ratio/proc/sys/vm/dirty_background_ratio
这个参数控制文件系统的 pdflush 进程,在何时刷新磁盘,单位是百分比,表示系统内存的百分比。意思是当写缓存使用到系统内存多少的时候, pdflush 开始向磁盘写出数据。增大之会使用更多系统内存用于磁盘写缓冲,也可以极大提高系统的写性能。但是,当需要持续、恒定的写入场合时,应该降低其数值。一般启动上缺省是 5 。
增大的方法:
xxxxxxxxxx11echo ’20’ > /proc/sys/vm/dirty_background_ratio/proc/sys/vm/dirty_writeback_centisecs
这个参数控制内核的脏数据刷新进程 pdflush 的运行间隔,单位是 1/100 秒。缺省数值是 500 ,也就是 5 秒。如果系统是持续地写入动作,那么实际上还是降低这个数值比较好,这样可以把尖峰的写操作削平成多次写操作。
设置方法如下:
xxxxxxxxxx11echo '200' > /proc/sys/vm/dirty_writeback_centisecs如果系统是短期地尖峰式的写操作,并且写入数据不大(几十M/次)且内存有比较多富裕,那么应该增大此数值:
xxxxxxxxxx11echo '1000' > /proc/sys/vm/dirty_writeback_centisecs/proc/sys/vm/dirty_expire_centisecs
这个参数声明Linux内核写缓冲区里面的数据多 旧 了之后, pdflush 进程就开始考虑写到磁盘中去.单位是 1/100 秒.缺省是 3000 ,也就是 30 秒的数据就算旧了,将会刷新磁盘。对于特别重载的写操作来说,这个值适当缩小也是好的,但也不能缩小太多。因为缩小太多也会导致IO提交太快,建议设置为 1500,也就是15秒算旧。
xxxxxxxxxx11echo '1500' > /proc/sys/vm/dirty_expire_centisecs如果系统内存比较大,并且写入模式是间歇式的,并且每次写入的数据不大(比如几十M),可以将这个数值调大。
文件系统参数
为了提高文件系统IO性能,会在挂载文件系统的时候指定“noatime,nodiratime”参数,意味着当访问一个文件和目录的时候,access time都不会更新。
noatime
atime用于记录文件最后一次被读取的时间。默认情况下,文件每次被读取或修改(也需要先读取),系统将更新atime并写入至文件元数据中。由于写操作是很昂贵的,减少不必要的写操作可以提升磁盘性能。使用noatime挂载文件系统,将不对文件的atime进行更新,此时atime就相当于mtime。磁盘性能可以得到0-10%的提升。使用noatime挂载方法:
xxxxxxxxxx11/dev/sdb /mountlocation ext3 defaults,noatime 1 2nobarrier
barrier是保证日志文件系统的WAL (write ahead logging) 一种手段,数据写入磁盘时,理应先写入journal区,再写入数据在磁盘的实际对应位置,磁盘厂商为了加快磁盘写入速度,磁盘都内置cache,数据一般都先写入磁盘的cache。
cache能加快写入速度,但磁盘一般会对cache内缓存数据排序使之最优刷新到磁盘,这样就可能导致要刷新的实际数据和journal顺序错乱。一旦系统崩溃,下次开机时磁盘要参考journal区来恢复,但此时journal记录顺序与数据实际刷新顺序不同就会导致数据反而恢复到不一致了。而barrier 如其名--栅栏,先加一个栅栏,保证journal总是先写入记录,然后对应数据才刷新到磁盘,这种方式保证了系统崩溃后磁盘恢复的正确性,但对写入性能有影响。
在追求极致性能时我们可以使用nobarrier挂载文件系统。设置方法如下:对于ext3、ext4和reiserfs 文件系统可以在mount时指定barrier=0;对于xfs可以指定nobarrier选项。
文件预读
Linux把读模式分为随机读和顺序读两大类,并只对顺序读进行预读。可以通过以下命令查看和修改预读窗口:
blockdev --getra device
blockdev --setra N device
IO访问模型
IO数据收集
- iostat采集方法
- top采集方法
- Sar命令采集内存使用情况
- 使用sysstat系统定时任务采集(最小时间间隔1min)
系统到子模块逐层分析
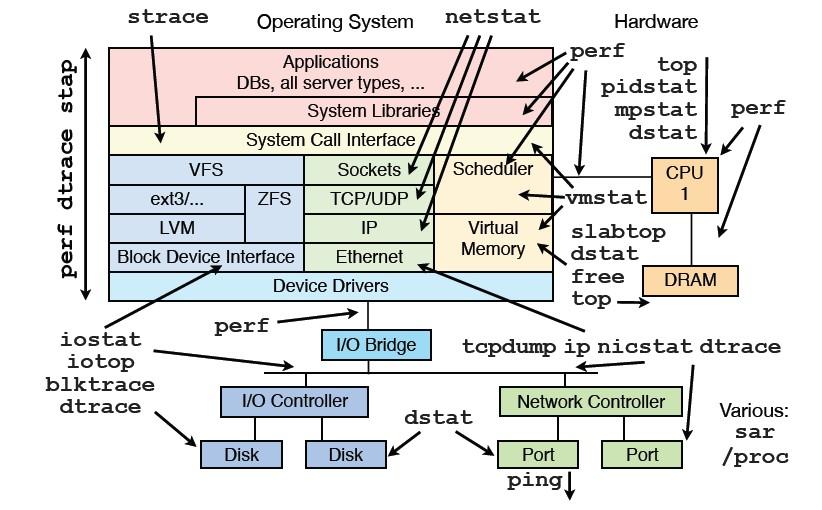
性能问题的定位需要监测、采集、测试和评估,性能监测是问题定位过程中重要的一环。系统是由若干子系统构成,通常一个子系统有可能影响到另一个子系统。所以性能问题的定位需要用到许多监控手段,通常检测的子系统有下面这些:
- CPU
- 内存
- IO
这些子系统互相依赖,了解这些子系统的特性,监测这些子系统的性能数据对问题的定位很有帮助。
工具 |
简单介绍 |
|---|---|
top |
查看进程活动状态以及一些系统状况 |
vmtat |
查看系统状态、硬件和系统信息等 |
iostat |
查看硬盘状况 |
iotop |
查看具体进程的io信息 |
sar |
综合工具,查看系统状况 |
mpstat |
查看多处理器状况 |
其它工具
blktrace工具
blktrace用来收集磁盘IO信息中当IO进行到块设备层(block层,所以叫blktrace)时的详细信息(如IO请求提交,入队,合并,完成等等信息)。通过使用这个工具,使用者可以获取I/O请求队列的各种详细的情况,包括进行读写的进程名称、进程号、执行时间、读写的物理块号、块大小等等,是一个Linux下分析I/O相关内容的很好的工具。
blkktrace工作原理
- blktrace测试的时候,会分配物理机上逻辑cpu个数个线程,并且每一个线程绑定一个逻辑cpu来收集数据;
- blktrace在debugfs挂载的路径(默认是/sys/kernel/debug)下每个线程产生一个文件,后调用ioctl函数产生系统调用将这些东西给内核去调用相应函数来处理,由内核经由debugfs文件系统往此文件描述符写入数据;
- blktrace需要结合blkparse来使用,由blkparse来解析blktrace产生的特定格式的二进制数据;
- blkparse只打开blktrace产生的文件,从文件里面取数据做展示以及最后做per cpu的统计输出。
性能调优
应用程序使用异步文件操作libaio提升系统性能
原理
对于磁盘文件,文件的读取是同步的,导致线程读取文件时,属于阻塞状态。程序为了提升性能和磁盘的吞吐,程序会创建几个单独的磁盘读写线程,并通过信号量等机制进行线程间通信(同时带有锁);显然线程多,锁多,会导致更多的资源抢占,从而导致系统整体性能下降。
libaio提供了磁盘文件读写的异步机制,使得文件读写不用阻塞,结合epoll机制,实现一个线程可以无阻塞的运行,同时处理多个文件读写请求,提升服务器整体性能。
操作系统调优
- 调整脏数据刷新策略,减小磁盘的IO压力
- 调整磁盘文件预读参数
- 优化磁盘IO调度方式
调整脏数据刷新策略,减小磁盘的IO压力
原理
PageCache中需要回写到磁盘的数据为脏数据。在应用程序通知系统保存脏数据时,应用可以选择直接将数据写入磁盘(O_DIRECT),或者先写到PageCache(非O_DIRECT模式) 。非O_DIRECT模式,对于缓存在PageCache中的数据的操作,都在内存中进行,减少了对磁盘的操作。
修改方式
系统中提供了以下参数来调整策略:
/proc/sys/vm/dirty_expire_centisecs此参数用于表示脏数据在缓存中允许保留的时长,即时间到后需要被写入到磁盘中。此参数的默认值为30s(3000 个1/100秒)。如果业务的数据是连续性的写,可以适当调小此参数,这样可以避免IO集中,导致突发的IO等待。可以通过echo命令修改:
# echo 2000 > /proc/sys/vm/dirty_expire_centisecs
/proc/sys/vm/dirty_background_ratio 脏页面占用总内存最大的比例(以memfree+Cached-Mapped为基准),超过这个值,pdflush线程会刷新脏页面到磁盘。增加这个值,系统会分配更多的内存用于写缓冲,因而可以提升写磁盘性能。但对于磁盘写入操作为主的的业务,可以调小这个值,避免数据积压太多最后成为瓶颈,可以结合业务并通过观察await的时间波动范围来识别。此值的默认值是10,可以通过echo来调整:
echo 8 > /proc/sys/vm/dirty_background_ratio
/proc/sys/vm/dirty_ratio 为脏页面占用总内存最大的比例,超过这个值,系统不会新增加脏页面,文件读写也变为同步模式。文件读写变为同步模式后,应用程序的文件读写操作的阻塞时间变长,会导致系统性能变慢。此参数的默认值为40,对于写入为主的业务,可以增加此参数,避免磁盘过早的进入到同步写状态。
 说明:
说明:如果加大了脏数据的缓存大小和时间,在意外断电情况下,丢失数据的概率会变多。因此对于需要立即存盘的数据,应用应该采用O_DIRECT模式避免关键数据的丢失。
调整磁盘文件预读参数
原理
文件预取的原理,就是根据局部性原理,在读取数据时,会多读一定量的相邻数据缓存到内存。如果预读的数据是后续会使用的数据,那么系统性能会提升,如果后续不使用,就浪费了磁盘带宽。在磁盘顺序读的场景下,调大预取值效果会尤其明显。
修改方式
文件预取参数由文件read_ahead_kb指定,CentOS中为“/sys/block/$DEVICE-NAME/queue/read_ahead_kb”($DEVICE-NAME为磁盘名称),如果不确定,则通过命令以下命令来查找。
# find / -name read_ahead_kb
此参数的默认值128KB,可使用echo来调整,仍以CentOS为例,将预取值调整为4096KB:
# echo 4096 > /sys/block/$DEVICE-NAME /queue/read_ahead_kb
调整磁盘文件预读参数
原理
文件预取的原理,就是根据局部性原理,在读取数据时,会多读一定量的相邻数据缓存到内存。如果预读的数据是后续会使用的数据,那么系统性能会提升,如果后续不使用,就浪费了磁盘带宽。在磁盘顺序读的场景下,调大预取值效果会尤其明显。
修改方式
文件预取参数由文件read_ahead_kb指定,CentOS中为“/sys/block/$DEVICE-NAME/queue/read_ahead_kb”($DEVICE-NAME为磁盘名称),如果不确定,则通过命令以下命令来查找。
# find / -name read_ahead_kb
此参数的默认值128KB,可使用echo来调整,仍以CentOS为例,将预取值调整为4096KB:
# echo 4096 > /sys/block/$DEVICE-NAME /queue/read_ahead_kb
文件系统
- 文件系统参数优化
- 选用性能更优的文件系统XFS
文件系统参数优化
Linux支持多种文件系统,不同的文件系统性能上也存在着差异,因此如果可以选择,可以选用性能更好的文件系统,比如XFS。在创建文件系统时,又可以通过增加一些参数进行优化。
另外Linux在挂载文件分区时,也可以增加参数来达到性能提升的目的。
磁盘挂载方式优化nobarrier
原理
当前Linux文件系统,基本上采用了日志文件系统,确保在系统出错时,可以通过日志进行恢复,保证文件系统的可靠性。Barrier(栅栏),即先加一个栅栏,保证日志总是先写入,然后对应数据才刷新到磁盘,这种方式保证了系统崩溃后磁盘恢复的正确性,但对写入性能有影响。
服务器如果采用了RAID卡,并且RAID本身有电池,或者采用其它保护方案,那么就可以避免异常断电后日志的丢失,我们就可以关闭这个栅栏,可以达到提高性的目的。
修改方式
假如sda挂载在“/home/disk0”目录下,默认的fstab条目是:
# mount -o nobarrier -o remount /home/disk0
![]() 说明:
说明:
nobarrier参数使得系统在异常断电时无法确保文件系统日志已经写到磁盘介质,因此只适用于使用了带有保护的RAID卡的情况。
选用性能更优的文件系统XFS
原理
XFS是一种高性能的日志文件系统,XFS极具伸缩性,非常健壮,特别擅长处理大文件,同时提供平滑的数据传输。因此如果可以选择,我们可以优先选择XFS文件系统。
XFS文件系统在创建时,可先选择加大文件系统的block,更加适用于大文件的操作场景。
修改方式
格式化磁盘。假设我们要对sda1进行格式化:
# mkfs.xfs /dev/sda1
指定blocksize,默认情况下为4KB(4096B),我们假设在格式化时指定为变更为8192B:
# mkfs.xfs /dev/sda1 -b size=8192
存储
RAID
RAID卡Cache大小
RAID卡Cache设置
磁盘
磁盘Cache设置
磁盘节能开关
测试工具
测试工具
目前进行硬盘性能测试所使用的工具主要有fio、Vdbench、Iometer和Sysbench等,dd有时也被用来测试硬盘性能。但dd工具有很多局限性,测试结果并不能反映硬盘的真实性能,一般不推荐使用dd测试硬盘性能。
fio:目前最常用的性能测试工具,主要是linux下。这个工具是实际测试中使用最频繁的IO测试工具。fio可以用比较小的代价在短时间能生产IO,这个能力的确没有其他工具可以比。
Vdbench:SUN遗留下来的工具,因为基于Java,他的可移植性比fio好,同时支持压缩和dedup的测试,因此也是企业测试的首选。
Iometer:Windows平台为主,具有图像化界面的测试工具,因此脚本化比较困难,在Windows比较流行的时候用的比较多。
Sysbench:可以测试mysql,也可以测试fileio。
性能测试基础知识
在执行硬盘性能测试之前,首先要了解一些硬盘性能测试的基本知识。
线程
指的是同时有多少个读或写任务在并行执行,一般来说,CPU里面的一个核心同一时间只能运行一个线程。如果只有一个核心,要想运行多线程,只能使用时间切片,每个线程跑一段时间片,所有线程轮流使用这个核心。Linux使用Jiffies来代表一秒钟被划分成了多少个时间片,一般来说Jiffies是1000或100,所以时间片就是1毫秒或10毫秒。
同步模式和异步模式
一般主机发送一个读写命令到磁盘只需要几微秒,但是磁盘要花几百微秒甚至几毫秒才能执行完这个命令。如果发一个读写命令,然后线程一直休眠,等待结果回来才唤醒处理结果,这种叫做同步模式。可以想象,同步模式是很浪费系统资源的。
为了提高并行性,大部分情况下读写采用的是异步模式。就是用几微秒发送命令,发完线程不会傻傻的在那里等,而是继续发后面的命令。如果前面的命令执行完了,磁盘会通过中断或者轮询等方式告诉CPU,CPU来调用该命令的回调函数来处理结果。这样的好处是IO效率提升。
队列深度
在异步模式下,CPU不能一直无限的发命令到磁盘。假如磁盘执行读写如果发生了卡顿,那有可能系统还会一直不停的发命令,几千个,甚至几万个,这样一方面底层磁盘扛不住,另一方面这么多命令会很占内存,影响系统的其他应用,这样,就带来一个参数叫做队列深度。举个例子,队列深度64就是说系统发的命令都发到一个大小为64的队列,如果填满了就不能再发。等前面的读写命令执行完了,队列里面空出位置来,才能继续填命令。
SATA队列深度缺省值是32,SAS队列深度缺省值是256。
Direct IO
Linux读写的时候,内核维护了缓存,数据先写到缓存,后面再后台写到SSD。读的时候也优先读缓存里的数据。这样速度可以加快,但是一旦掉电缓存里的数据就没了。所以有一种模式叫做DirectIO,跳过缓存,直接读写SSD。这个是本地测试标配,但是要注意网络I/O可能只支持buffer I/O。
BIO
Linux读写SSD等块设备使用的是BIO,Block-IO,这是个数据结构,包含了数据块的逻辑地址LBA,数据大小和内存地址等。
I/O 引擎
基本上是libaio,测试硬盘带宽,对于延时为主的测试,建议psync。
FIO
fio最初是用来节省为特定负载写专门测试程序,或是进行性能测试,或是找到和重现bug的时间。写这么一个测试应用是非常浪费时间的。因此需要一个工具来模拟给定的io负载,而不用重复的写一个又一个的特定的测试程序。但是test负载很难定义。fio是一个非常灵活的测试Linux I/O子系统的工具,通过多线程或进程模拟各种IO操作。
fio执行
fio的工作方式有两种:根据测试要求写出fio测试命令,直接测试运行;写一个job文件来描述仿真的io负载,fio从文件读这些参数并根据这些参数描述启动这些访真线程/进程。
命令格式
xxxxxxxxxx11fio -name=job1 -rw=randwrite -ioengine=libaio -direct=1 -thread -group_reporting -numjobs=1 -iodepth=64 -filename=/dev/sdb -size=10G -offset=0MB -bs=4k --output TestResult.log下面针对这个命令对fio的各个选项参数进行说明:
-name=job1:一个任务的名字,名字随便起,重复了也没关系。
-rw=randwrite:读写模式,randwrite是随机写测试。
- read:顺序读测试,使用方式-rw=read
- write:顺序写测试,使用方式-rw=write
- randread:随机读测试,使用方式-rw=randread
- randwrite:随机写测试,使用方式-rw=randwrite
- randrw:随机读写,-rw=randrw;默认比率为5:5,通过参数-rwmixread设定读的比率,如-rw=randrw -rwmixread=70,说明读写比率为70:30。或设定写的比率rwmixwrite。
-ioengine=libaio:采用的文件读写方式,libaio指的是异步模式。
- sync:采用read,write,使用fseek定位读写位置。
- psync:采用pread、pwrite进行文件读写操作
- libaio:Linux异步读写IO
- posixaio: glibc POSIX 异步IO读写,使用aio_read(3)and aio_write(3)实现IO读写
- mmap:直接内存映射方式
-direct=1:当前测试是否使用直接I/O方式进行读写,值为1表示使用direct IO。采用直接I/O方式进行写测试,会使得测试结构更加真实。
-thread:使用pthread_create创建线程,另一种是fork创建进程。进程的开销比线程要大,一般都采用thread测试。
-group_reporting:关于显示结果的,汇总每个进程的信息。
-numjobs=1:测试进程的并发数,每个job是1个线程,这里用了几个进程,后面每个用-name指定的任务就开几个线程测试。
-iodepth=64:队列深度,即一次下发的IO的个数。这里队列深度为64。
-filename=/dev/sdb:待测试的文件或块设备。这里可以是一个文件名,也可以是分区或者SSD。也可以写多个文件,如--filename=/dev/sda:/dev/sdb
- 若为文件,则代表测试文件系统的性能;例:-filename=/work/fstest/fio.img
- 若为块设备,则代表测试裸设备的性能;例:-filename=/dev/sdb
-size=10G:每个线程写入数据量是10GB,不指定size时会进行全盘读写,指定size时限定读写范围,一把情况下指定size的性能会更好。
-offset=0MB:从偏移地址0MB开始写。
-bs=4k:每一个BIO命令包含的数据大小是4KB。一般4KB IOPS测试,就是在这里设置。
-output TestResult.log:日志输出到TestResult.log。
测试结果
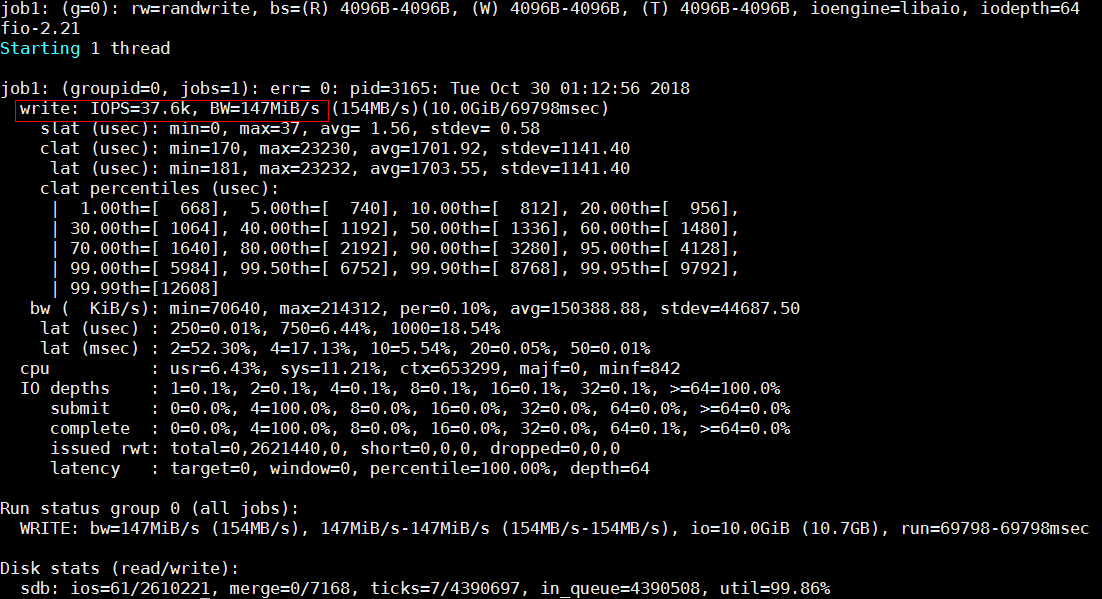
fio性能测试注意点
- 测试机械硬盘时,一般设置线程数为1,即numjobs=1,iodepth=32。特别是测试顺序读写性能的时候,多个线程会导致顺序IO变成随机IO,性能变差。
- 测试文件系统系统性能的时候,需要先用顺序的大块IO将磁盘写一遍,然后再测试文件系统性能。
- 测试文件系统时,先测试顺序,再测随机。
- SSD硬盘测试需要绑核,taskset -c 1-4 fio …。
- 测试过程中需要使用iostat观测硬盘实时性能,fio显示的数据不准确。
- 测试NVME时,如果硬盘背板存在PCIe Switch,需要注意NVME盘的插法,按照最佳插法配置。
- 测试磁盘性能时,如果服务器散热较差,需要提高风扇转速,机械硬盘50度就开始降性能了,raid卡温度过高也会影响性能。
- 需要保证使用的工具版本是一样的,不同版本的测试工具有性能差异。
Vdbench
Vdbench是一款由SUN公司的Henk Vandenbergh开发的存储产品基准测试工具。它既可以测试裸盘的性能和数据一致性,也可以测试文件系统的性能和数据一致性,除此以为还提供了一些非常实用的数据后处理功能。Vdbench工具采用java语言编写,所以能够跨平台使用该工具,因此使用该工具前必须要安装java,即配置JDK。
Vdbench安装和验证
Vdbench被打包成两种格式的文件,一种是tar文件,另一种是zip文件。其中任意一种文件解压之后都可以直接用于Solaris,Windows和Linux等平台。以Linux系统为例,下面介绍如何安装vdbench。提示,jdk可以直接使用oracle官方提供的jdk安装包及vdbench。
上传vdbench安装包。将vdbench50406.zip文件拷贝到/home目录下,然后输入“unzip vdbench50406.zip”命令进行解压,这样/home目录下就有vdbench包。
要运行该工具,需要安装Java运行时环境,本例中安装Oracle JDK,将Java软件包jdk-8u172-linux-x86.rpm上传到服务器,然后进行安装。
xxxxxxxxxx71[root@localhost ~]# rpm -ivh jdk-8u172-linux-x86.rpm //安装java软件包2[root@localhost ~]# vi .bashrc //编辑配置文件,添加以下内容3JAVA_HOME=/usr/java/jdk1.8.0_172-amd644CLASSPATH=.:$JAVA_HOME/lib/tools.jar5PATH=$JAVA_HOME/bin:$PATH6export JAVA_HOME CLASSPATH PATH7[root@localhost ~]# source .bashrc //使环境变量生效启动测试之前,使用默认的参数检查安装是否成功。
[root@localhost vdbench50406]# ./vdbench -t
上述命令正常运行,则vdbench工具安装成功。
更多测试说明请参考https://blog.csdn.net/u012114090/article/details/81626430
文件系统损坏类问题
整机掉电、存储断链和系统panic是常见且不可避免的三种异常场景。需要考虑文件系统的元数据、数据是否会因此损坏。针对EXT4文件系统,能够保证文件系统的一致性,但无法保证正在修改的文件数据一致。
JBD2日志
在掉电、panic等异常场景下,导致文件系统损坏的根本原因在于写文件不是原子操作,因为写文件涉及的不仅仅是用户数据,还涉及元数据(metadata)包括 Superblock、inode bitmap、inode、data block bitmap等,所以写操作无法一步完成,如果其中任何一个步骤被打断,就会造成数据的不一致或损坏。Linux 中的日志块设备(JBD)可以解决这个问题。
日志文件系统(EXT4/xfs等),在进行写操作之前,把即将进行的各个步骤(称为transaction)事先记录下来,保存在文件系统上单独开辟的一块空间上,这就是所谓的日志。日志保存成功之后才进行真正的写操作、把文件系统的元数据和用户数据写进硬盘(称为checkpoint)。
这样万一写操作的过程中掉电,下次挂载文件系统之前把保存好的日志重新执行一遍就行了(术语叫做replay),避免了前述的数据损坏场景。EXT4文件系统的日志叫做JBD2。
JBD2格式
EXT4文件系统,专门在磁盘上划了一块区域,用于存放journal日志。JBD2日志里面有文件系统的metadata。日志格式如下:

如上图, 每一条日志都有descriptor block 和 commit block两个块,表示一条日志的开始和结束。
其中,descriptor block还记录了实际磁盘块与日志块的对应关系。在descriptor block和commit block中间,就是元数据日志。
三种日志处理模式
EXT4有三种日志处理模式:
journal
data=journal模式提供了完全的数据块和元数据快的日志,所有的数据都会被先写入到日志里,然后再写入磁盘(掉电非易失存储介质)上。在文件系统崩溃的时候,日志就可以进行reply,把数据和元数据带回到一个一致性的状态,journal模式性能是三种模式中最低的,因为所有的数据都需要日志来记录。
ordered(*)
在data=ordered模式下,ext4文件系统只提供元数据的日志,但它逻辑上将与数据更改相关的元数据信息与数据块分组到一个称为事务的单元中。当需要把元数据写入到磁盘上的时候,与元数据关联的数据块会首先写入。也就是数据先落盘,再做元数据的日志。一般情况下,这种模式的性能会略逊色于 writeback 但是比 journal 模式要快的多。
writeback
在data=writeback模式下,当元数据提交到日志后,data可以直接被提交到磁盘。即会做元数据日志,数据不做日志,并且不保证数据比元数据先落盘。writeback是ext4提供的性能最好的模式。
备注**:数据,日志,元数据这三部分内容的落盘顺序是保证文件系统可靠性的生命。**
JBD2保护文件系统完整性的原理
ordered模式下,只记录metadata的journal日志。落盘顺序为: data --> metadata journal --> metadata。
系统掉电或者panic,OS缓存丢失,可能导致文件元数据、数据没有落到实际的磁盘区域内。重启后,挂载磁盘时,系统会将JBD2日志区里面的元数据,反刷到对应磁盘区域(JBD2日志重演)。所以,只要日志数据正确,就能保证ext4文件系统格式不被破坏。(文件的数据部分无法保证)
掉电时,JBD2日志也有可能没有落盘,或者落了一半:
- JBD2日志没有落盘:由于ordered模式下,journal metadata先于metadata落盘,所以此时metadata也没有更新,并不影响文件系统完整性。
- JBD2日志落了一部分:descriptor block 和 commit block两个块必须都存在,才会作为一条有效记录。如果没有commit,则该记录废弃。
- 一个JBD2事务作为一个原子操作,此时即使丢失整条日志,并不影响文件系统完整性。
EX barrier机制
有了JBD2日志机制后,仍然存在问题。做了文件写操作后,大多数情况下调用fsync就能保证数据可靠地写入磁盘。但是由于磁盘缓存的存在,fsync这些同步操作,并不能完全保证存储设备把数据写入非易失性介质。如果此时存储设备发生掉电或者硬件错误,此时存储缓存中的数据将会丢失。
对于像日志文件系统中日志这样的数据丢失,其后果可能是非常严重的。因为数据的写入和日志的写入存在先后顺序, 日志记录也存在顺序。而IO落到磁盘缓存后,操作系统将无法再控制数据的落盘顺序。 如果数据从磁盘缓存刷入非易失性介质的过程中发生掉电,所有IO的落盘顺序将无法保证。
举例:
JBD2 descriptor block 和 commit block落盘,而实际JBD2的metedata journal没有落盘,则这部分数据变为脏数据,会大面积破坏文件系统。
为了规避这种情况,barrier应运而生。
Barrier 的原理:barrier之前的I/O需要在其之前写入存储介质,之后的I/O需要等到barrier写入完成后才能得到执行。磁盘数据将在barrier被写入之前完全写入磁盘。借用barrier机制,EXT4能够保证磁盘缓存中的数据能够及时落盘。
barrier在EXT4文件系统中默认启用。在/proc/mounts文件中可以看到barrier的状态是否启用:barrier=1。
RAID控制卡或者磁盘需要上报存在磁盘cache, 否则barrier不生效。(之前出过磁盘有cache,但是RAID控制卡没有cache,导致barrier不生效问题)。
另外虚拟化场景下,I层需要支持flush刷新,能够将缓存(host或者存储缓存)中的内容刷到实际存储设备中。
fsck修复
万一出现了文件系统损坏,需要用到fsck来检测并修复文件系统中的错误。
fsck基本用法
–n:Open the filesystem read-only, and assume an answer of `no' to all questions.
不会对文件系统做任何修改,仅检查。
–a:This option will cause e2fsck to automatically fixany filesystem problems that can be safely fixed without human intervention.
不需要人机交互,仅修复一些不会导致文件丢失、数据损坏的问题,可以理解为安全模式。
–y:Assume an answer of `yes' to all questions. allows e2fsck to be used non-interactively.
自动修复所有问题。
–f:Force checking even if the file system seems clean.
强制进行全盘扫描。
一般情况下,如果怀疑存在文件系统损坏,并想尝试修复,请按以下步骤执行:
执行”fsck –nf [磁盘绝对路径]” 进行检查,确认损坏情况。
如果磁盘不是很大,建议dd进行备份。
执行“fsck –a [磁盘绝对路径]”, 尝试安全修复。
如果上一步无法修复磁盘,只能尝试强制修复“fsck –y [磁盘绝对路径]”。 需要注意的是,-y修复,可能会删除文件。
即便修复成功,后续仍然有可能因为文件丢失或者内容错误,导致业务异常。
![]() *注意:*
*注意:*
产品自己进行的fsck修复动作,请务必保留修复的过程信息,便于后续定位。
启动阶段修复配置
系统在启动阶段,会根据/etc/fstab配置,由systemd自动挂载。根据具体配置,选择是否执行fsck命令进行磁盘修复。
该阶段,执行的修复动作,选择的修复方式取决于cmdline(/proc/cmdline)配置。
fsck.mode
=auto : 自动模式(默认)
=force:即-f全盘扫描 (耗时较长,影响启动时间)
=skip:不执行fsck
fsck.repair
=preen:即-a安全修复
=yes:即-y全部修复
=no:即-n,只检查
损坏场景示例
系统异常掉电或crash时,文件末尾概率出现乱码
- 问题描述
系统异常掉电或crash时,文件末尾概率出现乱码。
- 原因分析
EXT4文件系统为了提升落盘性能,首先更新文件元数据的文件长度字段,长度字段落盘后,文件数据再落盘。因此,长度字段更新后,如果发生掉电或者crash时,文件数据尚未落盘,文件末尾就会出现乱码。
- 解决方法
出现乱码是正常的实现机制,要保证文件落盘,需要在掉电前及时执行sync。如果系统异常掉电出现该问题,只能手工修复乱码。另外可以修改mount中的模式为可靠性模式:
性能模式:文件长度字段先落盘,文件数据后落盘。
可靠性模式:文件数据先落盘,长度字段后落盘。
$bash: mount /dev/sdb -o nospeed mnt
修改cmdline参数,在启动参数中增加 “ext4.speed=0”。
![]() 说明:
说明:
- 可靠性模式能够保障文件的可靠性,与性能模式相比,有少许性能损失,请用户根据需求场景选择对应的模式。
- Mount参数与cmdline参数同时配置时,以cmdline参数为准,即全局生效。
- 对于重要的文件,或者有文件格式要求的文件, 写完之后及时的fsync就可以保证此场景下文件数据完整性。
IO部分落盘,文件数据损坏
- 问题描述
存储断链后,部分文件数据错误。
- 原因分析
更新一个文件,按照落盘顺序分为: 数据àJBD2日志à元数据。
需要说明的是,日志和元数据下发会等数据IO流程结束, 但是并没有要求数据IO一定下发成功。
IO闪断情况下,可能存在以下场景:
数据下发失败, 日志和元数据下发成功,从而表现出文件内容损坏的现象。
- 解决办法
mount磁盘时,指定data_err=abort, 保证在数据IO下发失败时,不再进行后续日志和元数据更新。
磁盘cache打开,掉电后文件系统损坏
- 问题描述
物理机,开启磁盘cache,并且没有开barrier:整机下电后,出现文件系统损坏、数据损坏等现象。
- 原因分析
barrier关闭的情况下, 操作系统层面,按照数据、日志、元数据顺序下发,只能保证这部分数据按顺序下发到raid 卡cache或者磁盘cache , 并不保证落入磁盘。
而raid cache和磁盘cache,从经验来看,并没有保证先进先落盘,掉电的时候,任何IO均可能丢失。
这种情况下,可能出现各种损坏现象:
静态配置文件被删除
文件名称和属性显示”??”
文件数据损坏
………
barrier打开的情况下,下发完数据,日志和元数据后,分别会通知RAID控制卡和cache强制flush,从而保证顺序。
barrier=on是默认模式,但是需要关注存在不生效的情况,如下图所示:

磁盘初始化时,如果上报“Write cache: disabled”,则barrier不生效。比如RAID 3416, 不带保电功能,RAID控制卡无cache,但是磁盘有cache。
- 解决方法
- 替换为具备保电能力的SSD卡或者更换保电RAID。
- 关闭磁盘cache,避免异常掉电cache中的IO丢失。
附录
本文出现的专业术语,可通过https://www.google.com/search?q=关键字进行搜索